TWC #12

State-of-the-art (SOTA) updates for 17 Oct– 23 Oct 2022
TasksWithCode weekly newsletter highlights the work of SOTA researchers. Researchers in figure above produced state-of-the-art work breaking existing records on benchmarks. They also
- authored their paper
- released their code
- released models in most cases
- released notebooks/apps in few cases
The selected researchers broke existing records on the following tasks
- Link Prediction
- Action Recognition
- Open Vocabulary Object Detection
- Interactive segmentation
- Learning with noisy labels
This weekly is a consolidation of daily twitter posts tracking SOTA researchers.
To date, 27.25% (88,947) of total papers (326,438) published have code released along with the papers (source), averaging ~6 SOTA papers with code in a week.
SOTA details below are snapshots of SOTA models at the time of publishing this newsletter. SOTA details in the link provided below the snapshots would most likely be different from the snapshot over time as new SOTA models emerge.
#1 in Link Prediction on WN18RR dataset
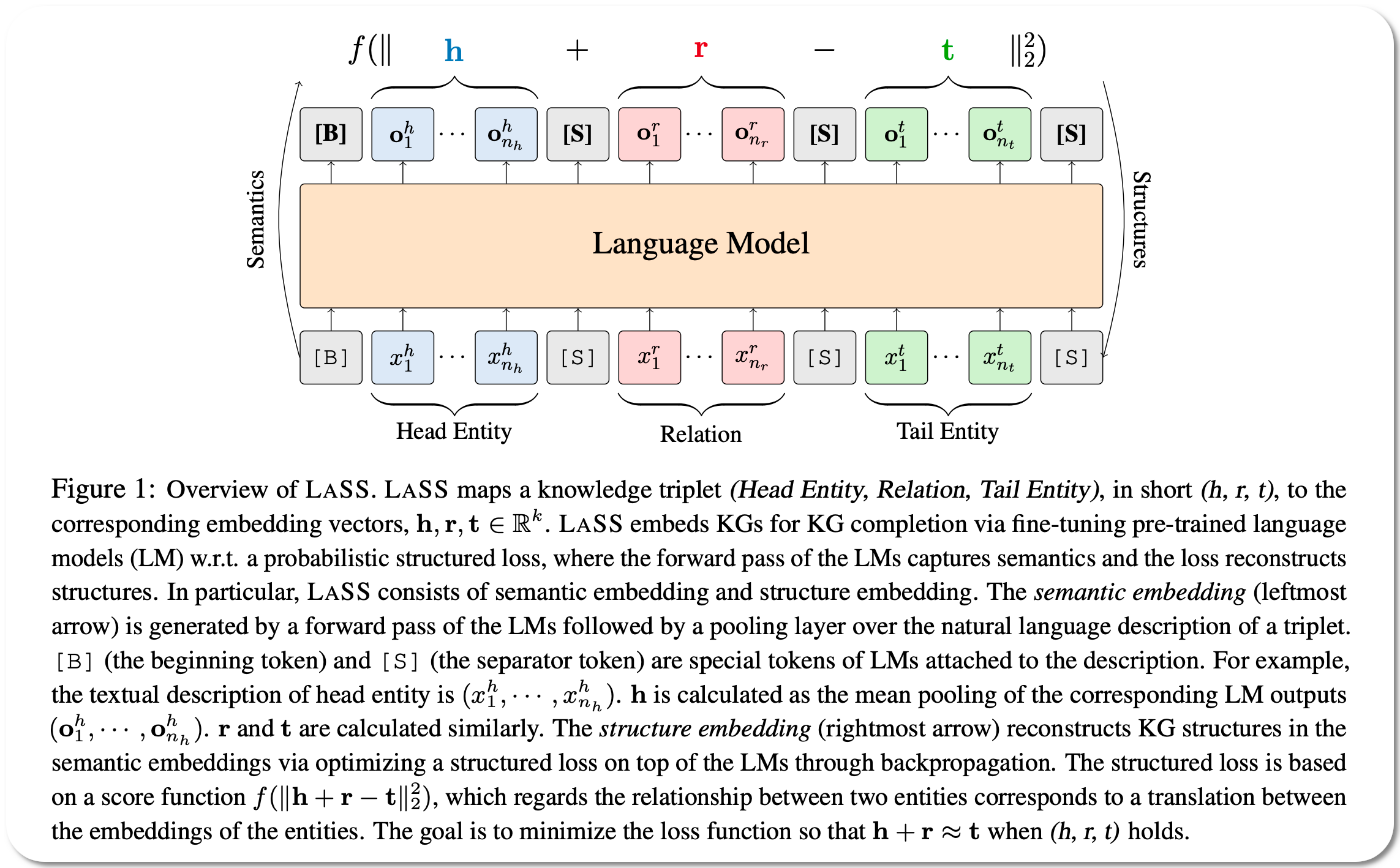
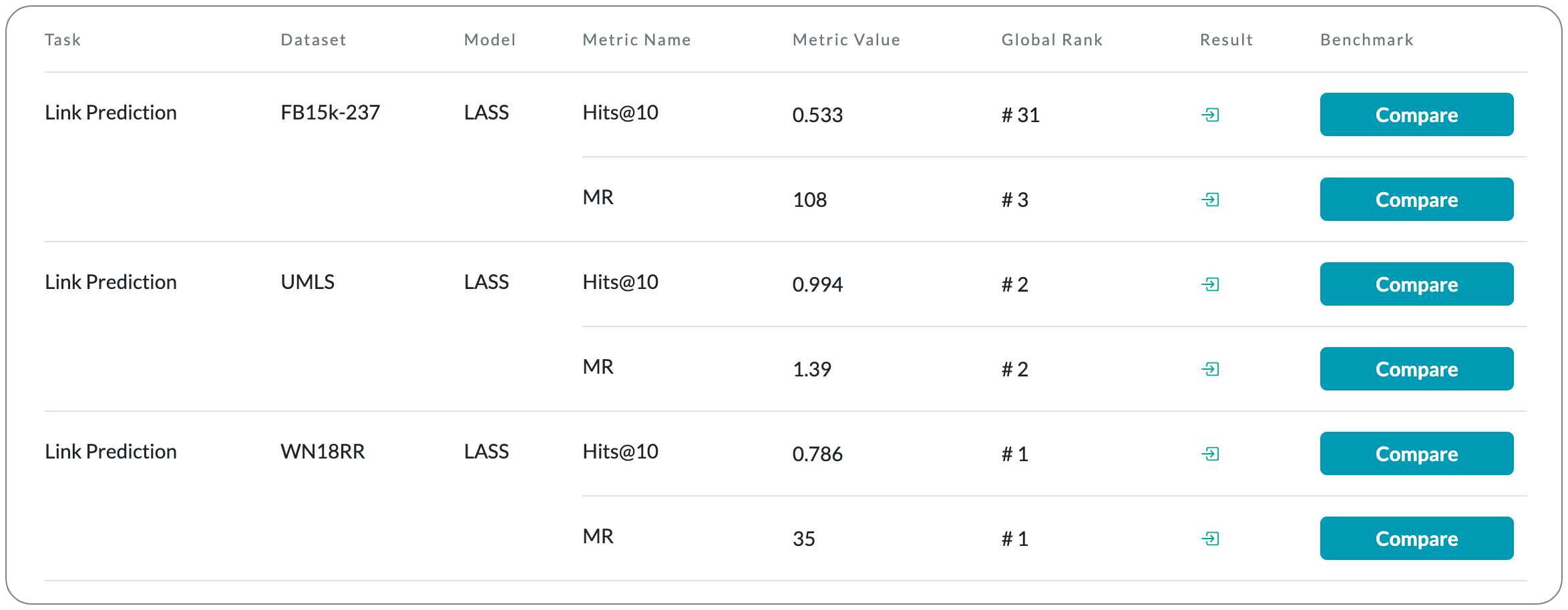

Model Name: LASS
Notes: This paper proposes to jointly embed the semantics in the natural language description of the knowledge triplets with their structure information. They embed knowledge graphs for the completion task via fine-tuning pre-trained language models with respect to a probabilistic structured loss, where the forward pass of the language models captures semantics and the loss reconstructs structures. This method is claimed to significantly improve the performance in a low-resource regime, thanks to the better use of semantics.
