TWC Issue #2

State-Of-The-Art categories reviewed
Consolidation of daily twitter posts for the range 8–14 August 2022
- Video and image deblurring
- Action recognition in videos
- Boundary grounding and captioning in videos
- Optical flow estimation in videos
- Video and image semantic segmentation
- 3D face reconstruction
- Video and Image super resolution
- Heart beat detection and rate estimation
- Sound event localization and detection
Official code release also available for these tasks
Video and Image deblurring
Video restoration from low quality frames
Model Name:VRT

Video restoration unlike image restoration requires temporal information from adjacent frames. VRT (video restoration transformer) performs both frame prediction as well as model long range temporal dependencies.
VRT has top performance (34.81,34.27,36,79) on 3 deblurring datasets (GoPro, REDS,DVD). The metric is Peak-signal-to-noise ratio. VRT can be used for video deblurring, video super-resolution, video denoising, and video interpolation (examples on the github) page.
Key Links:
- Paper
- Github code released by Jingyun Liang (first author in paper) Model link: in Github page
- Dataset, GoPro, REDS, DVD (DeepVideoDeblurring dataset)
- Demo page
- Google Colab link? Link
- Container image? None to date
Image Deblurring
Model Name: Uformer-B


This model addresses two problems when applying transformers to image restoration - (1) it is unsuitable to apply quadratic attention to high-resolution feature maps (2) local context information is essential for image restoration since the neighborhood of a degraded pixel could be used to restore the cleaner version. This is accomplished by incorporating convolutions into transformer block to capture local context.
Uformer-B has top performance (36.22,29.06,33.98) on 3 datasets (RealBlur-R,RealBlur-J, RSBlur). The metric is Peak-signal-to-noise ratio. Uformer-B can be used for image restoration tasks such as image denoising, motion deblurring, defocus deblurring and deraining.
Key Links:
- Paper
- Github code released by Zhendong Wang (first author in paper) Model link
- Dataset. RealBlur-R, RealBlur-J, RSBlur
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date
Image Deblurring
Model Name: MAXIM


Maxim offers an alternative architectural solution to the same problems Uformer-B solves. It has top performance (32.83,32.84) on HIDE and RealBlur-J datasets.
Key Links:
- Paper
- Github code released by Yinxiao Li (last author in paper) Model link
- Dataset. RealBlur,HIDE
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date
Action recognition in videos
Skeleton points based action recognition leveraging language models
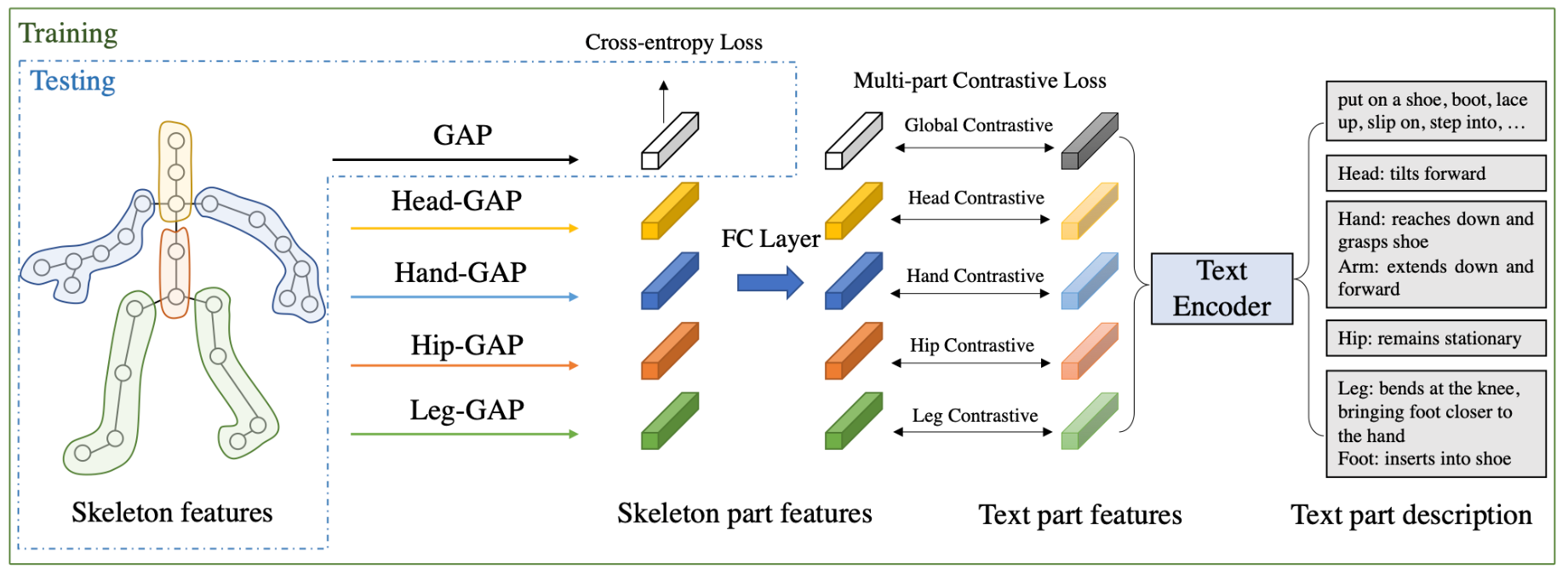
Action recognition is used in a wide range of human computer interactions like entertainment, sport, health analysis etc. A multimodal training scheme leverages a large language model to provide text descriptions for body part movements. This approached is to improve representation learning during the training process.
The model LST improves state-of-art by .7 in accuracy on N-UCLA dataset.
Key Links:
- Paper
- Github code released by MartinXM (likely first author) Model Not released to date.
- Dataset
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date
Boundary grounding and captioning in videos
The paper introduces a new dataset Kinetics-GEB+ for boundary grounding and captioning and tests models that performs the best on this dataset.
Boundary grounding task

