TWC #8

state-of-the-art (SOTA) updates for 19 Sept– 25 Sept 2022
TasksWithCode weekly newsletter highlights the work of researchers who share their SOTA paper, code, as well models in most cases, and demo apps in few cases. This weekly is a consolidation of daily twitter posts tracking SOTA changes.
To date, 26.9 % (85,795) of total papers (318,449) published have code released along with the papers (source)
SOTA updated last week for the following tasks
- Domain generalization
- Video retrieval
- Scene graph generation
- Predicting next action
- Remote sensing
- Semantic segmentation
- Long-range modeling
- Graph matching
- Fine-grained image classification
#1 in Domain Generalization on ImageNet-C
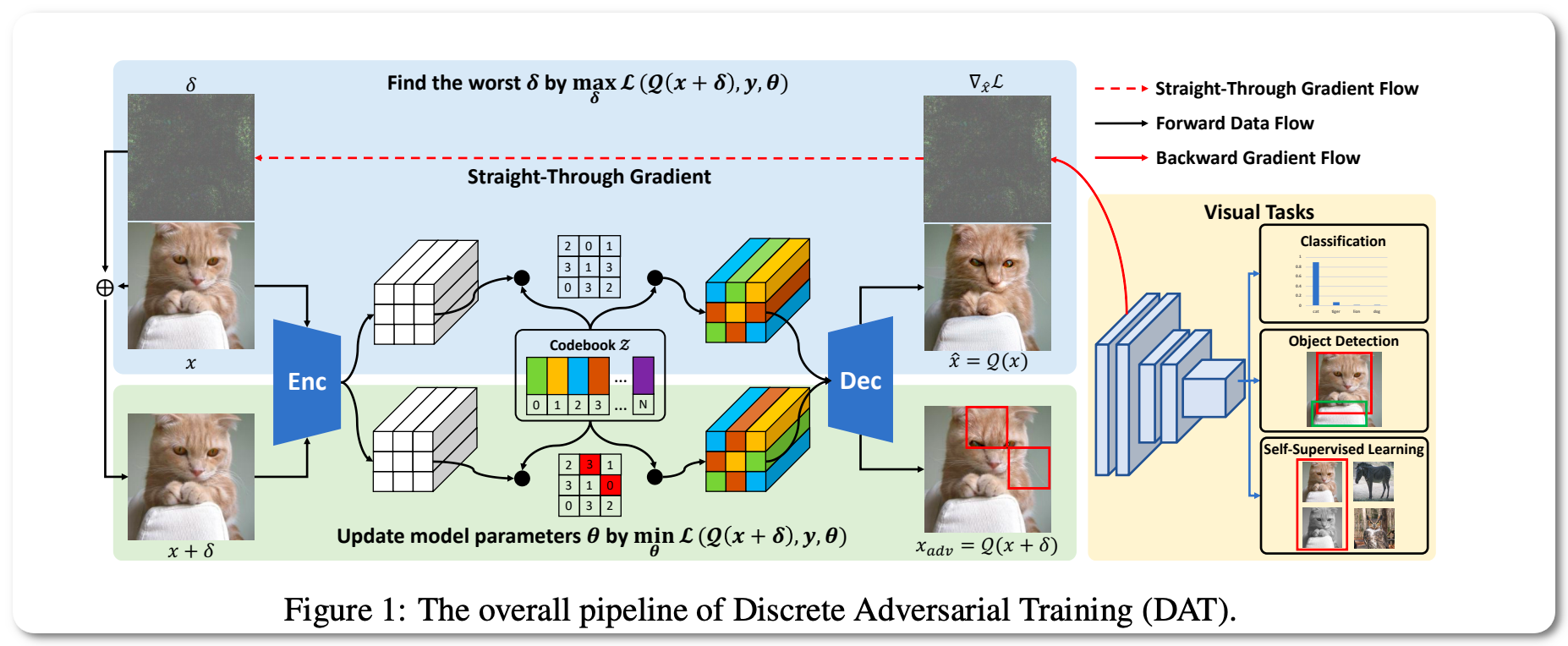
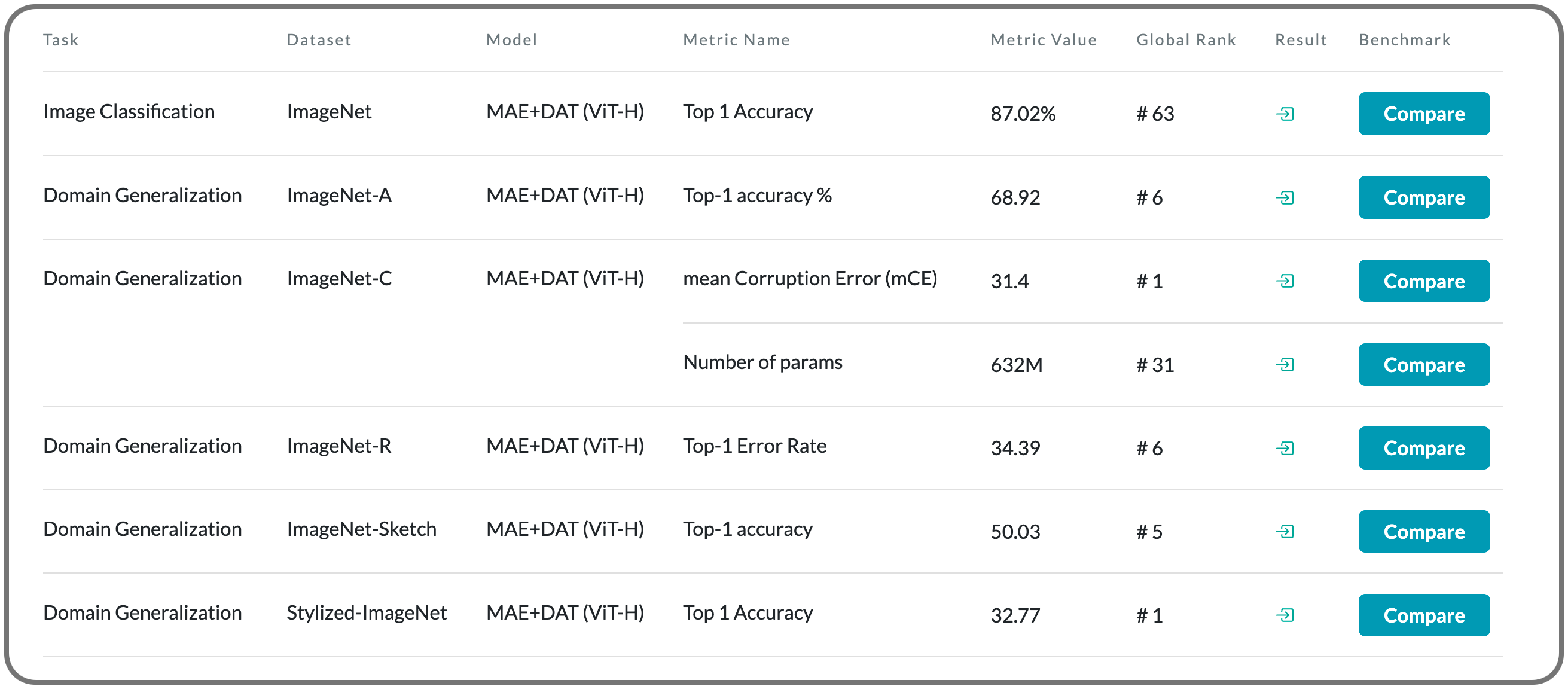

Notes: This model leverages VQGAN to reform the image data to discrete text-like inputs, i.e. visual words. Then it minimizes the maximal risk on such discrete images with symbolic adversarial perturbations.