License: Not specified to date
#1 in Action recognition on AVA family dataset
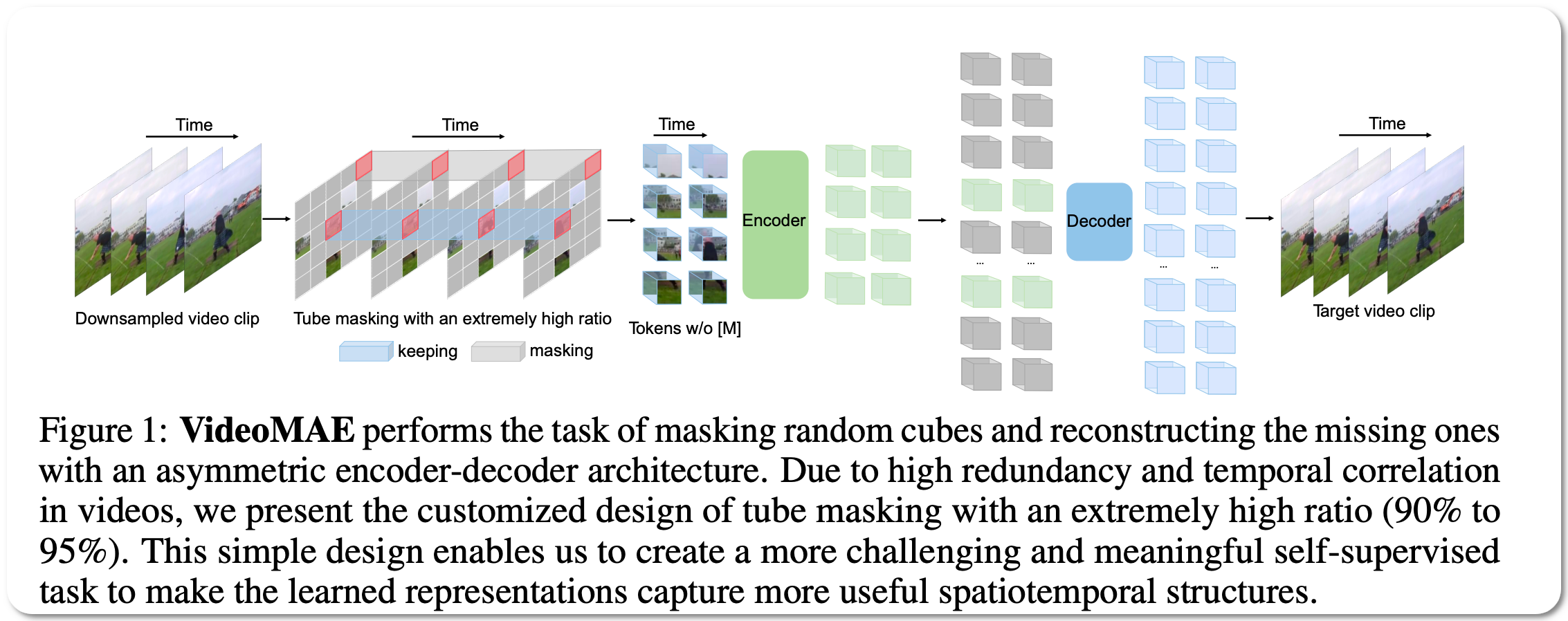
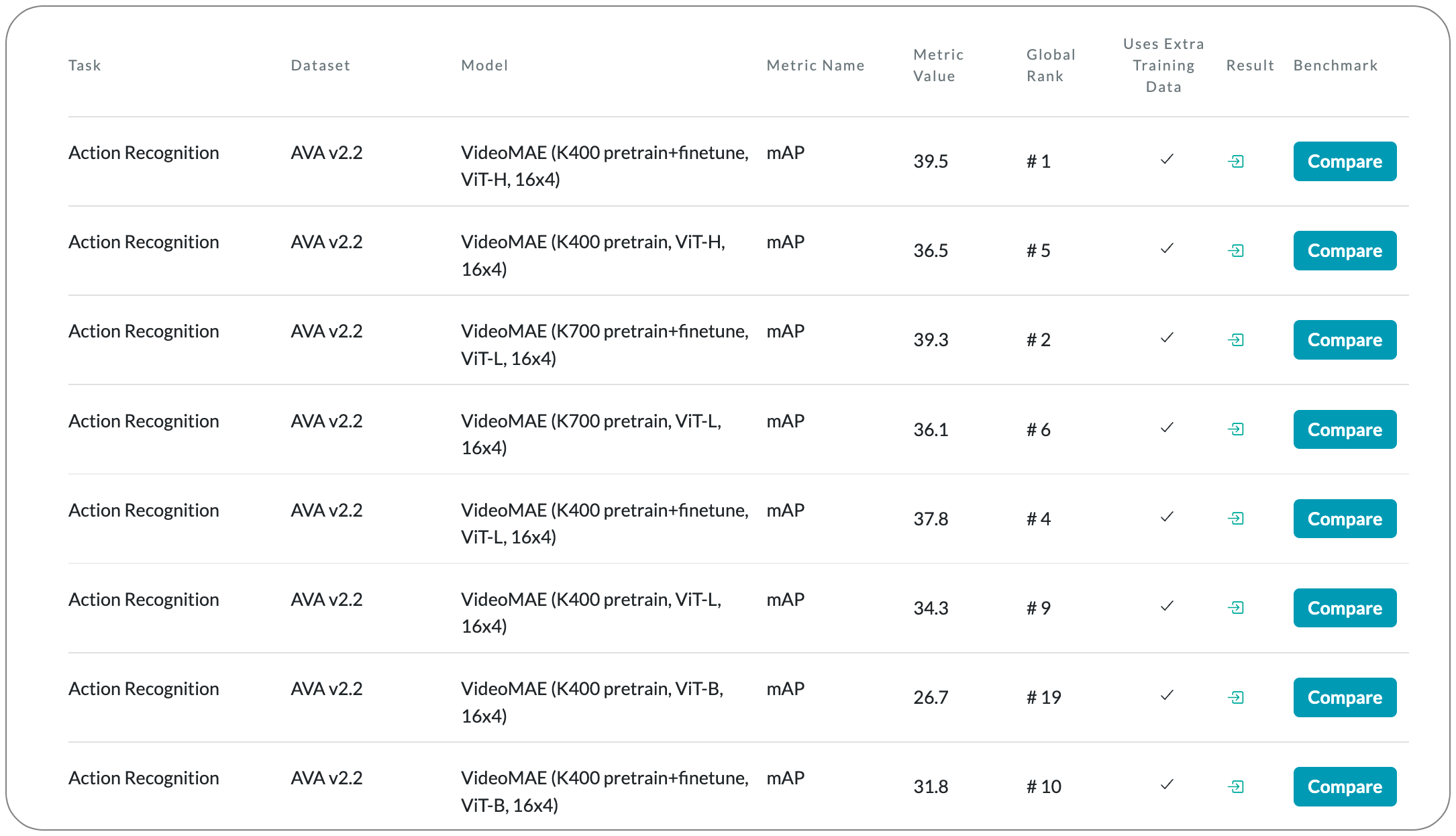
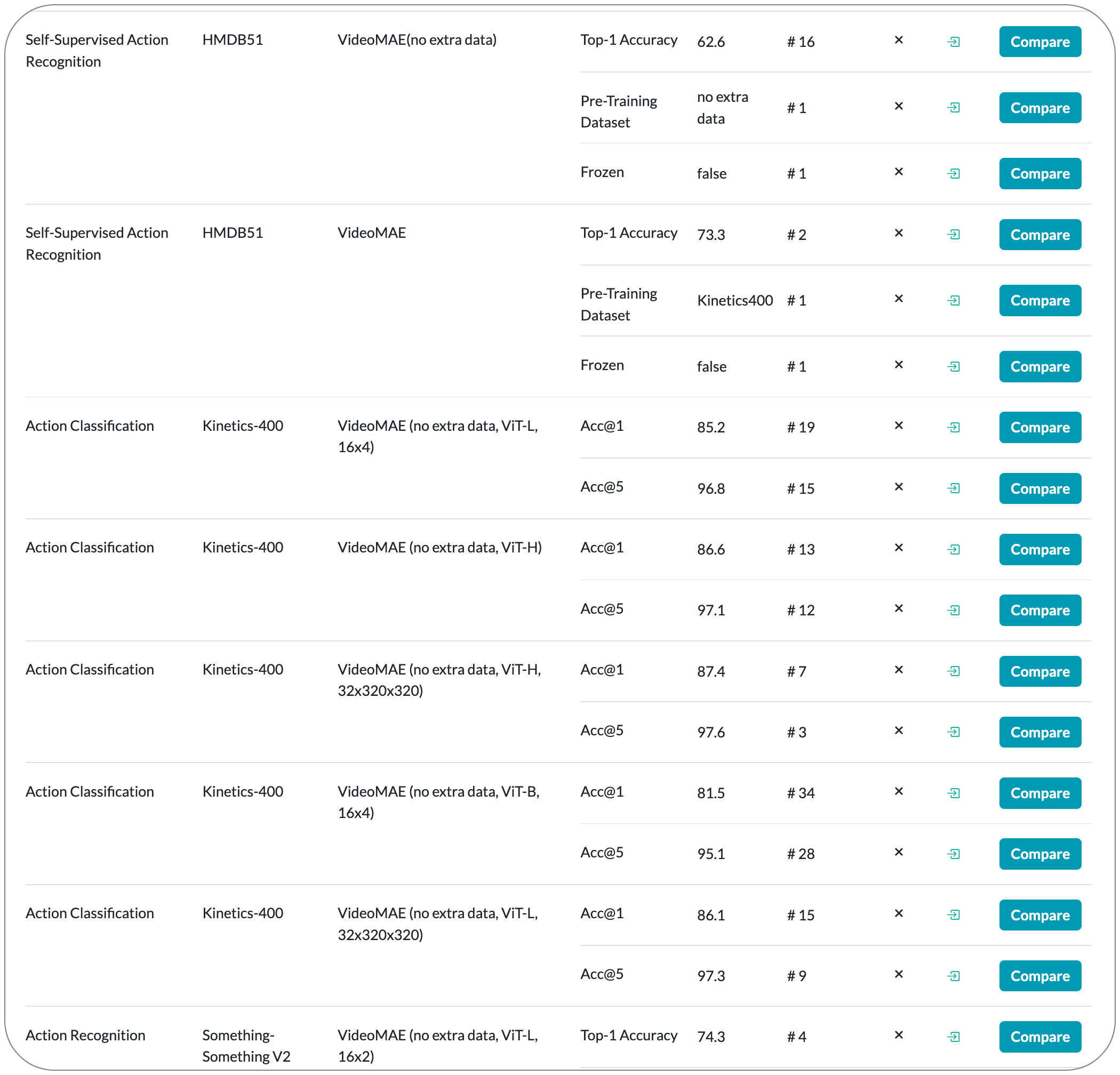
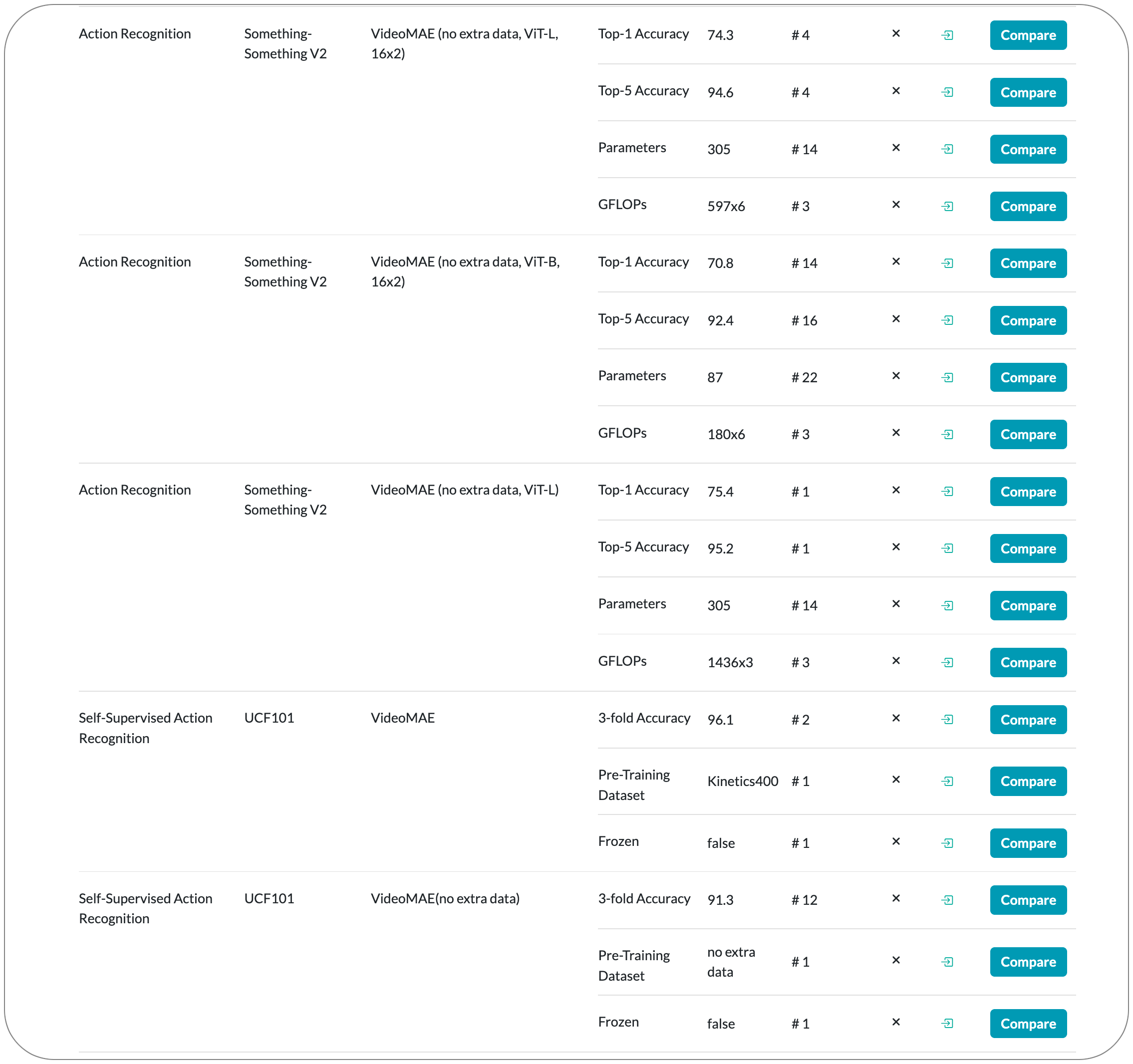

Model Name: VideoMAE (K400 pretrain+finetune, ViT-H, 16x4). The first version of this model VideoMAE was released back in April 2022. The SOTA details above is based on an updated version of this model released on 20 October 2022.
Notes: This paper demonstrates that video masked autoencoders (VideoMAE) are data-efficient learners for self-supervised video pre-training (SSVP). This work is inspired by the recent ImageMAE and proposes customized video tube masking with an extremely high ratio. This approach makes video reconstruction a more challenging self-supervision task, thus encouraging extracting more effective video representations during this pre-training process. They obtain three important findings on SSVP: (1) An extremely high proportion of masking ratio (i.e., 90% to 95%) still yields favorable performance of VideoMAE. The temporally redundant video content enables a higher masking ratio than that of images. (2) VideoMAE achieves impressive results on very small datasets (i.e., around 3k-4k videos) without using any extra data. (3) VideoMAE shows that data quality is more important than data quantity for SSVP
Demo page: None to date. Github page says Colab notebook coming soon. There is a script for visualization on the Github page
License: Creative Commons License CC-BY-NC 4.0.