Given a description of a boundary inside a video, a boundary grounding model is required to locate the boundary inside that video.
The SOTA model has an average F1-score of 33.35 on the Kinetics-GEB+ dataset. This is a new dataset introduced for this task. The paper is an introduction of this dataset.
Boundary captioning task
Provided with the timestamp of a boundary inside a video, the model is required to generate sentences describing the status change at the boundary.
The SOTA model has an average CIDEr-score (Consensus-based Image Description Evaluation) of 74.71 on the Kinetics-GEB+ dataset.
Key Links:
- Paper
- Github code released by Yuxuan Wang (first author in paper) Model link
- Dataset. Annotated, Raw
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date
Optical flow estimation in videos
Optical flow estimation is the task of predicting pixel level motion between video frames.
The SOTA model on this task DEQ-Flow-H improves upon its previous score by .5 points (F1-all metric) on the KITTI 2015 dataset.
Key Links:
- Paper
- Github Code released by Zhengyang Geng (second author in paper) Model link
- Dataset
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date
Video and image semantic segmentation
LiDAR semantic segmentation

This paper proposes using scribbles an interactive annotation tool to annotate LiDAR point clouds and release ScribbleKITTI, the first scribble-annotated dataset for LiDAR semantic segmentation.
Key Links:
- Paper
- Github Code released by Ozan Unal (first author in paper) Model link
- Dataset
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date
Language as queries for referring to video object segmentation

This model (ReferFormer) uses language as queries and directly attends to the most relevant regions in the video frames.
This model improves state-of-art by .72 (metric: IoU overall) to .786 on A2D dataset.
Key Links:
- Paper
- Github Code released by Jiannan Wu (first author in paper) Model Pertrained models are available on Github page.
- Dataset
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date
Image semantic segmentation
High-resolution domain adaptive semantic segmentation
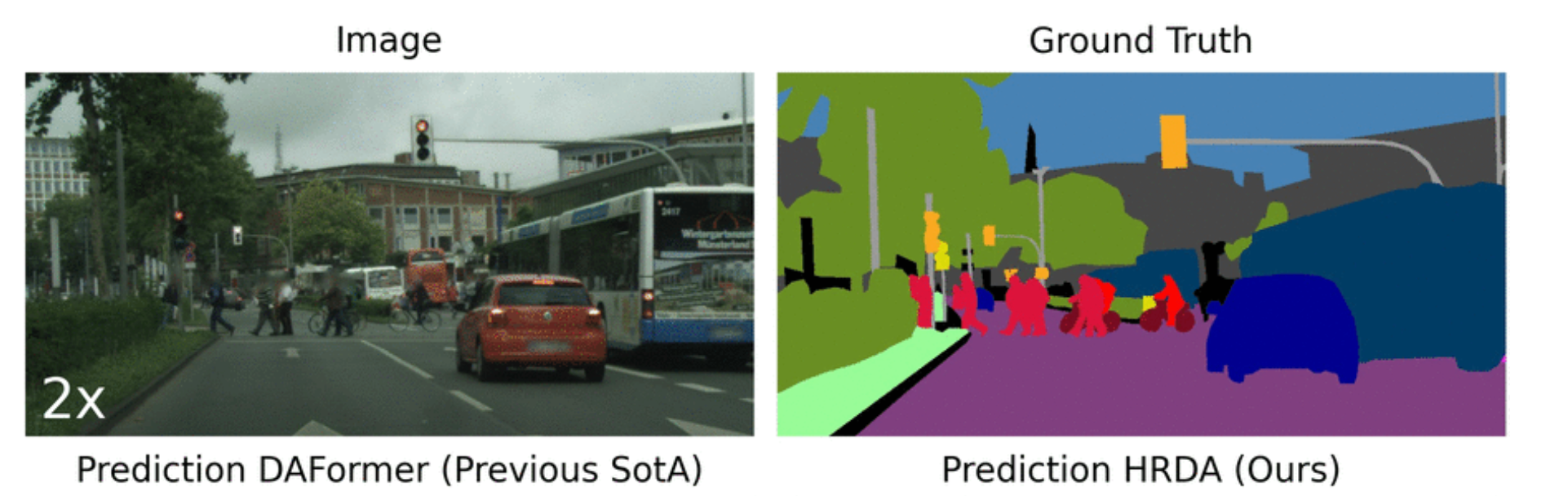
This paper proposes a multi-resolution training approach for unsupervised domain adaptation UDA, that combines the strengths of small high-resolution crops to preserve fine segmentation details and large low-resolution crops to capture long-range context dependencies with a learned scale attention, while maintaining a manageable GPU memory footprint.
The model improves SOTA performance by 2.5 points to a score of 68.0 (metric: mIoU) on Cityscapes to ACDC dataset.
Key Links:
- Paper
- Github code released by Lukas Hoyer (first author in paper) Model Pretrained models for the different benchmarks are available in github page
- Dataset
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date
Saliency Prediction