Model Name: MAE+DAT
Demo page link None to date
License: Apache license
#1 in Video retrieval on 15 datasets
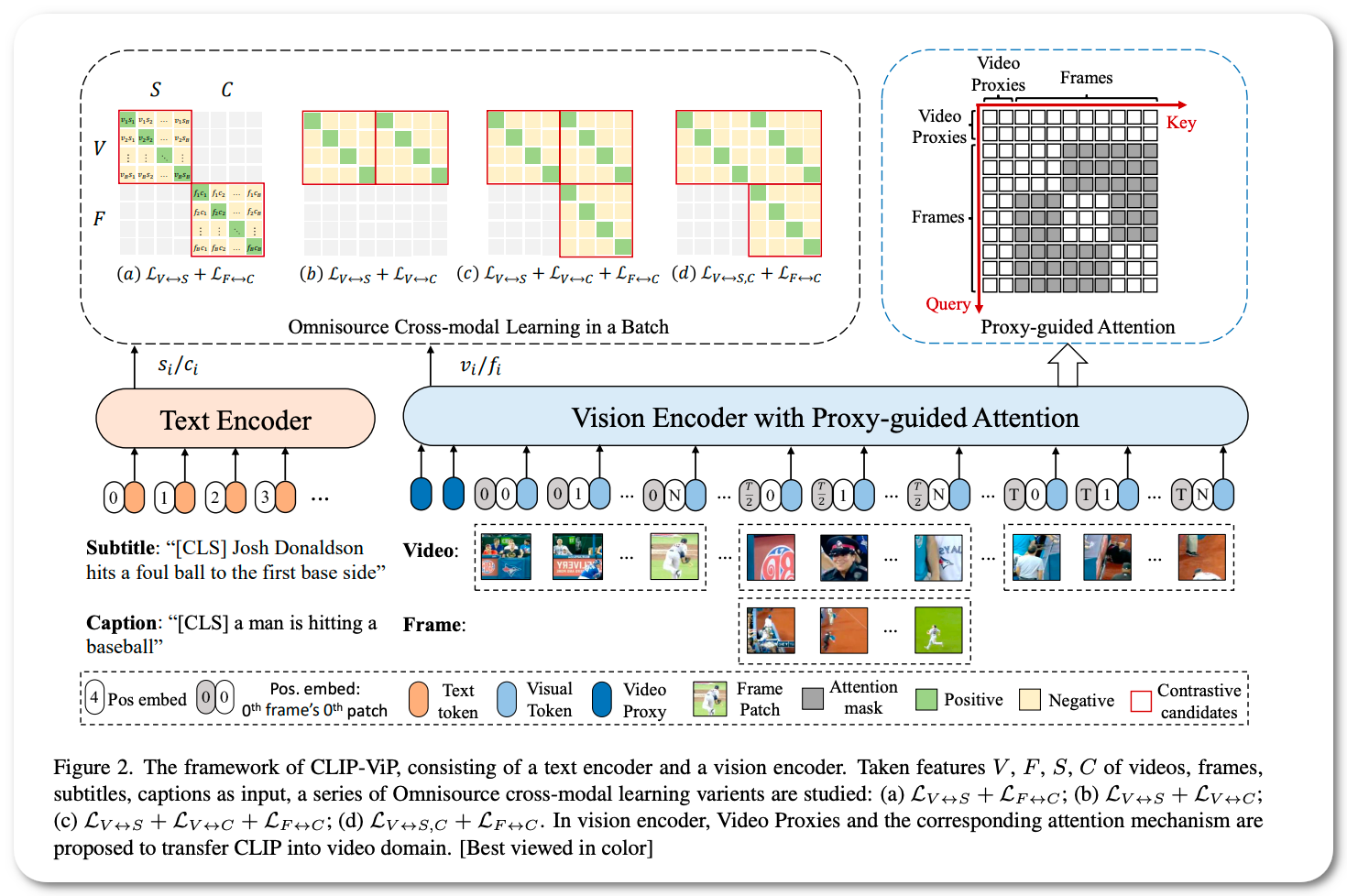
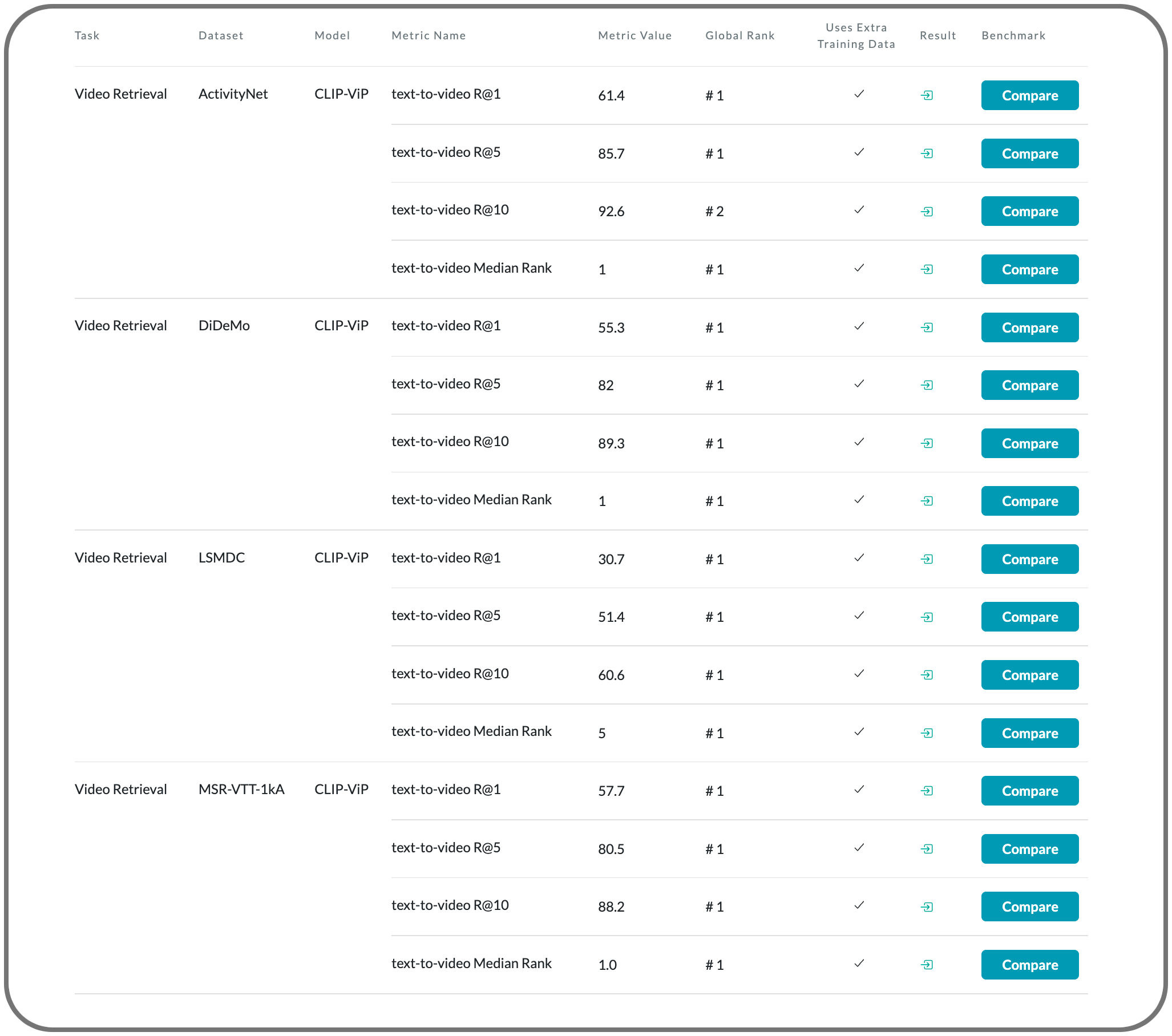

Notes: This paper investigates two questions: 1) what are the factors hindering post-pretraining CLIP to further improve the performance on video-language tasks? and 2) how to mitigate the impact of these factors? This paper reports that the data scale and domain gap between language sources have great impacts. The paper propose a Omnisource Cross-modal Learning method equipped with a Video Proxy mechanism on the basis of CLIP, namely CLIP-ViP.
