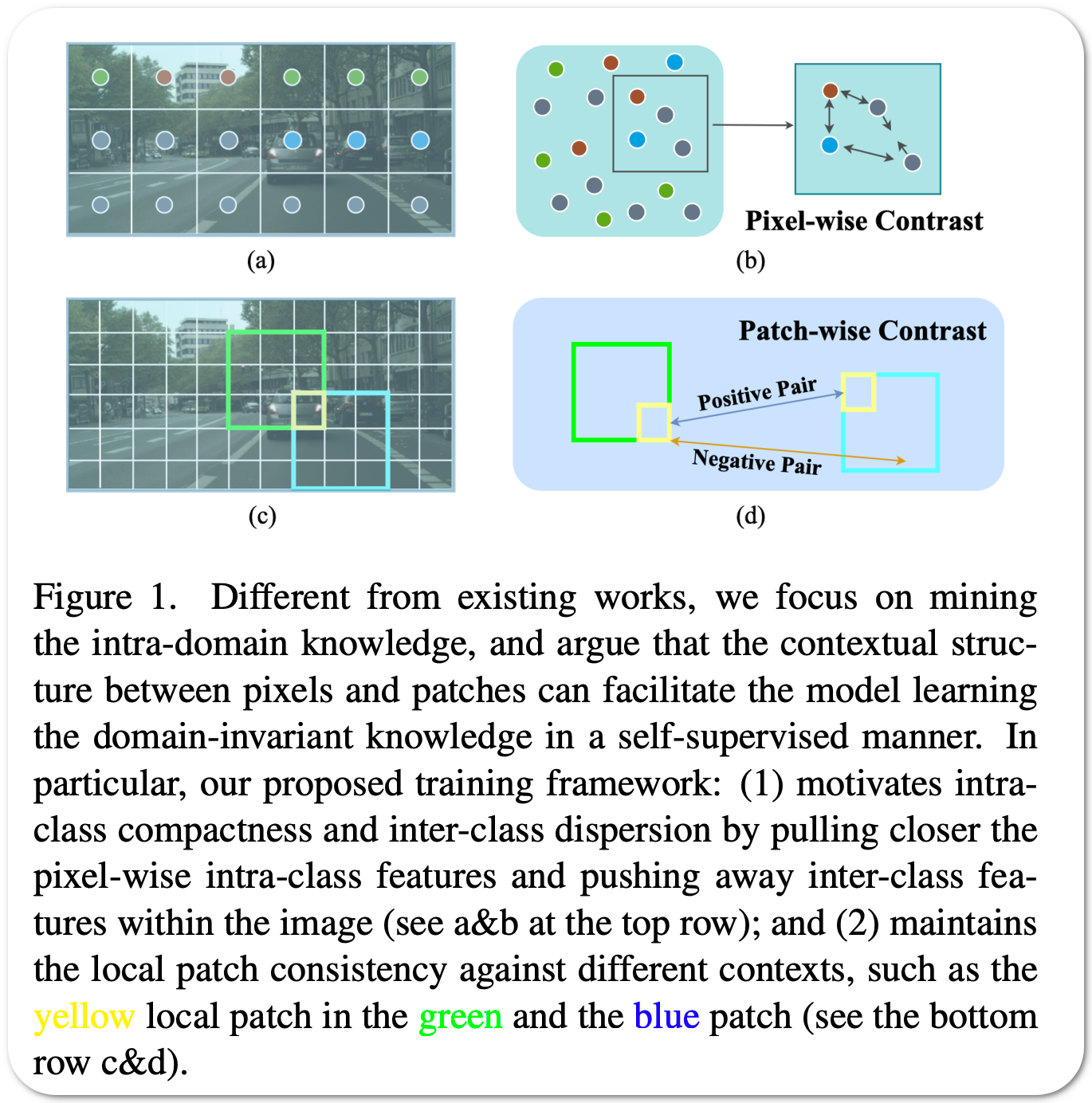
TWC #20
State-of-the-art (SOTA) updates for 12 – 18 Dec 2022.
