TWC #18

State-of-the-art (SOTA) updates for 28 Nov – 4 Dec 2022.
This weekly newsletter highlights the work of researchers who produced state-of-the-art work breaking existing records on benchmarks. They also
- authored their paper
- released their code
- released models in most cases
- released notebooks/apps in few cases
Nearly half of released source code licenses allow commercial use with just attribution. Machine Learning powered companies owe their existence at least in part to the work of these researchers. Please consider supporting open research by starring/sponsoring them on Github
New records were set on the following tasks (in order of papers)
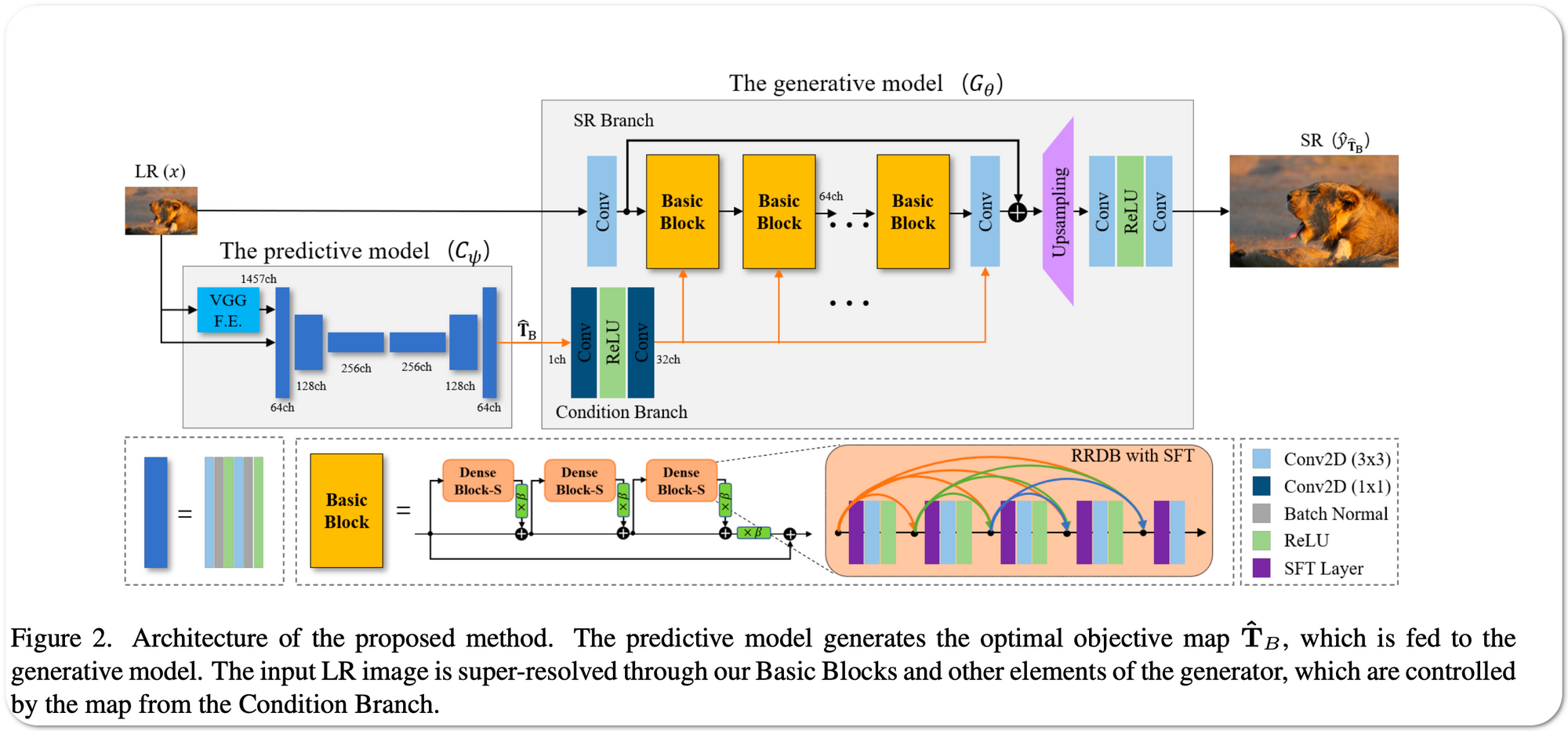
- Image Super-Resolution
- Anomaly detection
- Semantic Segmentation
- Anomaly detection
- 3D Point Cloud Registration (3D point cloud registration is like taking multiple pictures of an object from different angles and then piecing them together to create a single, comprehensive image - a layman's explanation generated by ChatGPT better than definitions found on the web).
