TWC #14

State-of-the-art (SOTA) updates for 31 Oct– 6 Nov 2022
TasksWithCode weekly newsletter highlights the work of SOTA researchers. Researchers in figure above produced state-of-the-art work breaking existing records on benchmarks. They also
- authored their paper
- released their code
- released models in most cases
- released notebooks/apps in few cases
It is worth noting a significant proportion of the code release licenses allow commercial use. The only ask of these researchers from us in return is attribution. Also worth noting many of these SOTA researchers have little to no online presence.
The selected researchers broke existing records on the following tasks
- Weakly Supervised Object Detection
- Science Question Answering
- Face swapping
- Graph Regression
- Text Summarization
- Q&A
- Riddle Sense
- Semantic correspondence - The task of semantic correspondence aims to establish reliable visual correspondence between different instances of the same object category.
- Occluded object detection
- Continual Pretraining
- Self-supervised image classification
This weekly is a consolidation of daily twitter posts tracking SOTA researchers. Starting this week, daily SOTA updates are also done on @twc@sigmoid.social - "a twitter alternative by and for the AI community"
To date, 27.4% (90,391) of total papers (329,773) published have code released along with the papers (source).
SOTA details below are snapshots of SOTA models at the time of publishing this newsletter. SOTA details in the link provided below the snapshots would most likely be different from the snapshot over time as new SOTA models emerge.
#1 on Weakly Supervised Object Detection
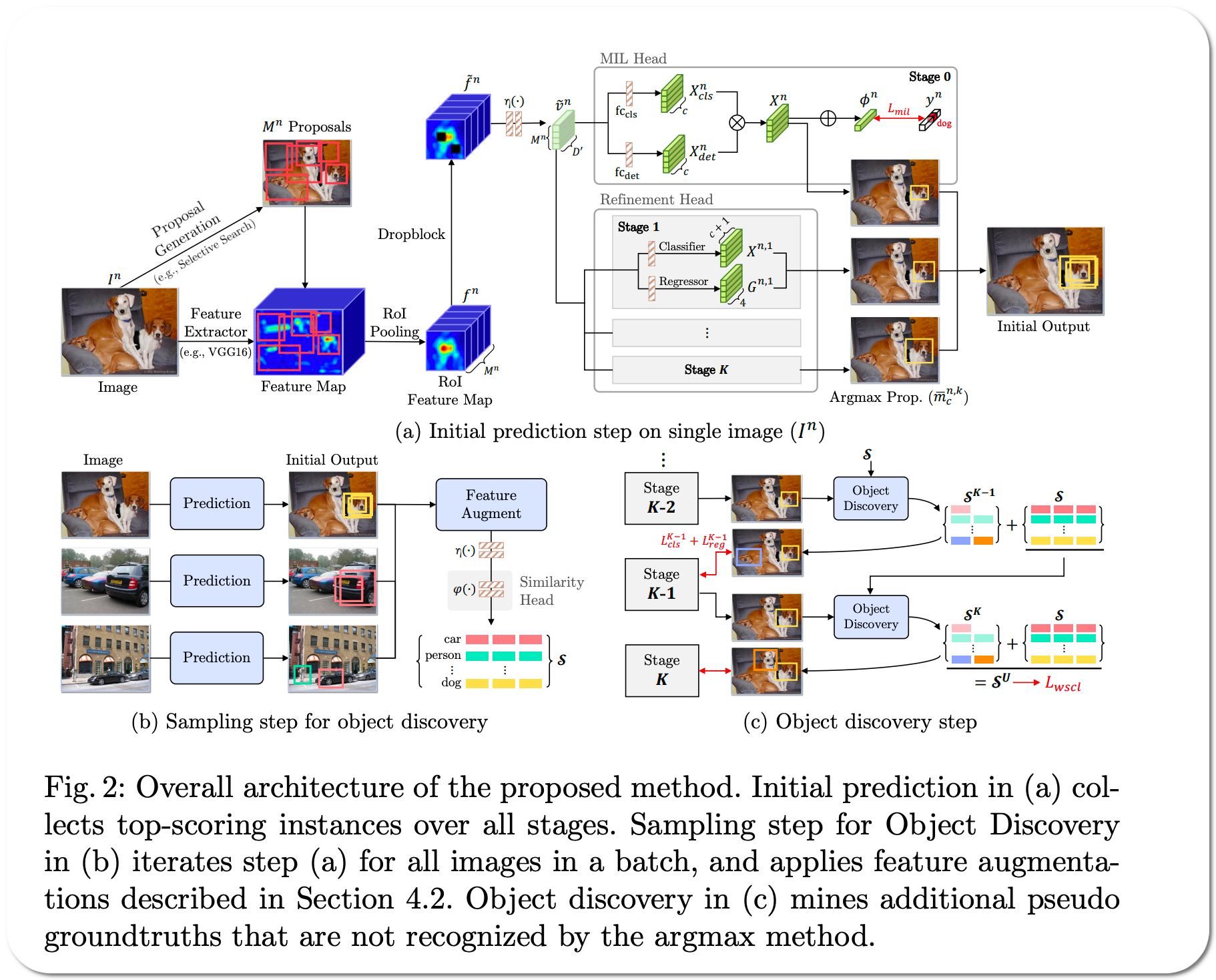
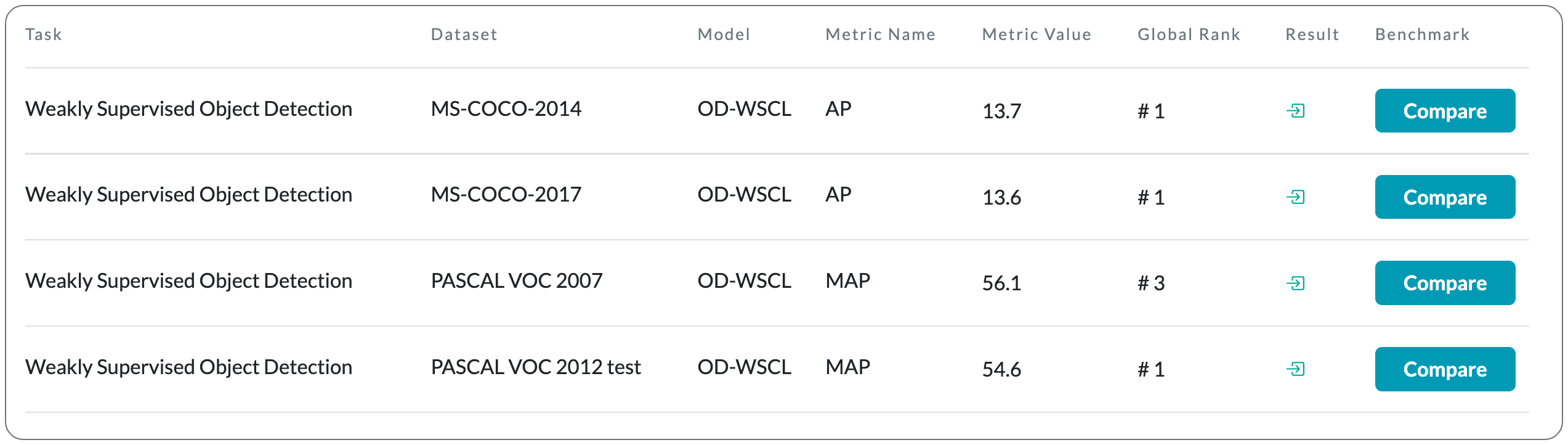

Model Name: OD-WSCL
Notes: Weakly Supervised Object Detection (WSOD) is a task that detects objects in an image using a model trained only on image-level annotations. Current state-of-the-art models benefit from self-supervised instance-level supervision, but since weak supervision does not include count or location information, the most common 'argmax' labeling method often ignores many instances of objects. To alleviate this issue, this paper proposes a multiple instance labeling method called object discovery. They also introduce a contrastive loss variant under weak supervision where no instance-level information is available for sampling, called weakly supervised contrastive loss (WSCL). WSCL aims to construct a credible similarity threshold for object discovery by leveraging consistent features for embedding vectors in the same class.