Model Name: CLIP-ViP
Model link: Model not released to date
Demo page link None to date
License: MIT license
#1 in scene graph generation on 11 datasets
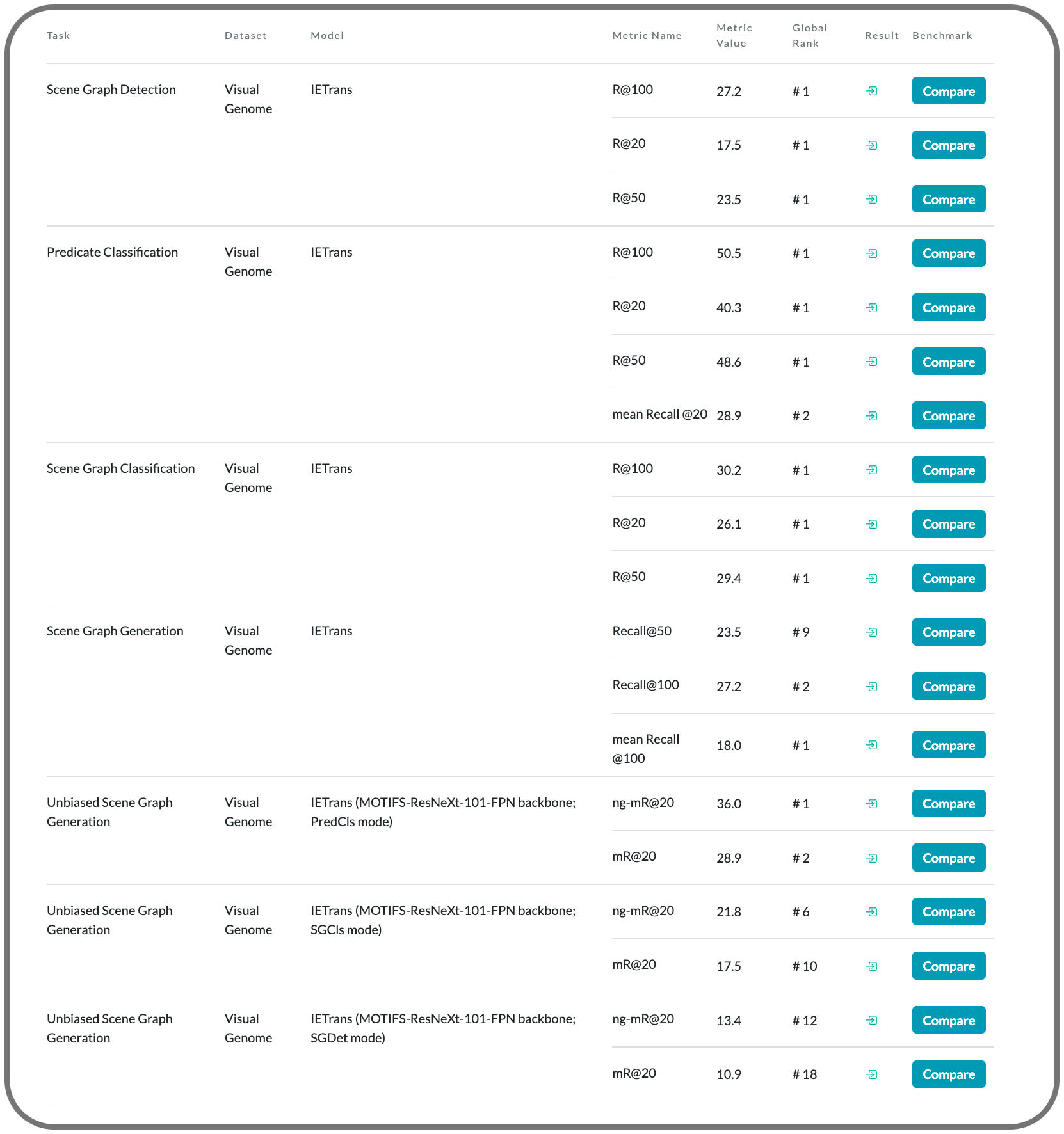

Notes: This paper proposes a solution to relieve the data distribution problem by automatically creating an enhanced dataset that provides more sufficient and coherent annotations for all predicates. By training on the enhanced dataset, a Neural Motif model doubles the macro performance while maintaining competitive micro performance.