A saliency map is a model that predicts eye fixations on a visual scene and is used in robotics, multimedia, healthcare etc.
TranSalNet leverages transformers for modeling long range interactions complementing a CNN architecture. The models has SOTA performance on two datasets - MIT300 and SALICON.
Key Links:
- Paper
- Github Code released by Jianxun Lou (first author in paper) Model Pretrained models in Github page.
- Dataset MIT300, SALICON
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date
3D face reconstruction

MICA , performs 3D face reconstruction from 2D images and improves SOTA by .19 points bringing down mean reconstruction error to 1.11
Key Links:
- Paper
- Github Code released by Wojciech Zielonka (first author in paper) Model Pretrained model links on Github page
- Dataset
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date
Video and Image super resolution
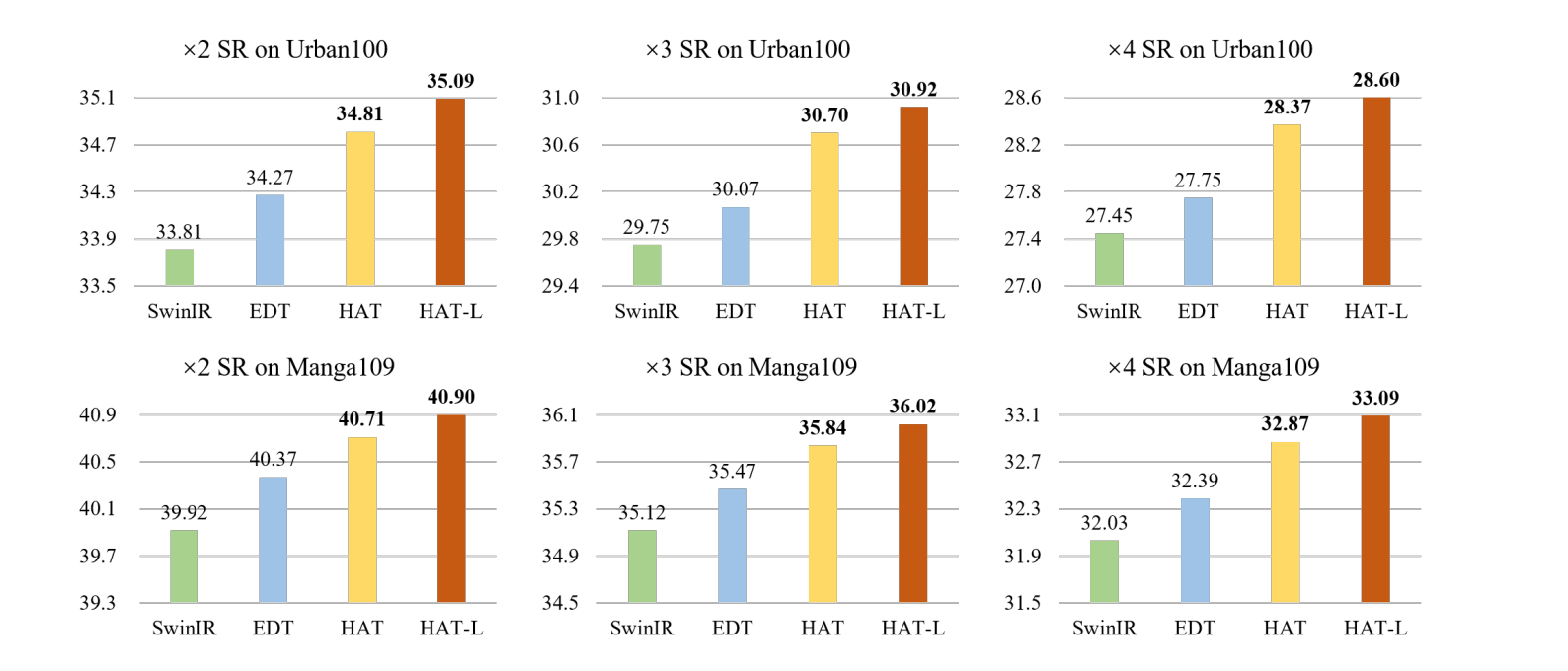
VRT, mentioned above performs video super resolution
HAT performs image super resolution using a transformer and improves SOTA by .52 points (metric: PSNR) to 27.97
Key Links:
- Paper
- Github Code released by Xiangyu Chen (first author in paper) Model Pretrained model links on Github page
- Dataset
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date
Heart beat detection and rate estimation
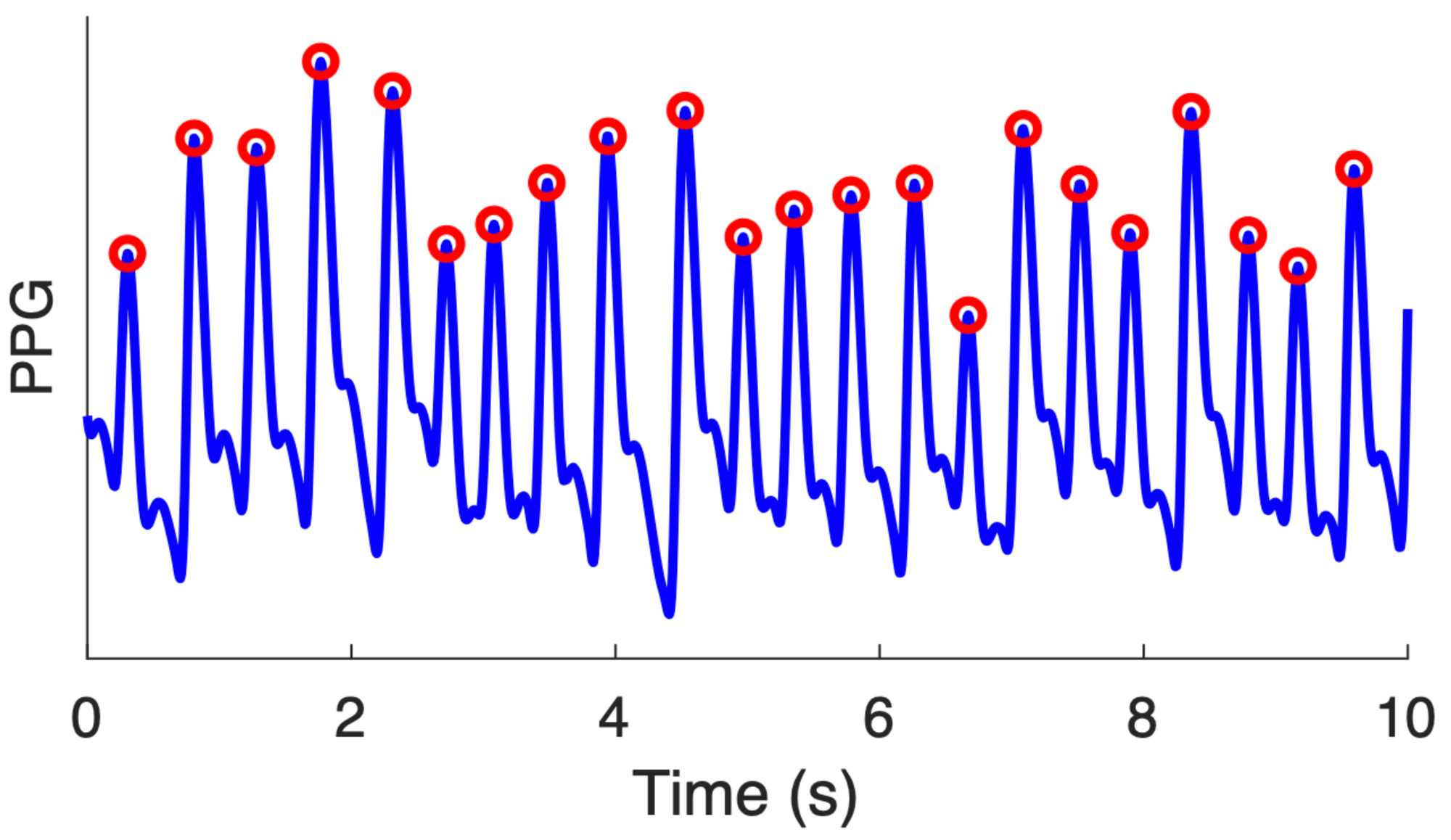
MSPTD improves SOTA on both heart beat detection (97.5 F1-score) and rate estimation (2.4 metric MAPE).