Demo page: No demo page to date. Project page has more examples.
License: This codebase is a derivation of code covered by Nvidia source code license
#1 in Science Question Answering on ScienceQA
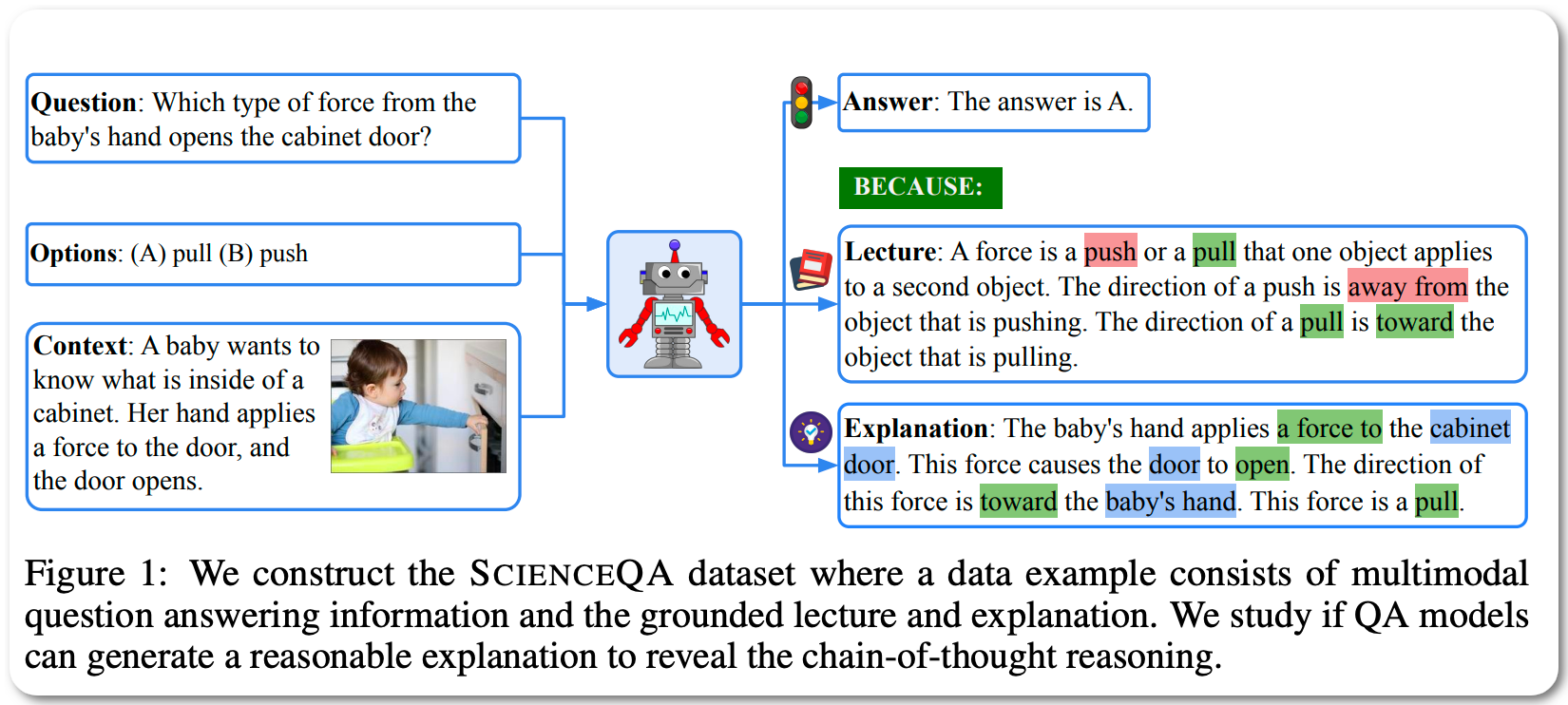
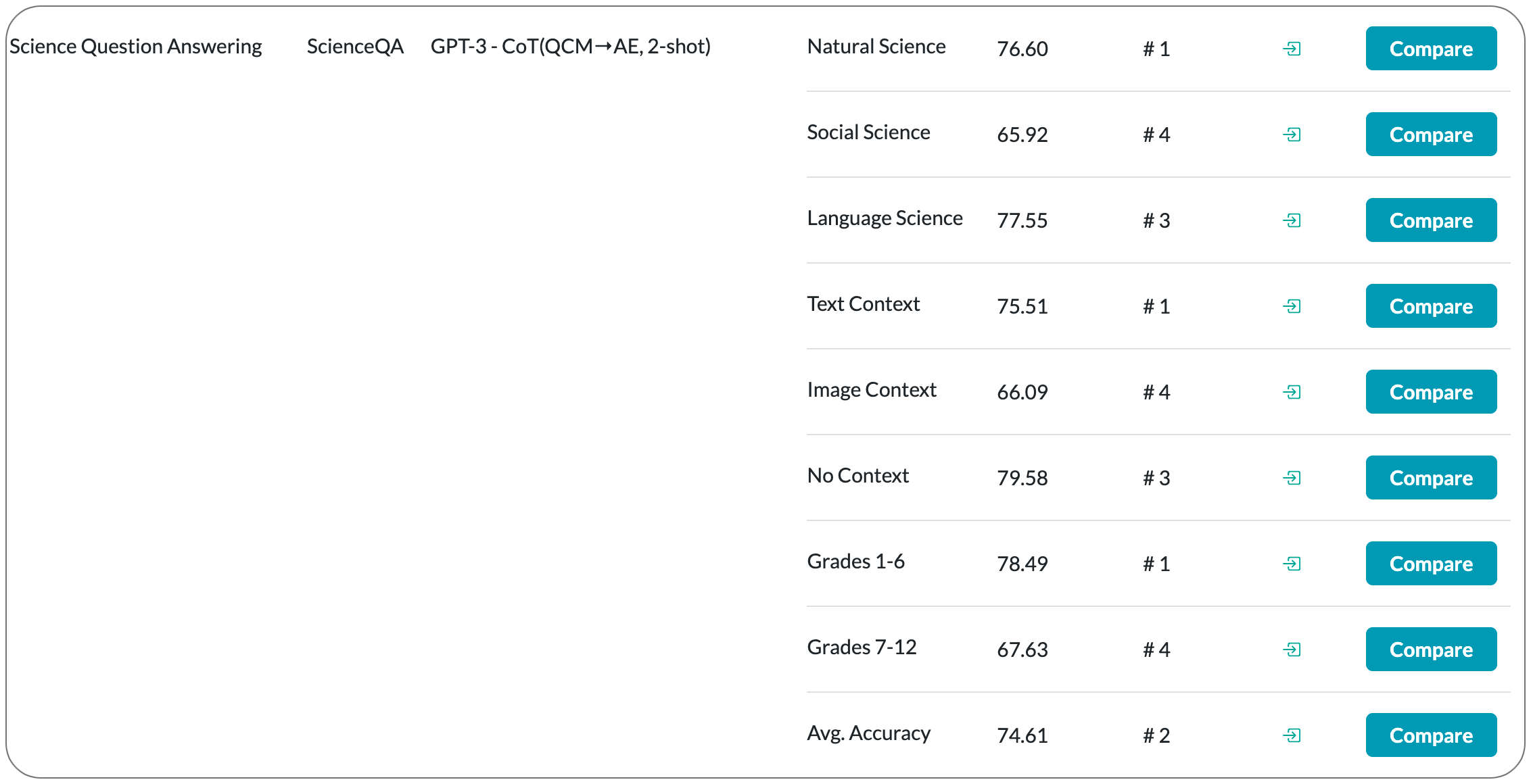
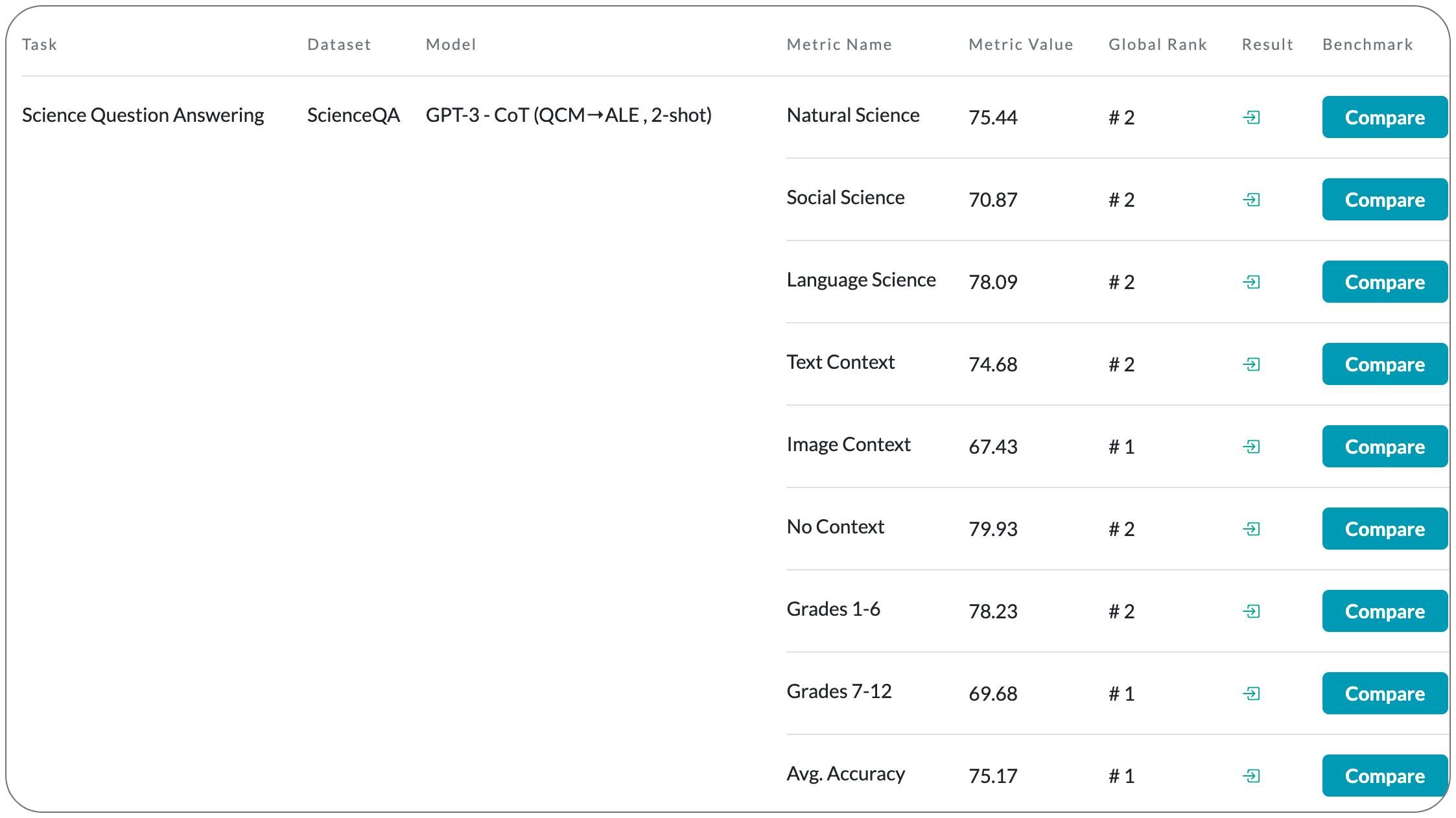

Model Name: GPT-3 - CoT (QCM→ALE , 2-shot)
Notes: When answering a question, humans utilize the information available across different modalities to synthesize a consistent and complete chain of thought (CoT). This process is normally a black box in the case of deep learning models like large-scale language models. Recently, science question benchmarks have been used to diagnose the multi-hop reasoning ability and interpretability of an AI system. However, existing datasets fail to provide annotations for the answers, or are restricted to the textual-only modality, small scales, and limited domain diversity. The paper introduces Science Question Answering (ScienceQA), a new benchmark that consists of ~21k multimodal multiple choice questions with a diverse set of science topics and annotations of their answers with corresponding lectures and explanations. They also tune a language model (GPT-3) to learn to generate lectures and explanations as the chain of thought (CoT) to mimic the multi-hop reasoning process when answering ScienceQA questions.