Model Name: IETrans (MOTIFS-ResNeXt-101-FPN backbone; PredCls mode)
Demo page link Python notebook
License: MIT license
#1 in next action prediction on 12 datasets
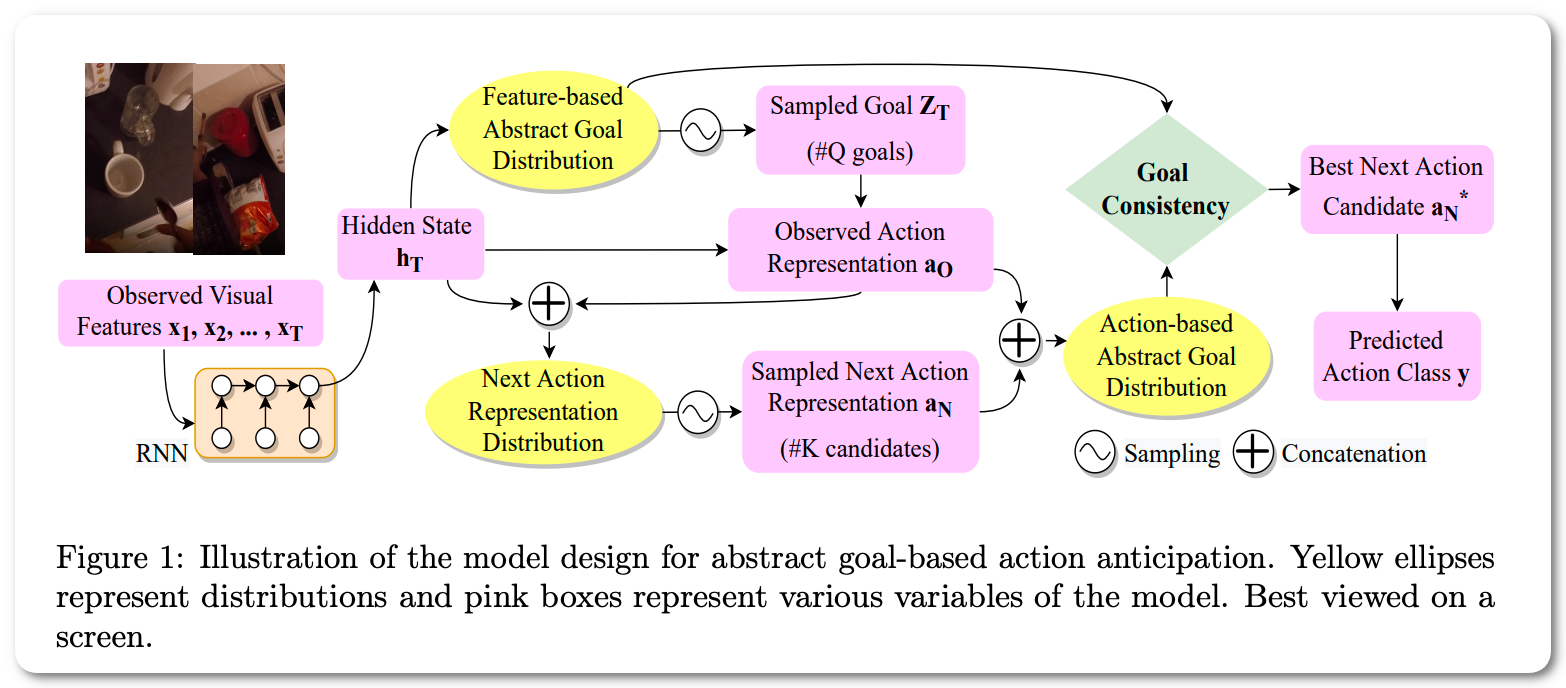
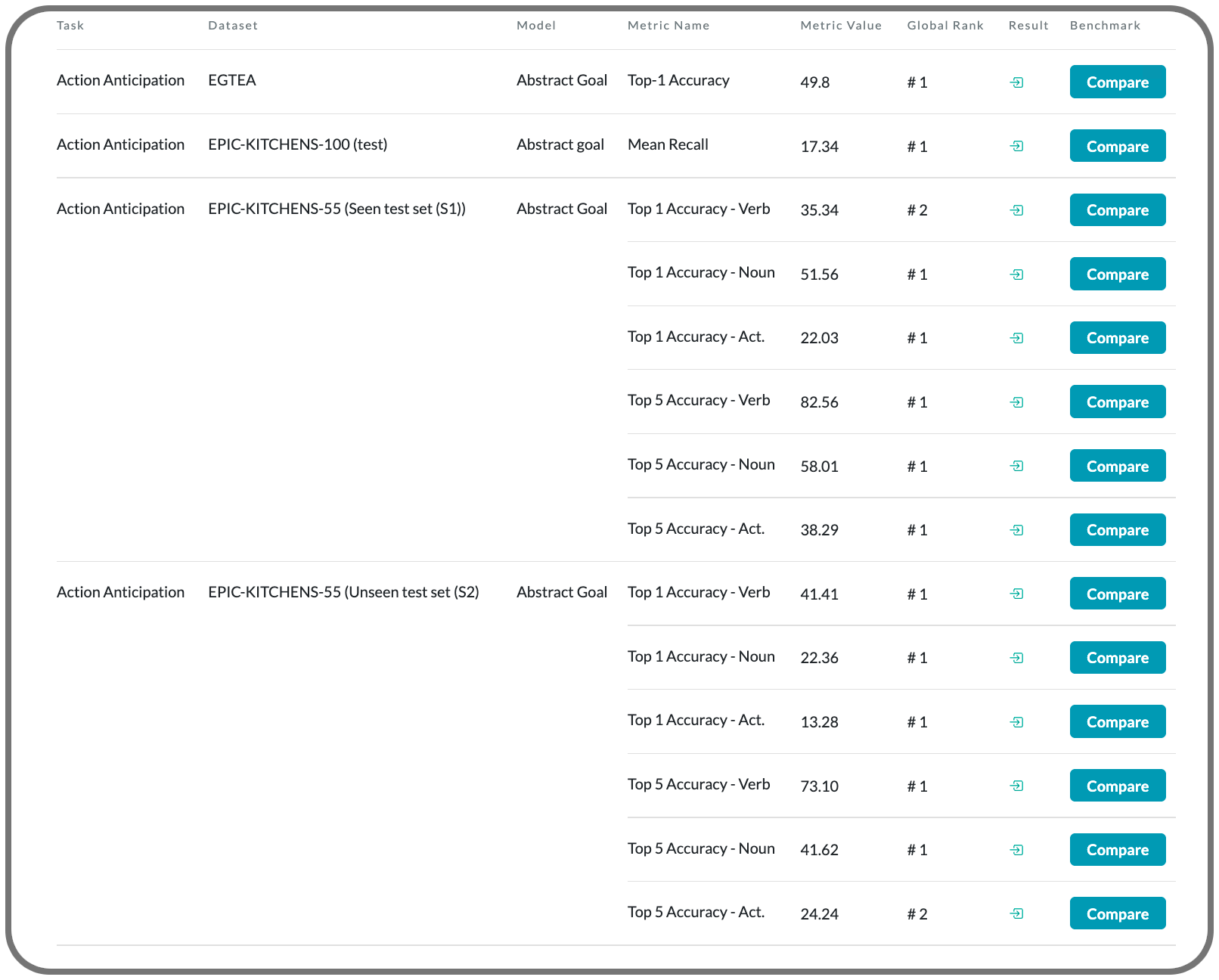

Notes: This paper proposes an action anticipation model that leverages goal information for the purpose of reducing the uncertainty in future predictions. Instead of relying on goal information or the observed actions during inference, the approach uses visual representation to encapsulate information about both actions and goals. Through this, they derive a novel concept called abstract goal which is conditioned on observed sequences of visual features for action anticipation.