This weekly newsletter highlights the work of researchers who produced state-of-the-art work breaking existing records on benchmarks. They also
- authored their paper
- released their code
- released models in most cases
- released notebooks/apps in few cases
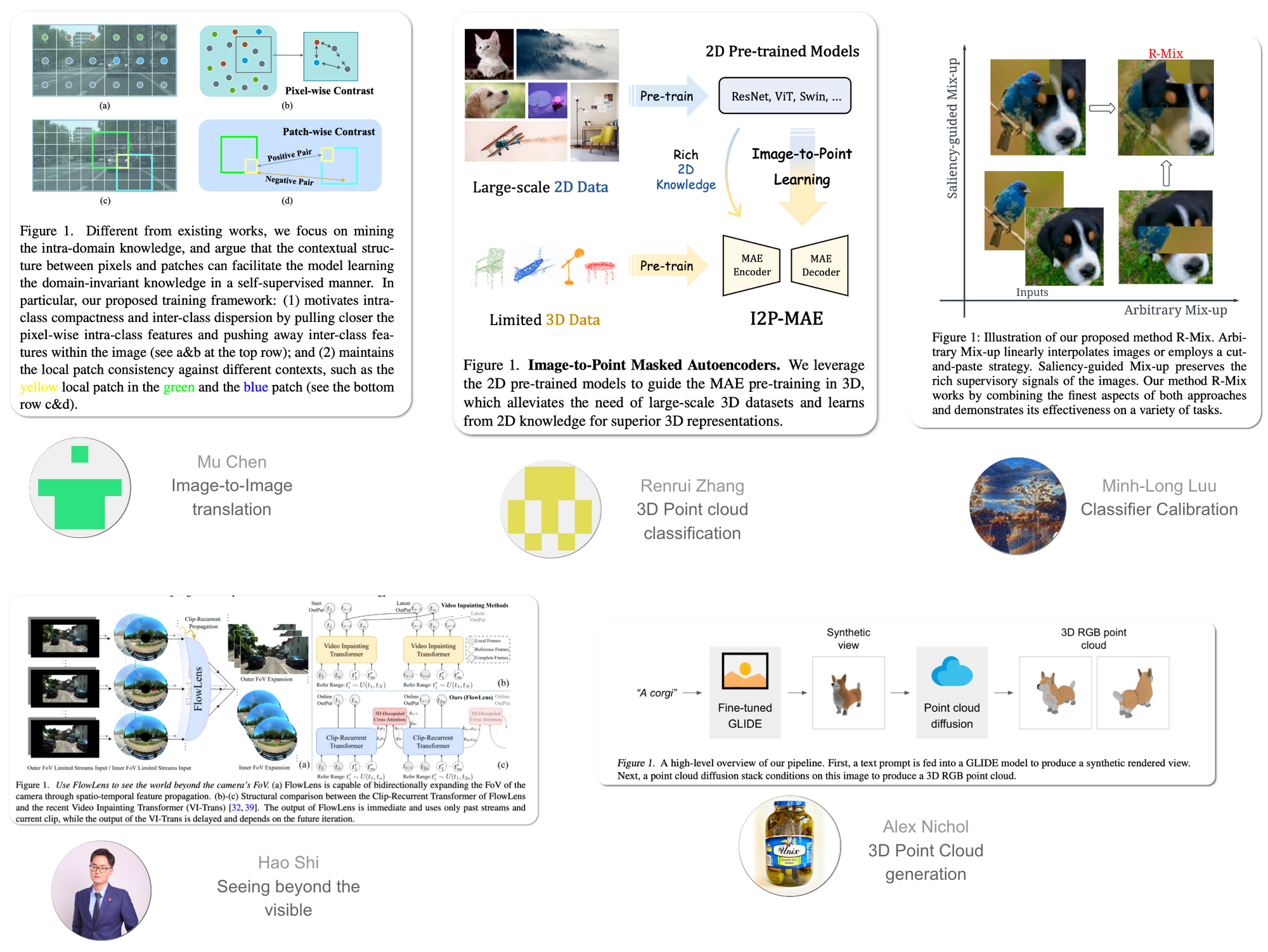
New records were set on the following tasks (in order of papers)
- Image Generation
- 3D Point Cloud Classification
- Classifier Calibration
- Seeing Beyond the Visible
The paper released with code from OpenAI did not set a new record, but is reported for its potential (two orders faster to sample from compared to other approaches) to generate 3D objects from a text description
- 3D Point cloud generation from complex prompts
To date, 27.8 % (94,134) of total papers (338,394) published have code released along with the papers (source).