Demo page: Image captioning model. The fine tuned GPT-3 model access is not available. But the fine tuning data is available to create a fine-tuned GPT-3 model
License: non-commercial license. CC BY-NC-SA 4.0
#1 in Face Swapping on 2 datasets

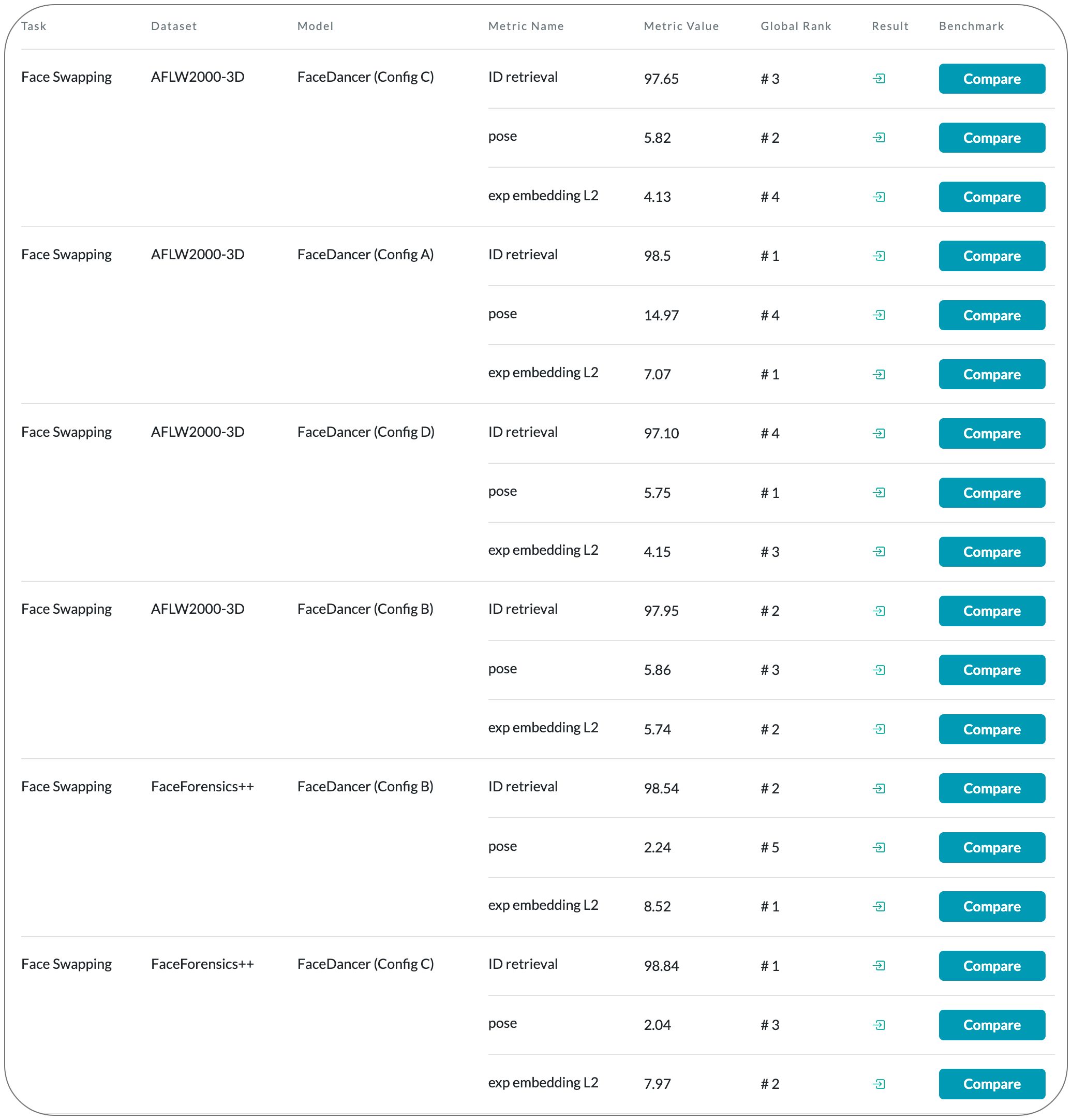

Model Name: FaceDancer (Config A)
Notes: This paper introduces a single-stage method for subject agnostic face swapping and identity transfer, named FaceDancer. This paper makes two contributions: Adaptive Feature Fusion Attention (AFFA) and Interpreted Feature Similarity Regularization (IFSR). The AFFA module is embedded in the decoder and adaptively learns to fuse attribute features and features conditioned on identity information without requiring any additional facial segmentation process. In IFSR, they leverage the intermediate features in an identity encoder to preserve important attributes such as head pose, facial expression, lighting, and occlusion in the target face, while still transferring the identity of the source face with high fidelity.
Demo page: HuggingFace space demo app
License: Non-commercial license
#1 in Graph Regression on PCQM4Mv2-LSC dataset

Model Name: Transformer-M
Notes: Unlike vision and language data which usually has a unique format, molecules can naturally be characterized using different chemical formulations. One can view a molecule as a 2D graph or define it as a collection of atoms located in a 3D space. For molecular representation learning, most previous works designed neural networks only for a particular data format, making the learned models likely to fail for other data formats. This work proposes a general-purpose neural network model for chemistry to handle molecular tasks across data modalities. They develop a novel Transformer-based Molecular model called Transformer-M, which can take molecular data of 2D or 3D formats as input and generate meaningful semantic representations. Using the standard Transformer as the backbone architecture, Transformer-M develops two separated channels to encode 2D and 3D structural information and incorporate them with the atom features in the network modules. When the input data is in a particular format, the corresponding channel will be activated, and the other will be disabled. By training on 2D and 3D molecular data with properly designed supervised signals, Transformer-M automatically learns to leverage knowledge from different data modalities and correctly capture the representations. Empirical results show that Transformer-M can simultaneously achieve strong performance on 2D and 3D tasks, suggesting its broad applicability.