#1 in Open Vocabulary Object Detection on MSCOCO dataset
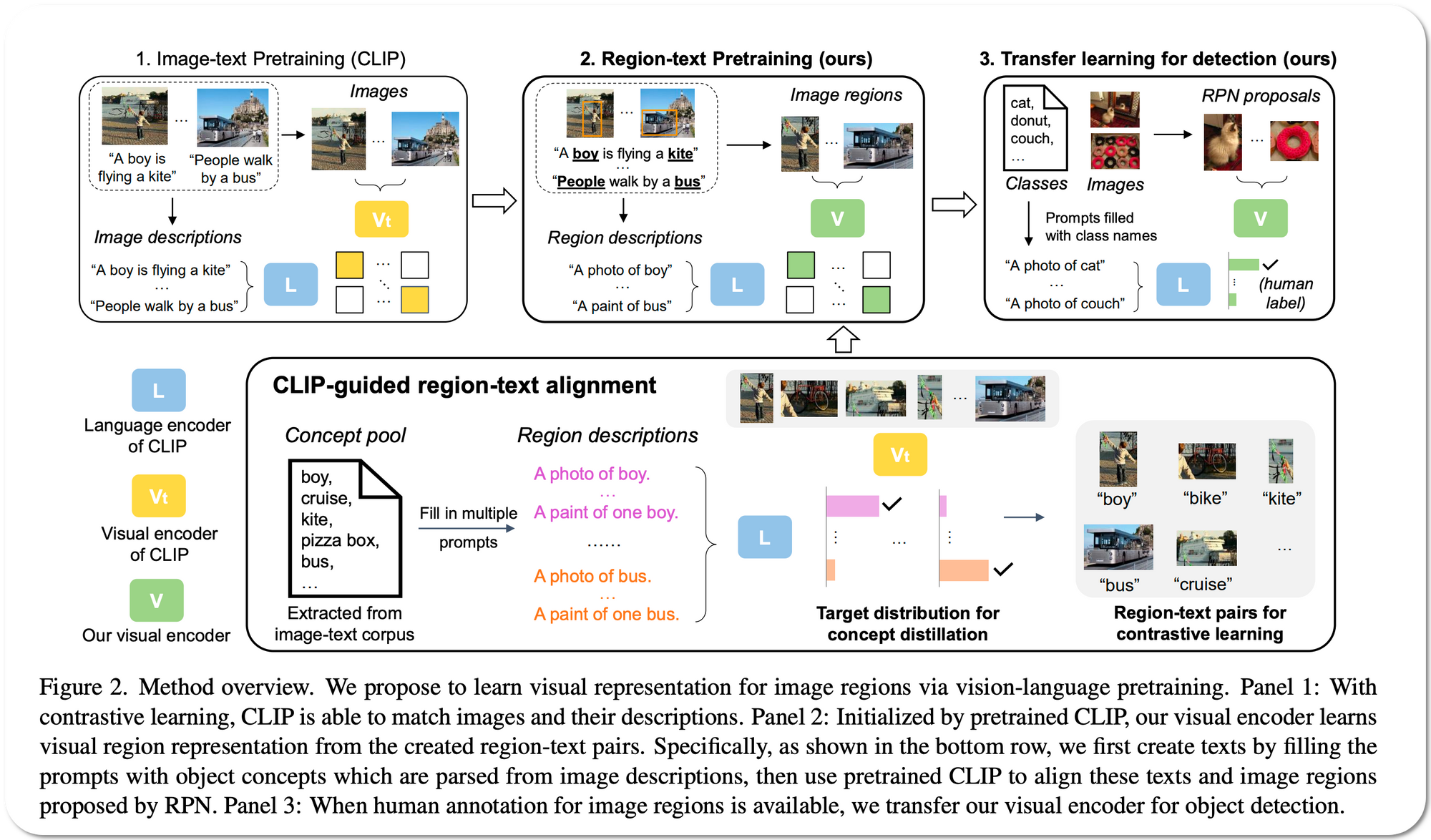
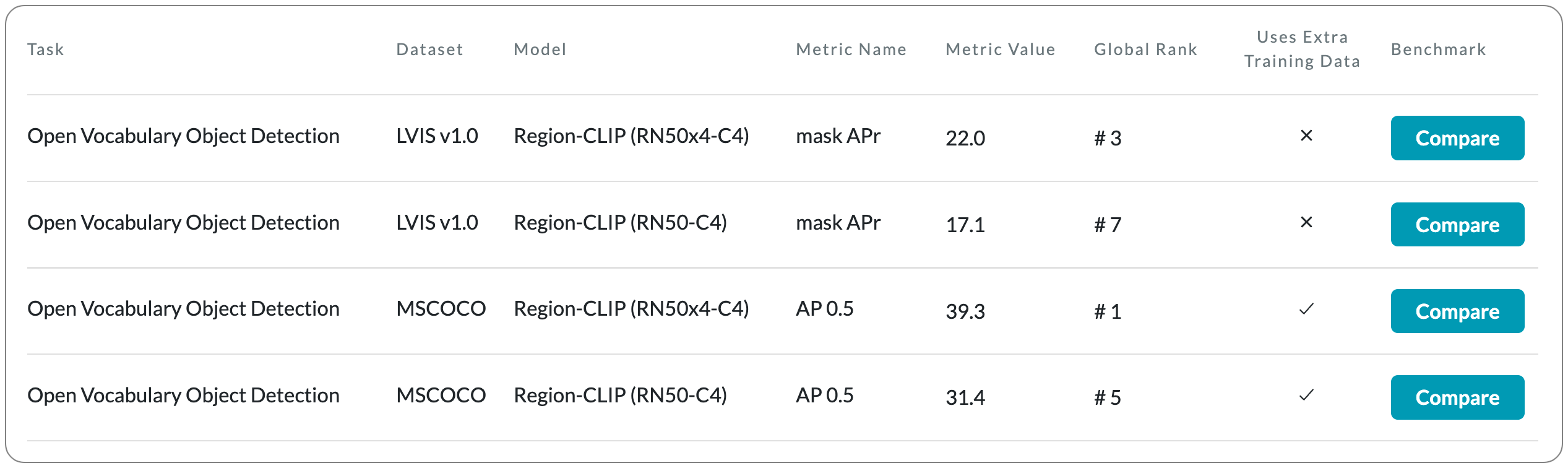

Model Name: Region-CLIP (RN50x4-C4). The first version of this model RegionClip was released back in June 2022. The SOTA details above reflects an updated version of this model released in October 2022.
Notes: Contrastive language-image pretraining (CLIP) using image-text pairs has achieved impressive results on image classification in both zero-shot and transfer learning settings. However, directly applying such models to recognize image regions for object detection leads to poor performance due to a domain shift: CLIP was trained to match an image as a whole to a text description, without capturing the fine-grained alignment between image regions and text spans. To mitigate this issue, this paper proposes a new method called RegionCLIP that extends CLIP to learn region-level visual representations, thus enabling fine-grained alignment between image regions and textual concepts. The described method leverages a CLIP model to match image regions (regions detected by a RPN - region proposal networks ) with template captions and then pretrains a new model to align these region-text pairs in the feature space.
Demo page: HuggingFace space demo page
The examples shown in the demo page suggest the model performs quite well for detecting object instances that are unique in an input. For instance, the model is able to text and symbolic logos of companies (e.g Facebook, apple logo etc.). However, it struggles even with input hints when there are multiple instances of an object in a page. For instance, in an image with multiple red apples, the model only picks one of them regardless of the text hint of the apple being on the right/left etc.