SOTA details below are snapshots of SOTA models at the time of publishing this newsletter. SOTA details in the link provided below the snapshots would most likely be different from the snapshot over time as new SOTA models emerge.
Our contributions last week
- We submitted a pull request to add the use case of ChatGPT as a blind image captioner which we reviewed in last week's publication.
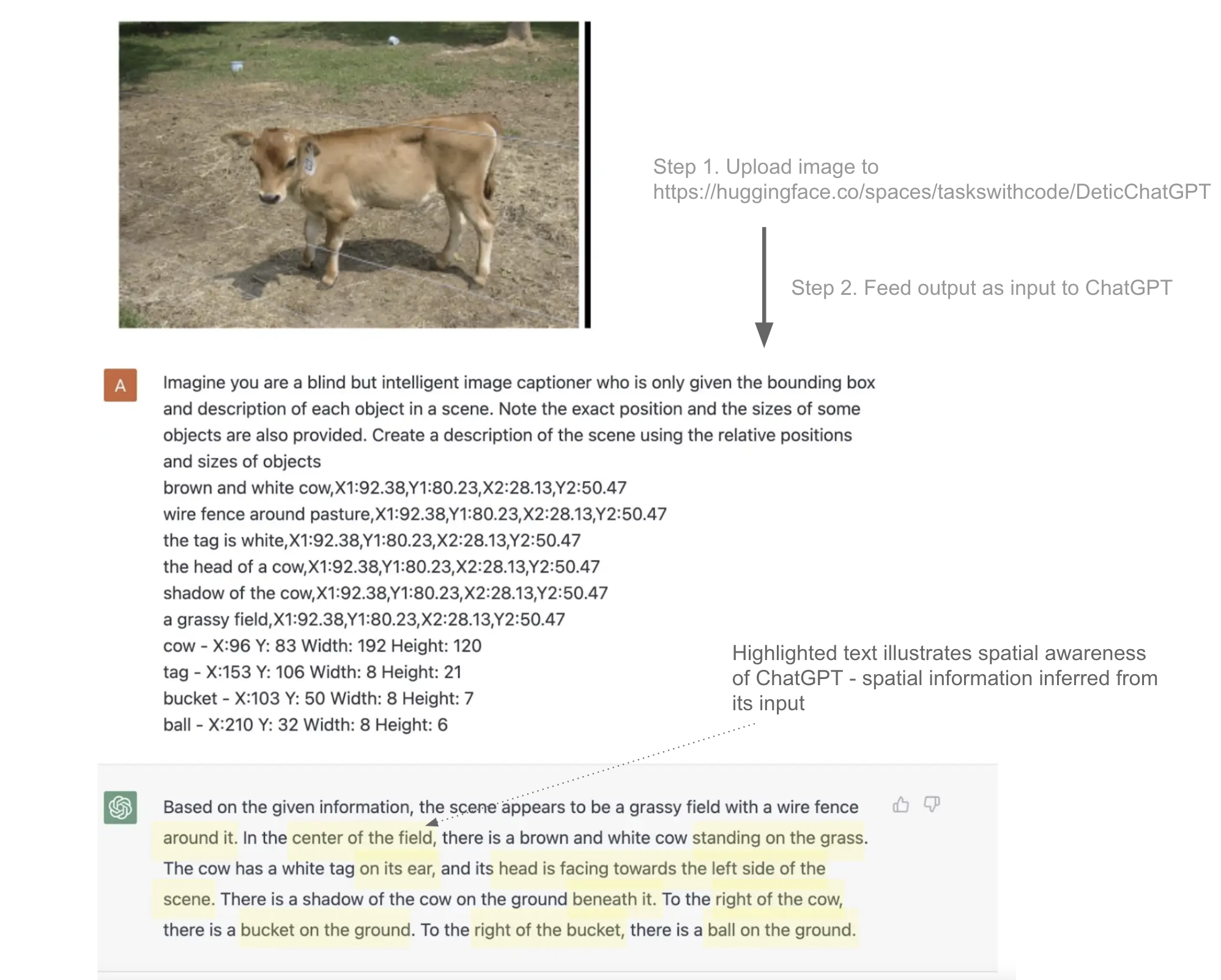
- Our work from last week was featured and developed further in the medium post ChatGPT - an epochal event
- A fork to replicate OpenAI's model Point-E released yesterday. See results below
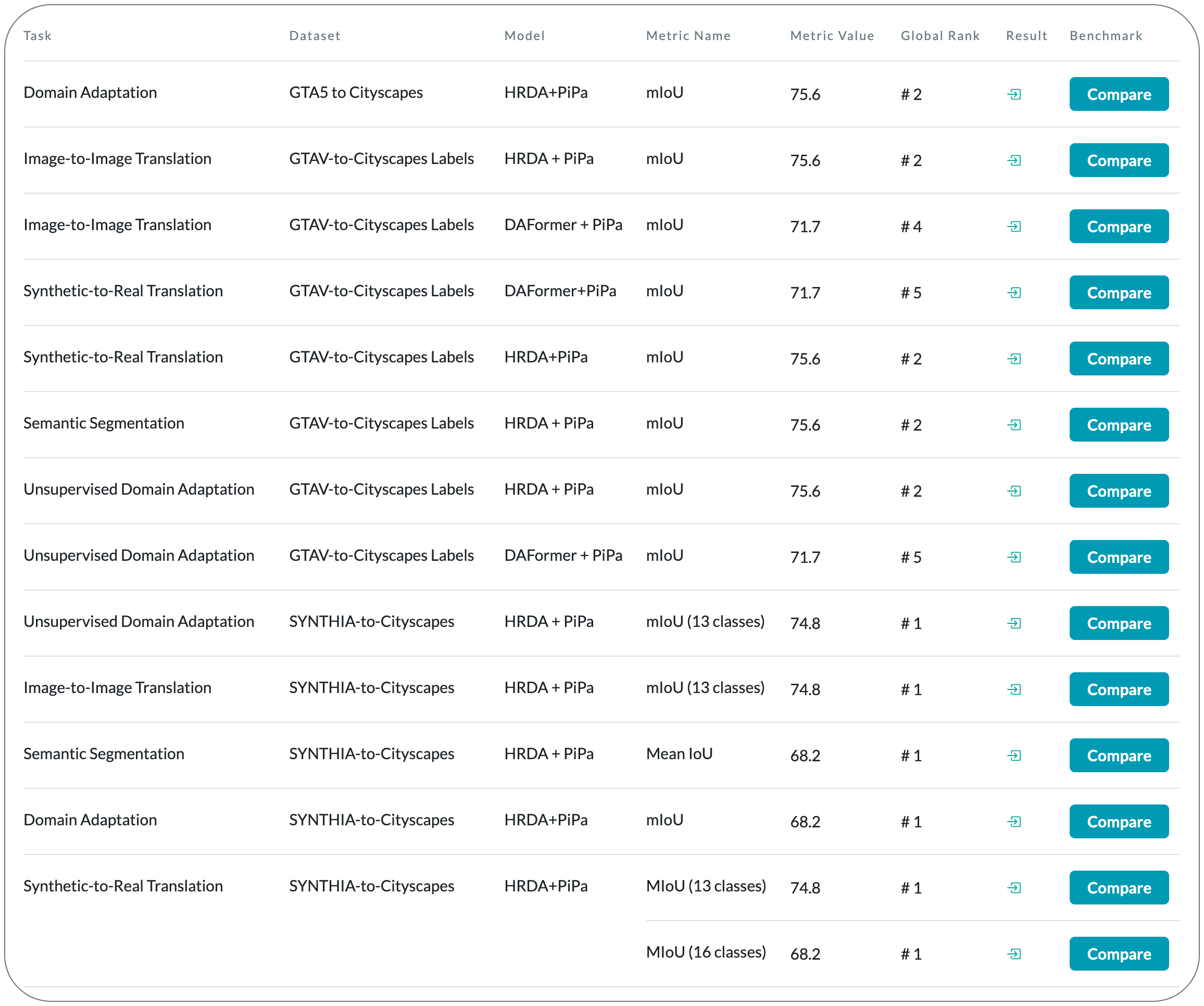
#1 in Image-to-Image Translation