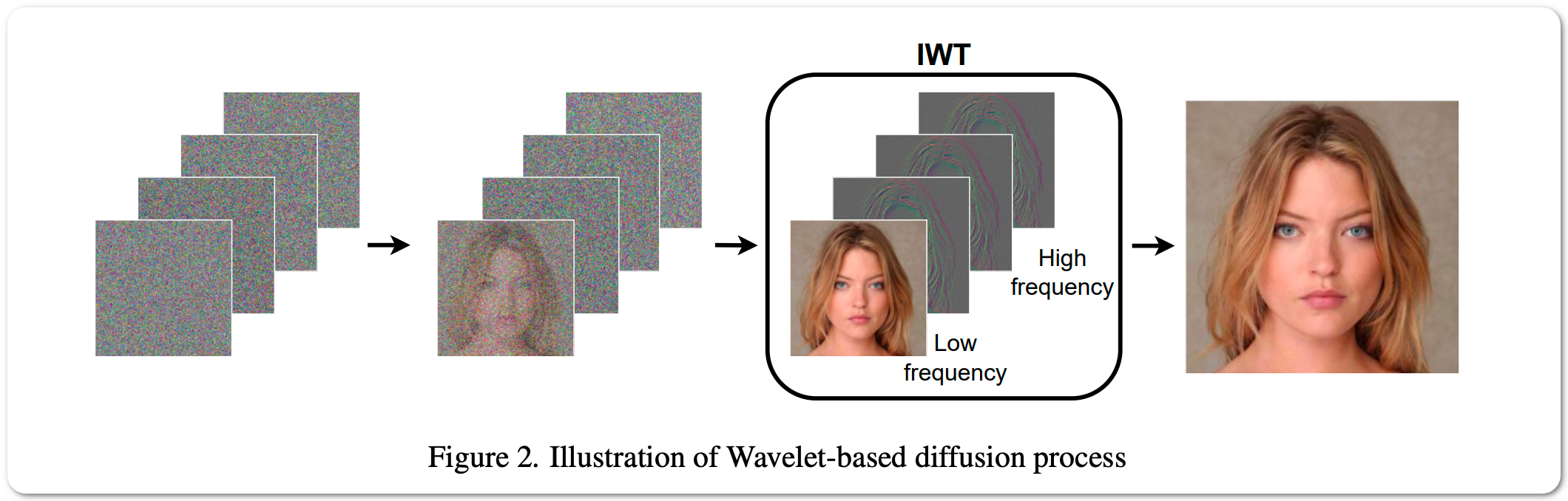
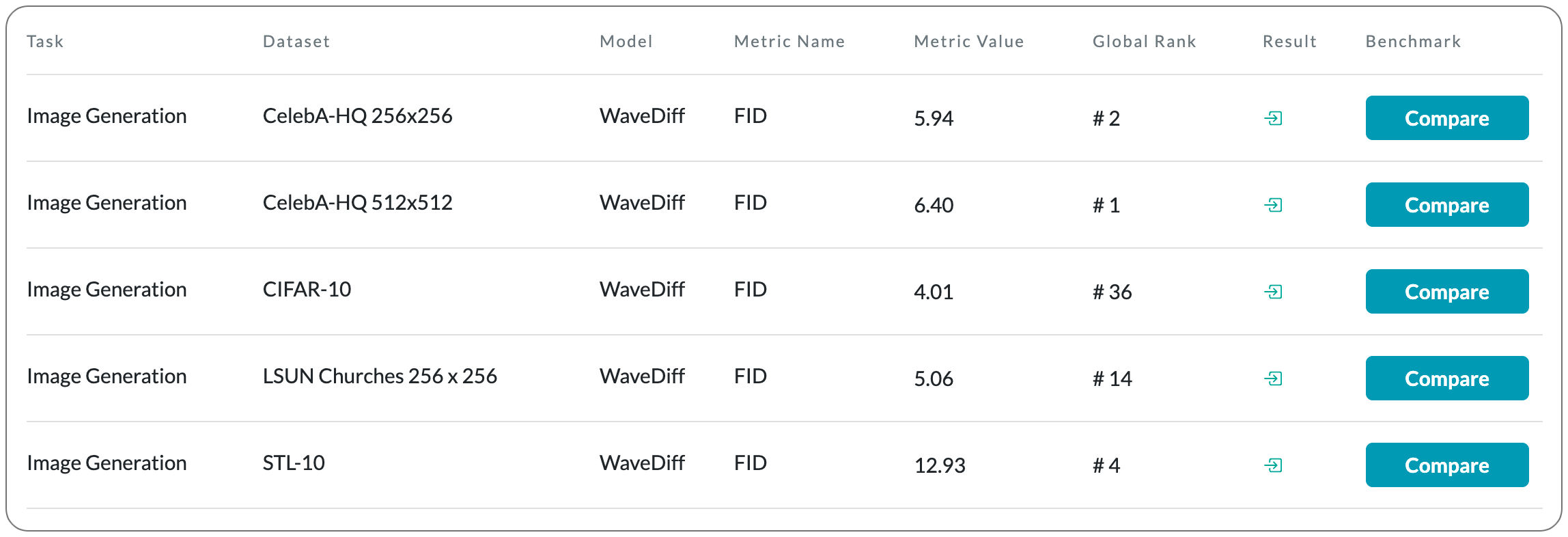
TWC #19

State-of-the-art (SOTA) updates for 5 – 11 Dec 2022.
This weekly newsletter highlights the work of researchers who produced state-of-the-art work breaking existing records on benchmarks. They also
- authored their paper
- released their code
- released models in most cases
- released notebooks/apps in few cases
New records were set on the following tasks (in order of papers)
- Image Generation
- Unsupervised Domain adaptation
- SMAC tasks (Sequential Model-based Algorithm Configuration)
- Dense Captioning
- Motion Synthesis
To date, 27.8% (93,701) of total papers (337,412) published have code released along with the papers (source).
SOTA details below are snapshots of SOTA models at the time of publishing this newsletter. SOTA details in the link provided below the snapshots would most likely be different from the snapshot over time as new SOTA models emerge.
#1 in Image Generation on CelebA-HQ 512x512 dataset