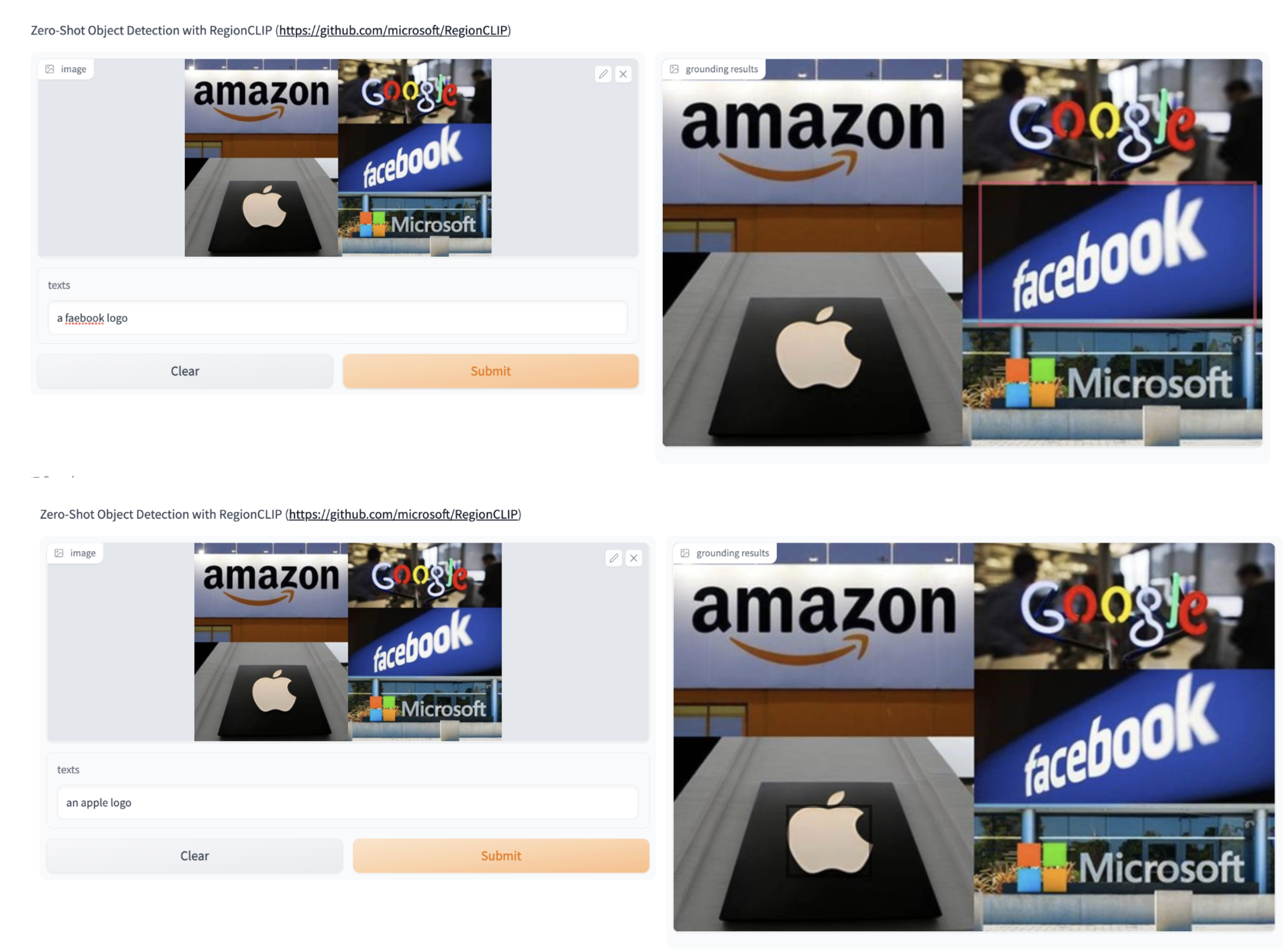
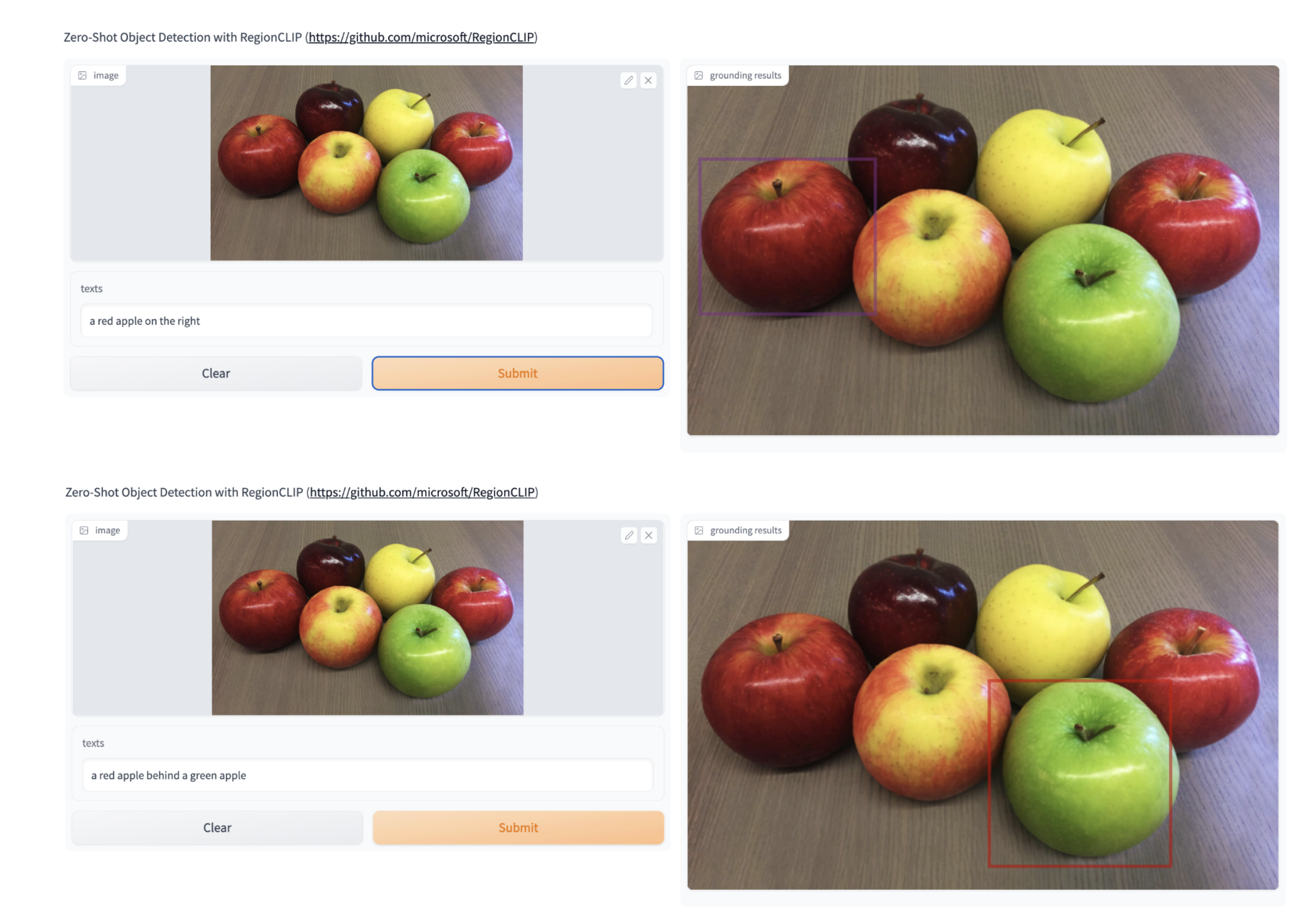
License: Apache 2.0 license
#1 in Interactive segmentation on SBD dataset
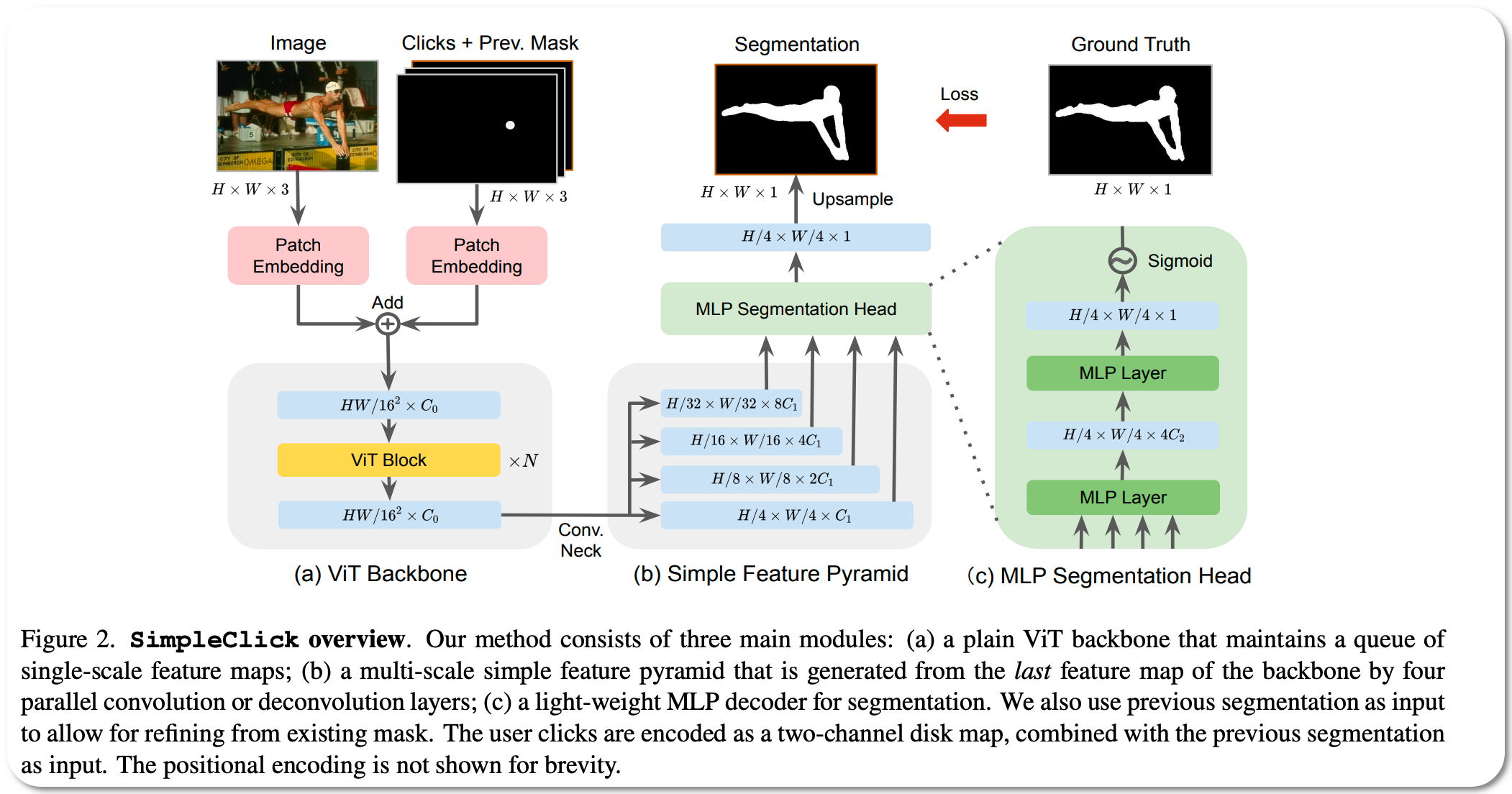

Model Name: SimpleClick
Notes: Click-based interactive image segmentation aims at extracting objects with limited user clicking. Hierarchical backbone is the de-facto architecture for current methods. Recently, the plain, non-hierarchical Vision Transformer (ViT) has emerged as a competitive backbone for dense prediction tasks. This design allows the original ViT to be a foundation model that can be finetuned for the downstream task without redesigning a hierarchical backbone for pretraining. Although this design is simple and has been proven effective, it has not yet been explored for interactive segmentation. To fill this gap, this paper proposes a plain-backbone method, termed as SimpleClick due to its simplicity in architecture, for interactive segmentation. Extensive evaluation of medical images highlights the generalizability of this method and its utility as a practical annotation tool.
