TWC Issue #1

State-of-art categories reviewed
(5–7 August 2022)
- Pose estimation
- Zero-shot action recognition in videos
- Image Retrieval from Contextual Descriptions
- Age estimation from image
Official code release also available for these tasks
Pose estimation
3-D Pose Human pose and shape estimation

Top-down approaches for human pose and shape estimation typically crop the image to focus on the core problem. However, by doing so, they loose important global information about the actual angle of the subject relative to the camera (shown below).
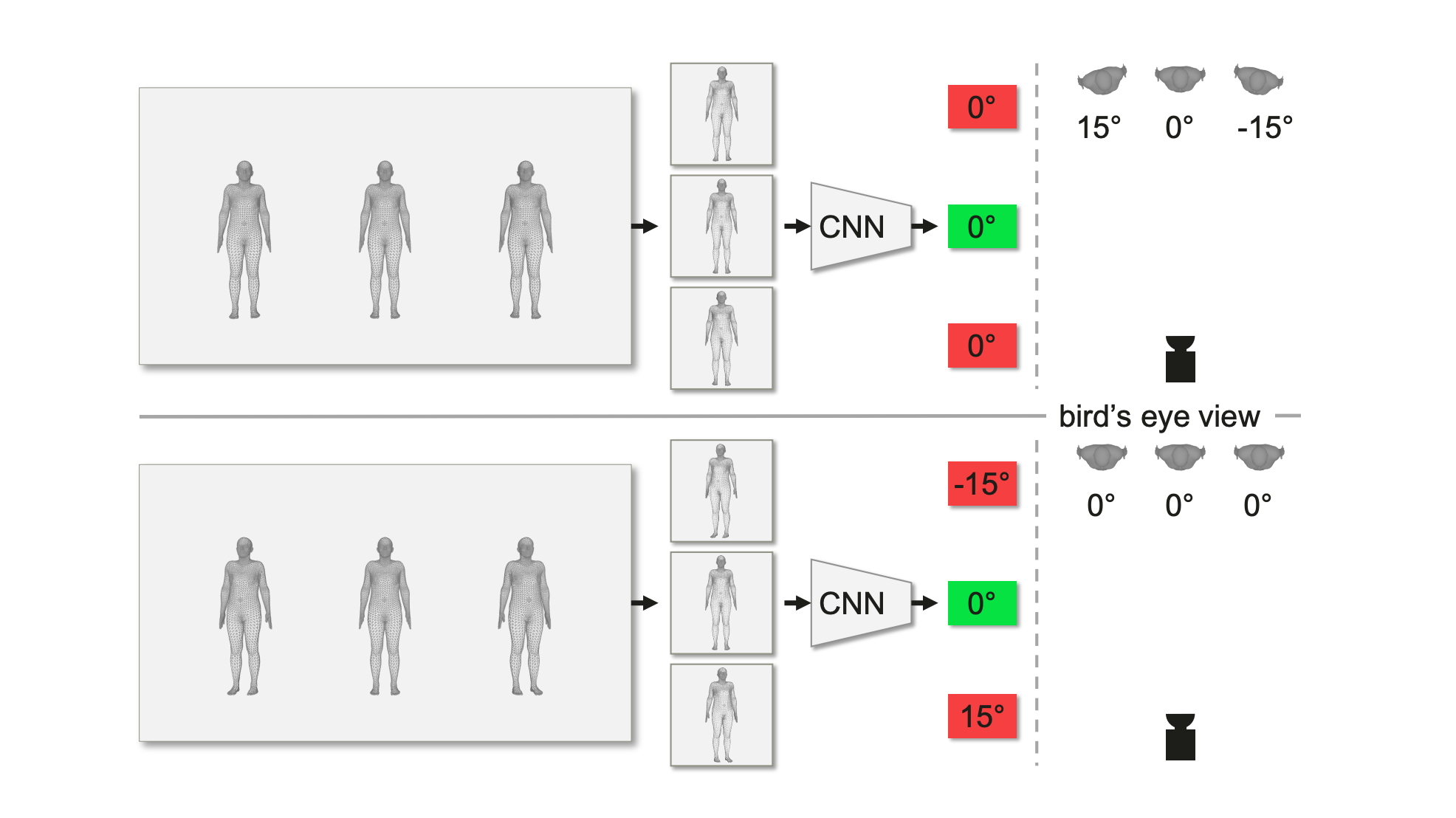
CLIFF (Carrying Location Information in Full Frames), in contrast takes a holistic approach and feeds the model sufficient information that is adequate for estimating global rotation.