This weekly is a consolidation of daily twitter posts tracking SOTA researchers. Daily SOTA updates are also done on @twc@sigmoid.social - "a twitter alternative by and for the AI community"
To date, 27.7% (92,934) of total papers (335,599) published have code released along with the papers (source).
SOTA details below are snapshots of SOTA models at the time of publishing this newsletter. SOTA details in the link provided below the snapshots would most likely be different from the snapshot over time as new SOTA models emerge.
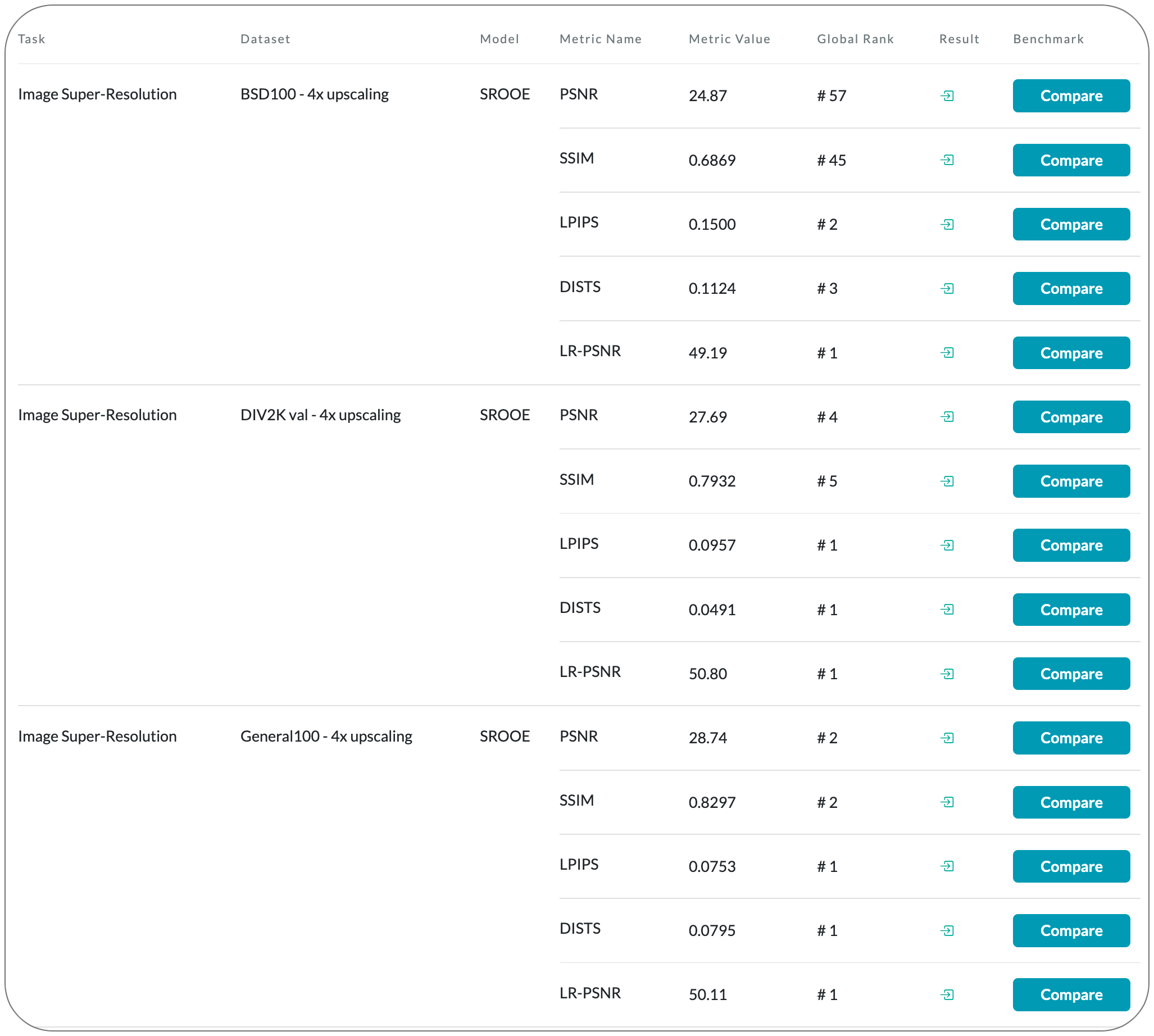
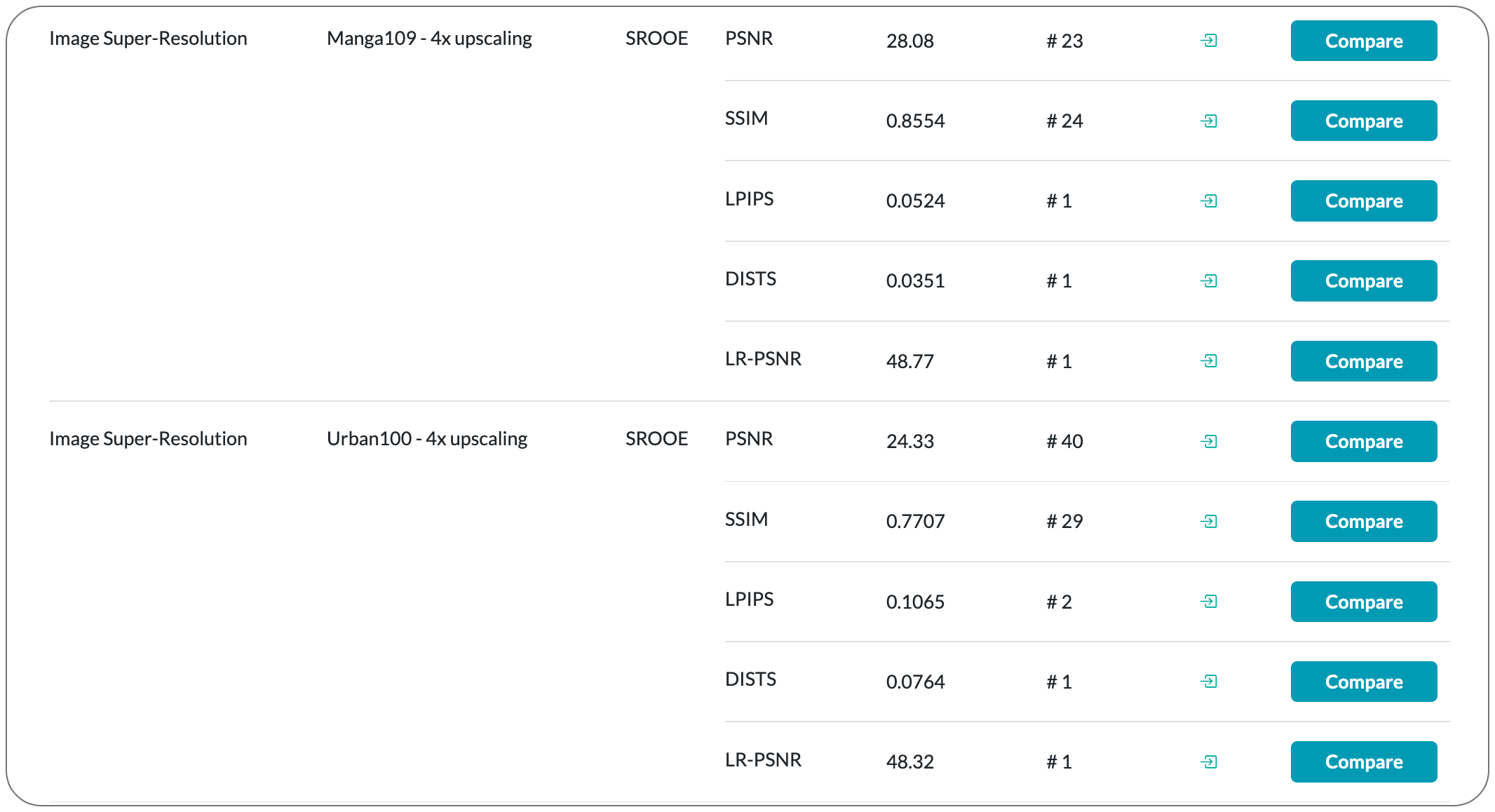
#1 in Image Super-Resolution on 5 datasets