Demo page: None to date
License: MIT license
#1 in Text summarization on 2 datasets
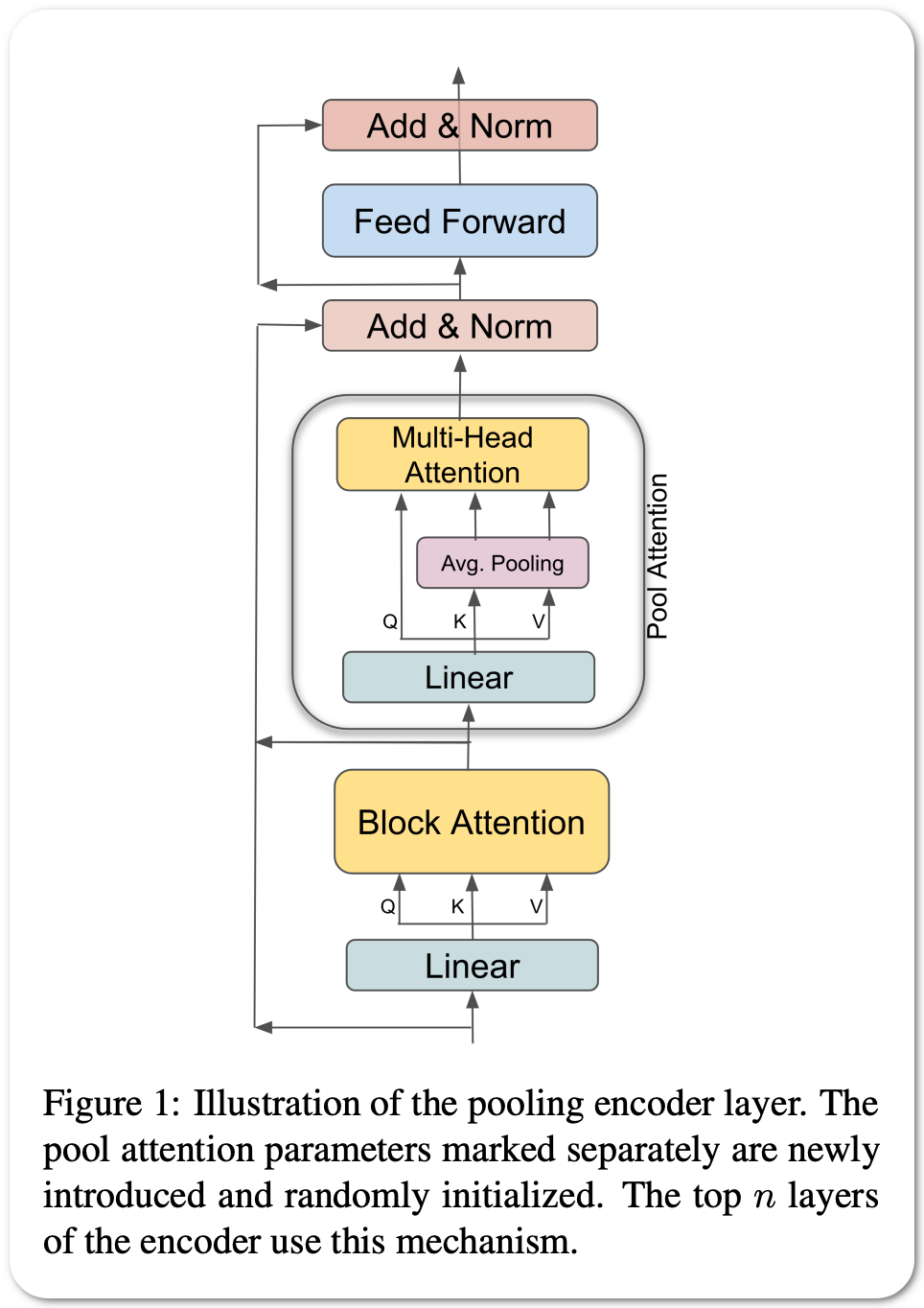
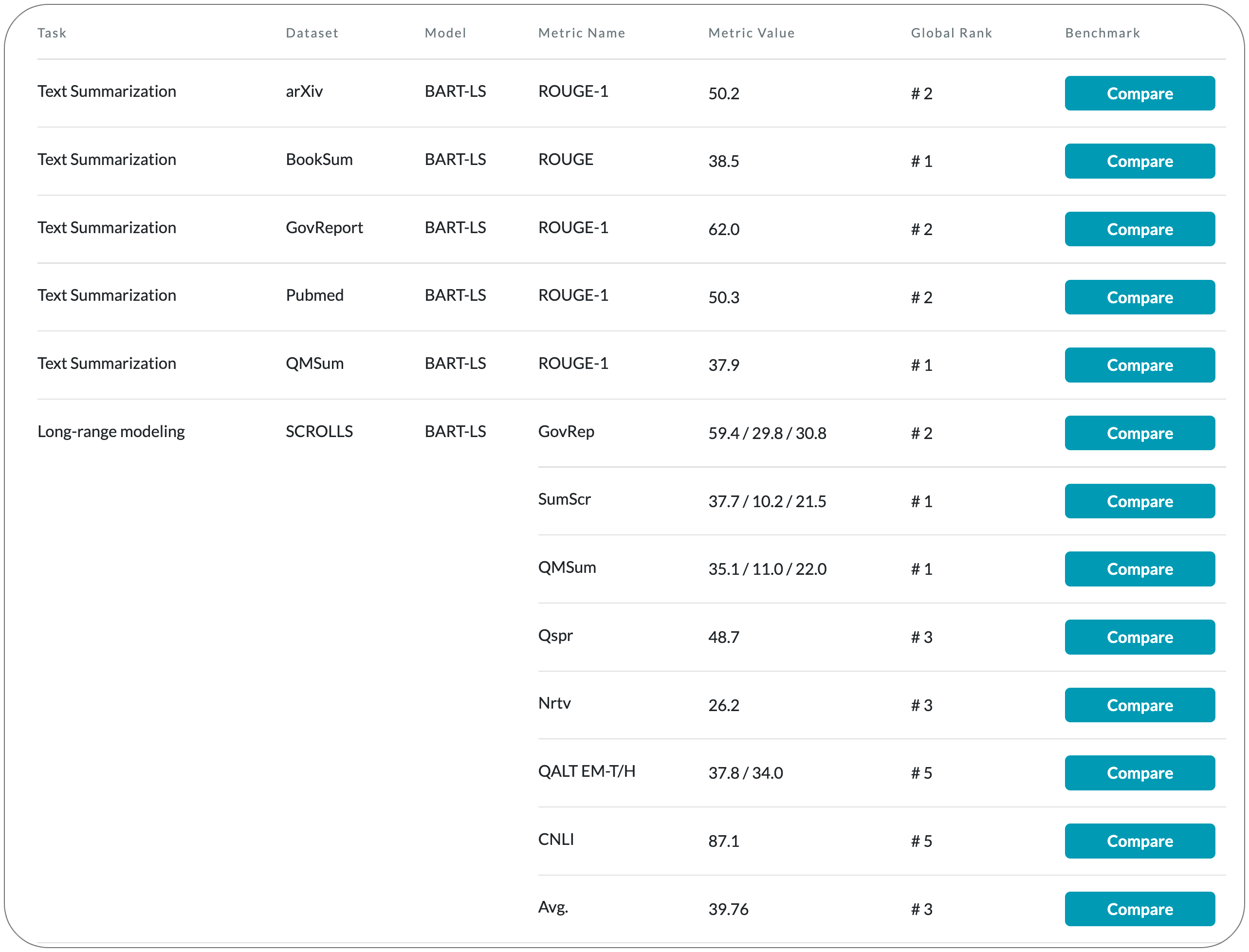

Model Name: BART-LS
Notes: This paper performs an empirical study of adapting an existing pretrained text-to-text model for long-sequence inputs. Through a comprehensive study along three axes of the pretraining pipeline -- model architecture, optimization objective, and pretraining corpus, they propose a recipe to build long-context models from existing short-context models. Specifically, they replace the full attention in transformers with pooling-augmented blockwise attention, and pretrain the model with a masked-span prediction task with spans of varying length. In terms of the pretraining corpus, they find that using randomly concatenated short-documents from a large open-domain corpus results in better performance than using existing long document corpora which are typically limited in their domain coverage. With these findings, they build a long-context model that achieves competitive performance on long-text QA tasks and establishes the new state of the art on five long-text summarization datasets, often outperforming previous methods with larger model sizes.
Demo page: None to date
License: Non commercial license. CC-BY-NC 4.0
#1 in Q&A and Riddle sense
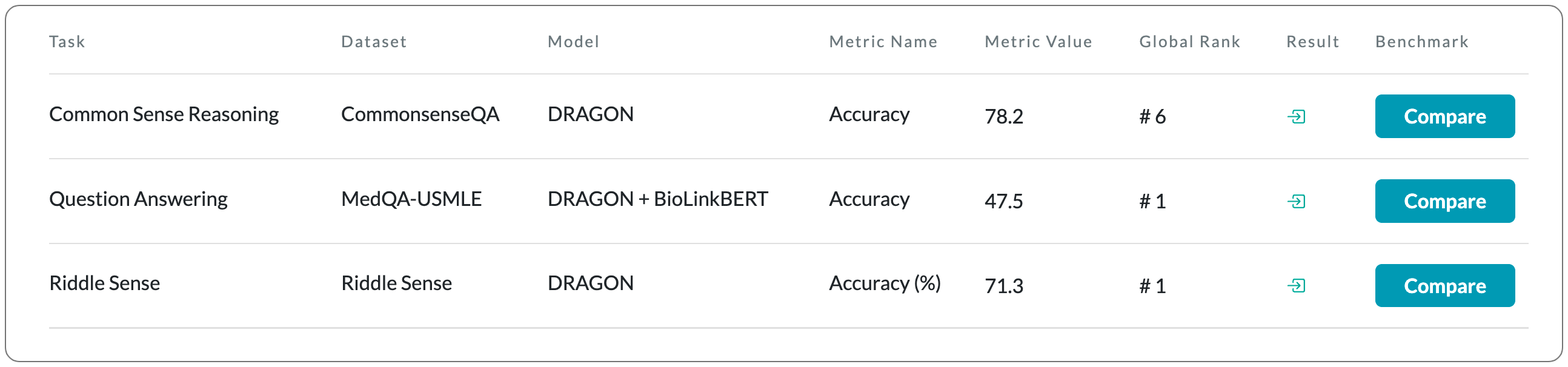

Model Name: DRAGON, DRAGON + BioLinkBERT
Notes: Pretraining a language model (LM) on text has been shown to help various downstream NLP tasks. Recent work has shown that a knowledge graph (KG) can complement text data, offering structured background knowledge that provides a useful scaffold for reasoning. However, these models are not pretrained to learn a deep fusion of the two modalities at scale, limiting