The model improved state-of-art by 7.6 units (40.4 to 32.8 PA-MPJPE) on 3DPW where evaluation metric PA-MPJPE measures the euclidean distance in millimeters between prediction and ground truth after performing shape alignment.
3DPW 3D Poses in the Wild dataset is the first dataset in the wild with accurate 3D poses for evaluation. While other datasets outdoors exist, they are all restricted to a small recording volume. 3DPW is the first one that includes video footage taken from a moving phone camera.
Official code release of the paper is available on Github. Models are available for download after registering.
The dataset can be used for non-commercial purposes and scientific research purposes. It can be downloaded directly after reading the license agreement.
Key Links:
- Paper
- Github Code released by Zhihao Li (first author in paper) Model: Model links in Github page
- Dataset
- Demo page? None to date
- Google Colab link? None to date
- Container image? None to date
6 Degrees of freedom (6-DOF) pose estimation in RGB-D images
This model (RCVPose+ICP) improves the state-of-art by .9 (OccludedLINEMOD dataset) and .3 (LineMOD dataset) points. The evaluation metric ADD is a measure of distance between points. A pose estimation is considered correct if its ADD falls within 10% of the object radius.
Official code release of the paper is available on Github. Pretrained models are also available for download.
The dataset links are directly available for download in the Github page LineMOD, OccludedLINEMOD.
Key Links:
- Paper
- Github Code released by aaronWool/Yangzheng Wu (Yangzheng Wu - first author in paper) Model: Model links in Github page
- Datasets LineMOD, OccludedLINEMOD
- Demo page? None to date
- Google Colab link? None to date
- Container image? None to date
Zero-shot action recognition in videos
X-CLIP expands language-image pretrained models for video recognition instead of having to pretrain a model from scratch. A cross-frame attention mechanism exchanges information across frames

This model improved state-of-art accuracy by 23.1 units (65.2 from 42.1 top-1 accuracy) on kinetics dataset. Kinetics is a collection of 650,000 large-scale high quality video clips covering 600 action classes. The dataset is directly available for download covered by a creative commons license.

Pretrained models are also available for download in the Github page for code.
Key Links:
- Paper
- Github code released by Houwen Peng (second author in paper) Model: Model links in Github page
- Dataset
- Demo page spaces link? None to date
- Google Colab link None to date
- Container image None to date
Image Retrieval from Contextual Descriptions
This paper introduces a new challenge dataset Image retrieval from contextual descriptions (ImageCoDe). This challenge illustrates models still lag far behind human performance on this task - 90.8 by humans in comparison to 20.8 on video and 59.4 on static images. This dataset is intended to foster progress in grounded language understanding
The dataset could be downloaded from HuggingFace , Zenodo or Google Drive. The models to perform experiments on can be downloaded from this link . ContextualCLIP model that achieved highest performance 29.9 accuracy can be downloaded from here.
Key Links:
- Paper
- Github code released by Benno Krojer ( first author in paper) Model: Links, ContextualCLIP
- Dataset
- Demo page spaces link? A HuggingFace space to examine the dataset
- Google Colab link None
- Container image None
Age estimation from image
Two models MWR and FP-Age improved state-of-art on age estimation from image.