Key Links:
- Paper
- Github code released by Peter H Charlton (first author in paper) Model N/A
- Dataset N/A
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date
Sound event localization and detection
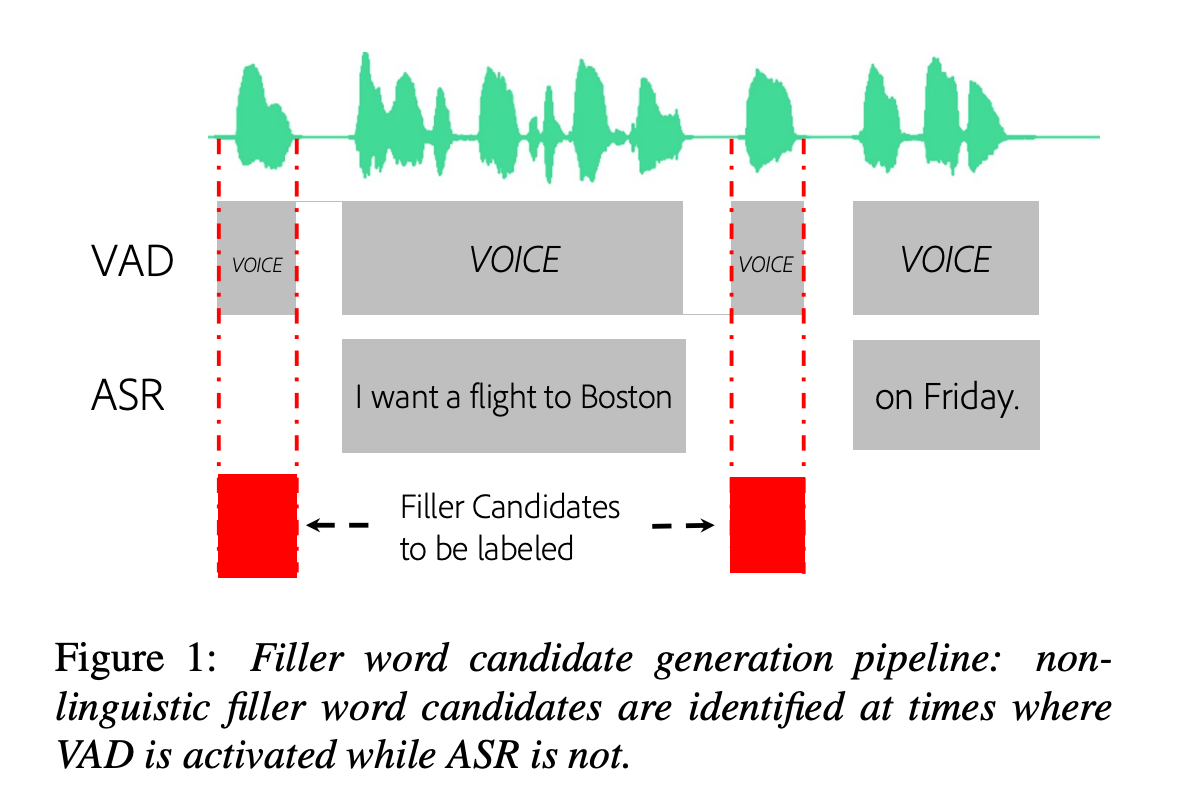
AVC-FillerNet improves SOTA by a significant amount - 21.8 points (F-1 score) to 92.8 on Podcast fillers dataset.
The task is find and classify fillers words like "um", "uh" in speech as people pause to think. This is then used to remove them from the audio.
Key Links:
- Paper
- Github Code released by Ge Zhu (first author in paper) Model N/A
- Dataset N/A
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date