the potential to acquire fully joint representations of text and KG. This paper proposes DRAGON (Deep Bidirectional Language-Knowledge Graph Pretraining), a self-supervised approach to pretraining a deeply joint language-knowledge foundation model from text and KG at scale. Specifically, the model takes pairs of text segments and relevant KG subgraphs as input and bidirectionally fuses information from both modalities. This model is pretrained by unifying two self-supervised reasoning tasks, masked language modeling and KG link prediction.
Demo page: None to date
License: Apache-2.0 license
#1 in Semantic correspondence on PF-PASCAL dataset



Model Name: CATS++
Notes: Cost aggregation is a highly important process in image matching tasks, which aims to disambiguate the noisy matching scores. Existing methods generally tackle this by hand-crafted or CNN-based methods, which either lack robustness to severe deformations or inherit the limitation of CNNs that fail to discriminate incorrect matches due to limited receptive fields and lack of adaptability. This paper introduces Cost Aggregation with Transformers (CATs) to tackle this by exploring global consensus among initial correlation map with the help of some architectural designs that allows it to fully enjoy global receptive fields of self-attention mechanism. Also, to alleviate some of the limitations that CATs may face, i.e., high computational costs induced by the use of a standard transformer that its complexity grows with the size of spatial and feature dimensions, which restrict its applicability only at limited resolution and result in rather limited performance, this paper propose CATs++, an extension of CATs. The proposed methods outperform the previous state-of-the-art methods by large margins.