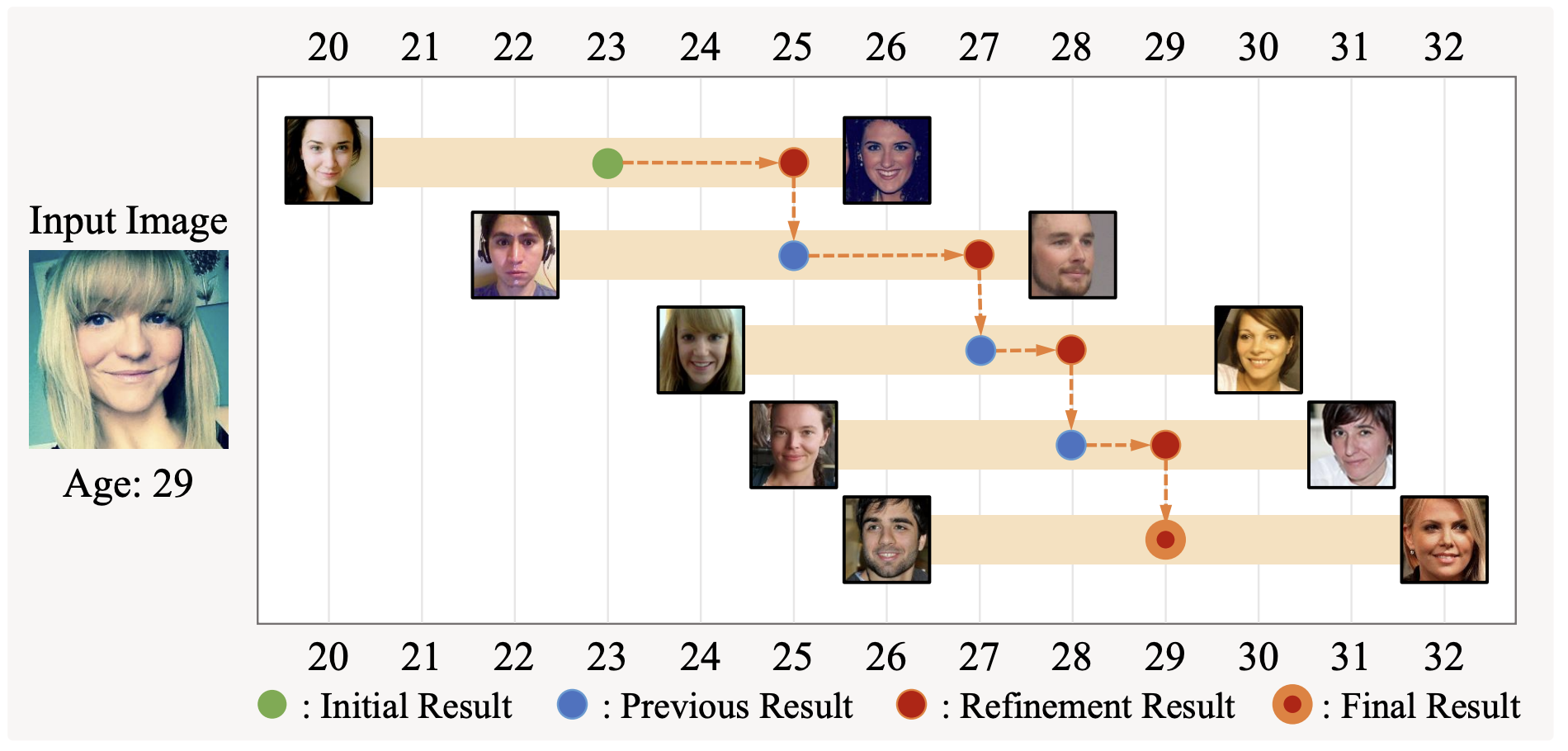
MWR improved state-of-art on four datasets ChaLearn 2015, FG-NET, UTKFace, CACD - 2.95 (Prev: 3.135 ), 2.23 (Prev:2.95), 4.37(Prev:4.55),4.41(Prev:4.60). The unit is mean absolute error - average absolute error between predicted and ground-truth ages. FP-Age created state-of-art on IMDB-Clean (4.68) and KANFace (6.81)
Key Links:
- Paper MWR
- Github Code. released by Nyeong-Ho Shin ( first author in paper) Model: Link in Github page
- Dataset ChaLearn 2015, FG-NET, UTKFace, CACD; IMDB-Clean, KANFace
- Demo page spaces link? None to date
- Google colab link? None to date
- Container image? None to date