Demo page: None to date, although there is a demo script on Github
License: MIT licence
#1 in learning with noisy labels on ANIMAL dataset
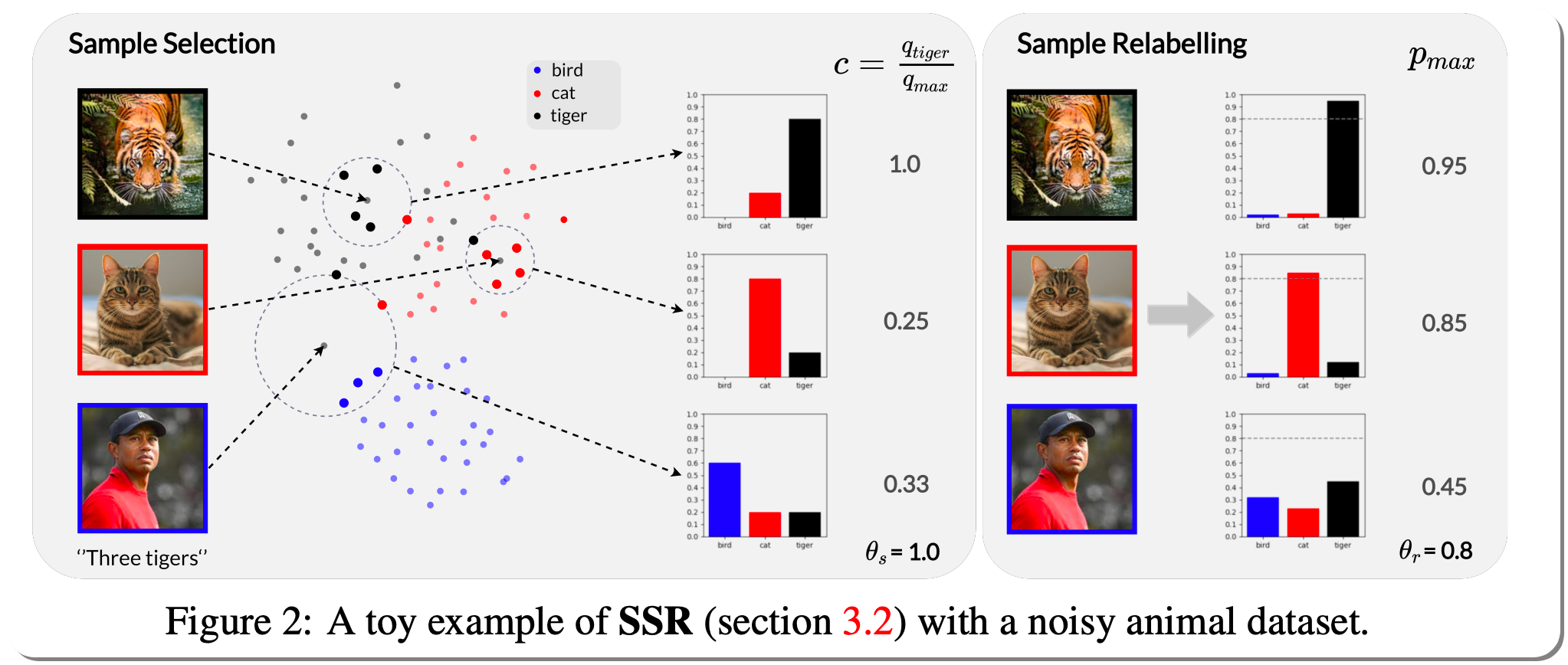
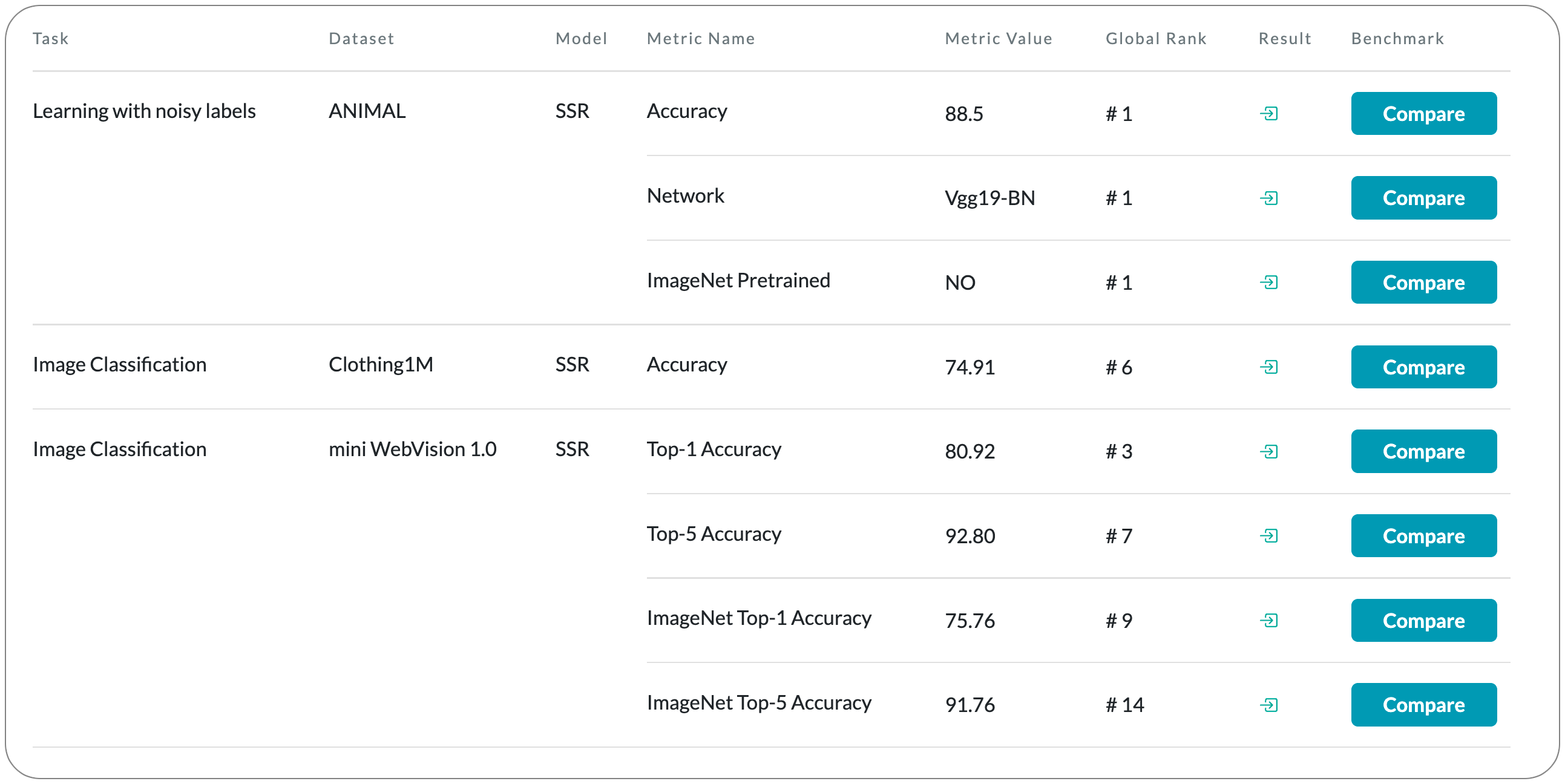

Model Name: SSR
Notes: This paper attempts to address the challenges in obtaining high-quality, large-scale and accurately labelled datasets, particularly how to learn in the presence of noisy labels has received more and more attention . This paper attempts to address this challenge by learning with unknown label noise, that is, learning when both the degree and the type of noise are unknown. Under this setting, unlike previous methods that often introduce multiple assumptions and lead to complex solutions, they propose a simple, efficient and robust framework named Sample Selection and Relabelling(SSR), that with a minimal number of hyperparameters achieves SOTA results in various conditions. At the heart of this method is a sample selection and relabelling mechanism based on a non-parametric KNN classifier~(NPK) and a parametric model classifier~(PMC) , respectively, to select the clean samples and gradually relabel the noisy samples.
Demo page: None to date
License: MIT License