Demo page: None to date
License: This code based is based on three models that have the following commercial use licenses. Apache-2.0 license and GNU GPL 3.0 license
#1 in Occluded Object detection (instance segmentation) on COCO dataset

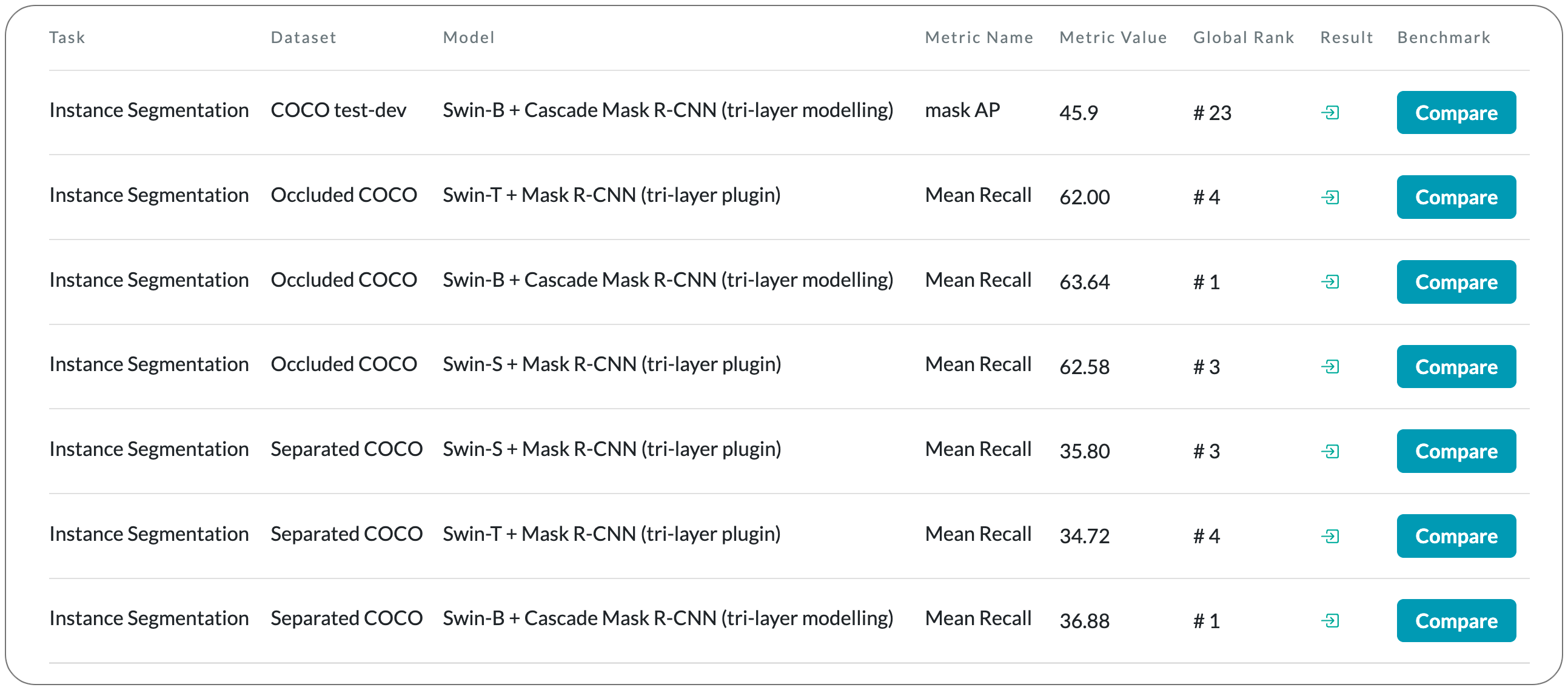

Model Name: Swin-B + Cascade Mask R-CNN (tri-layer modelling)
Notes: This paper addresses the problem of detecting occluded objects.
It makes four contributions to solve this problem : (1) a simple 'plugin' module for the detection head of two-stage object detectors to improve the recall of partially occluded objects. The module predicts a tri-layer of segmentation masks for the target object, the occluder and the occludee, and by doing so is able to better predict the mask of the target object. (2) a scalable pipeline for generating training data for the module by using amodal completion of existing object detection and instance segmentation training datasets to establish occlusion relationships. (3) They establish a COCO evaluation dataset to measure the recall performance of partially occluded and separated objects. (4) they show that the plugin module inserted into a two-stage detector can boost the performance significantly, by only fine-tuning the detection head, and with additional improvements if the entire architecture is fine-tuned.
Demo page: None to date. Project page has additional examples
License: Apache-2.0 license - commercial use permitted
#1 in Continual pretraining on AG News dataset
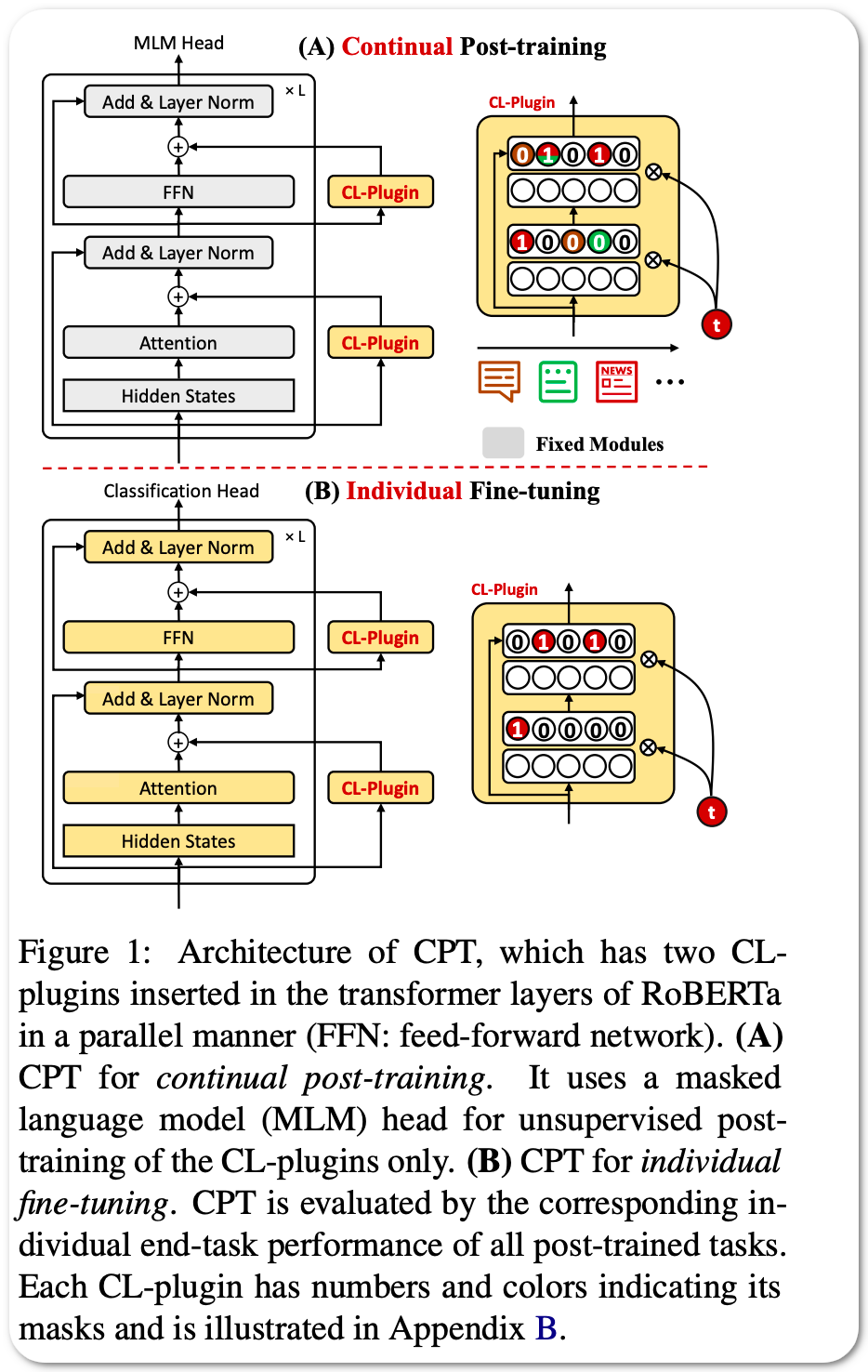


Model Name: CPT
Notes: Recent work on applying large language models (LMs) achieves impressive performance in many NLP applications. Adapting or posttraining an LM using an unlabeled domain corpus can produce even better performance for end-tasks in the domain. This paper proposes the problem of continually extending an LM by incrementally post-train the LM with a sequence of unlabeled domain corpora to expand its knowledge without forgetting its previous skills. The goal is to improve the few-shot end-task learning in these domains. The resulting system is called CPT (Continual PostTraining) claims to be the first continual post-training system.
Demo page: None to date
License: None to date
#1 in self-supervised image classification on Imagenet (fine tuned)
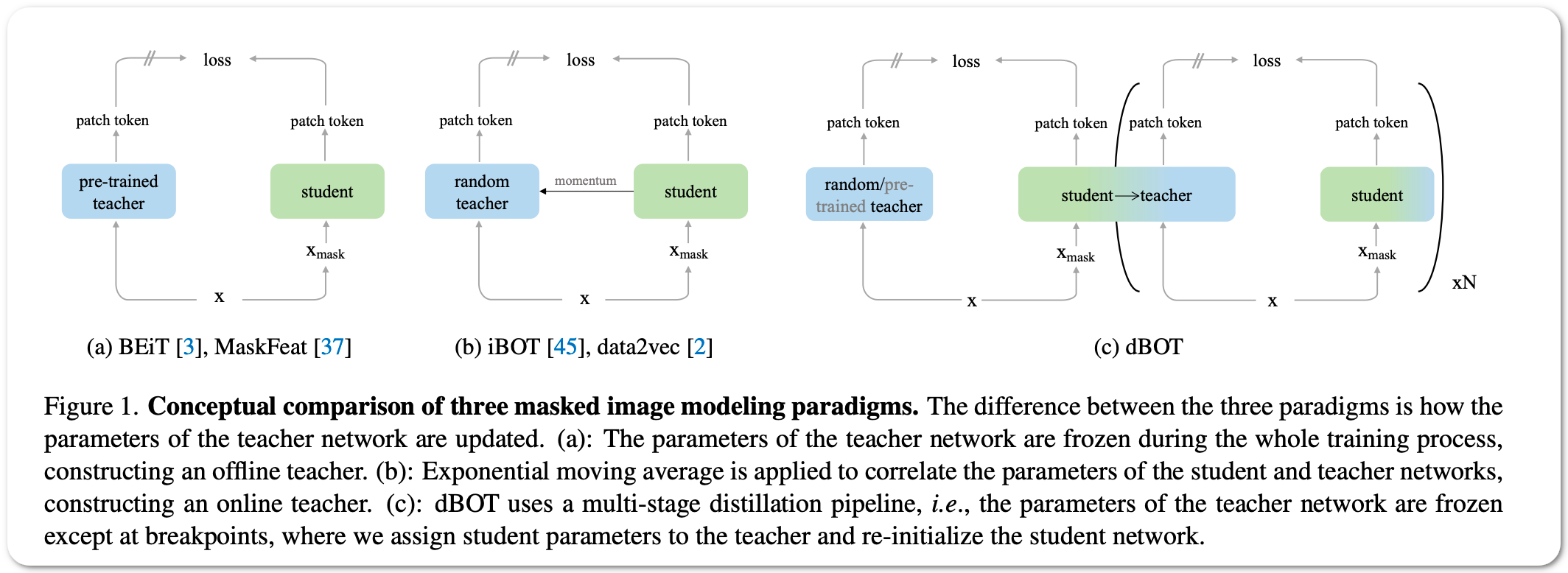


Model Name: dBOT
Notes: Masked autoencoders randomly mask a portion of the input and reconstruct the masked portion according to the target representations. This paper first shows that a careful choice of the target representation (tokenized version of images using DALL-E - offline teacher - in the case of BeIT or image pixels in the case of MAE) is unnecessary for learning good representations, since different targets tend to derive similarly behaved models. Driven by this observation, we propose a multi-stage masked distillation pipeline and use a randomly initialized model as the teacher, enabling us to effectively train high-capacity models without any efforts to carefully design target representations. Interestingly, we further explore using teachers of larger capacity, obtaining distilled students with remarkable transferring ability. On different tasks of classification, transfer learning, object detection, and semantic segmentation, the proposed method to perform masked knowledge distillation with bootstrapped teachers (dBOT) outperforms previous self-supervised methods by nontrivial margins.
Demo page: None to date
License: Apache-2.0 license