Model Name: Abstract Goal
Model link: not released to date
Demo page link None to date
License: None to date
#1 in remote sensing on LEVIR-CD on two datasets
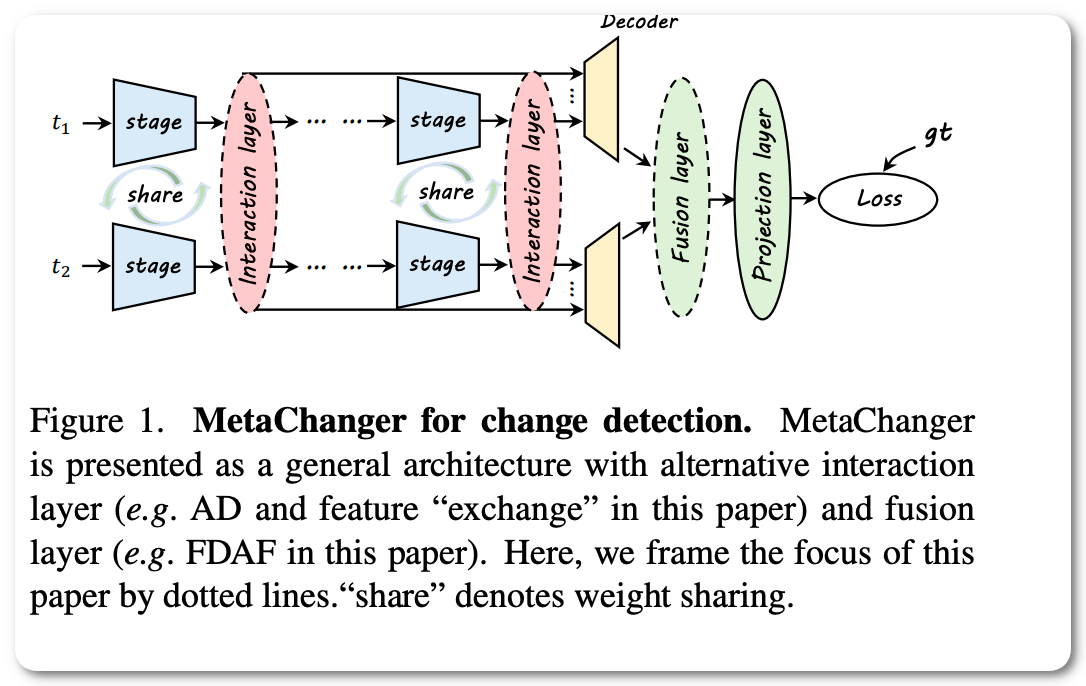
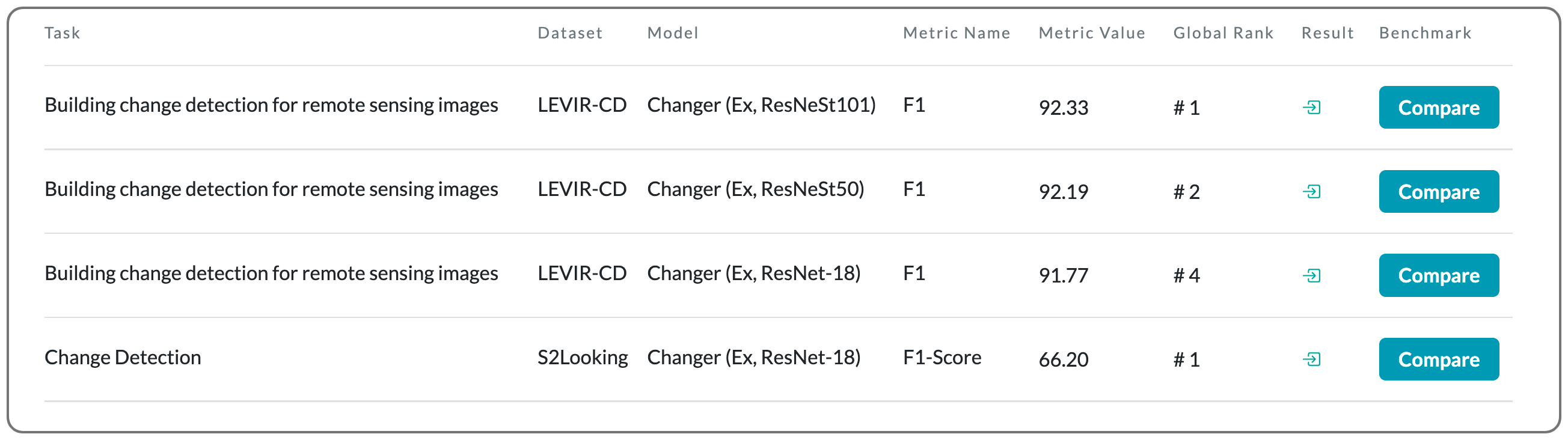

Notes: The model proposed in this paper takes bi-temporal images as input and predicts "where" the change has occurred. This paper proposes a general change detection architecture, which includes a series of alternative interaction layers in the feature extractor.
Model Name: Changer (Ex, ResNeSt101)
Model link: Not released to date
Demo page link None to date
License: Apache license - commercial use permitted
#1 in Semantic Segmentation on PASCAL VOC 2012 test
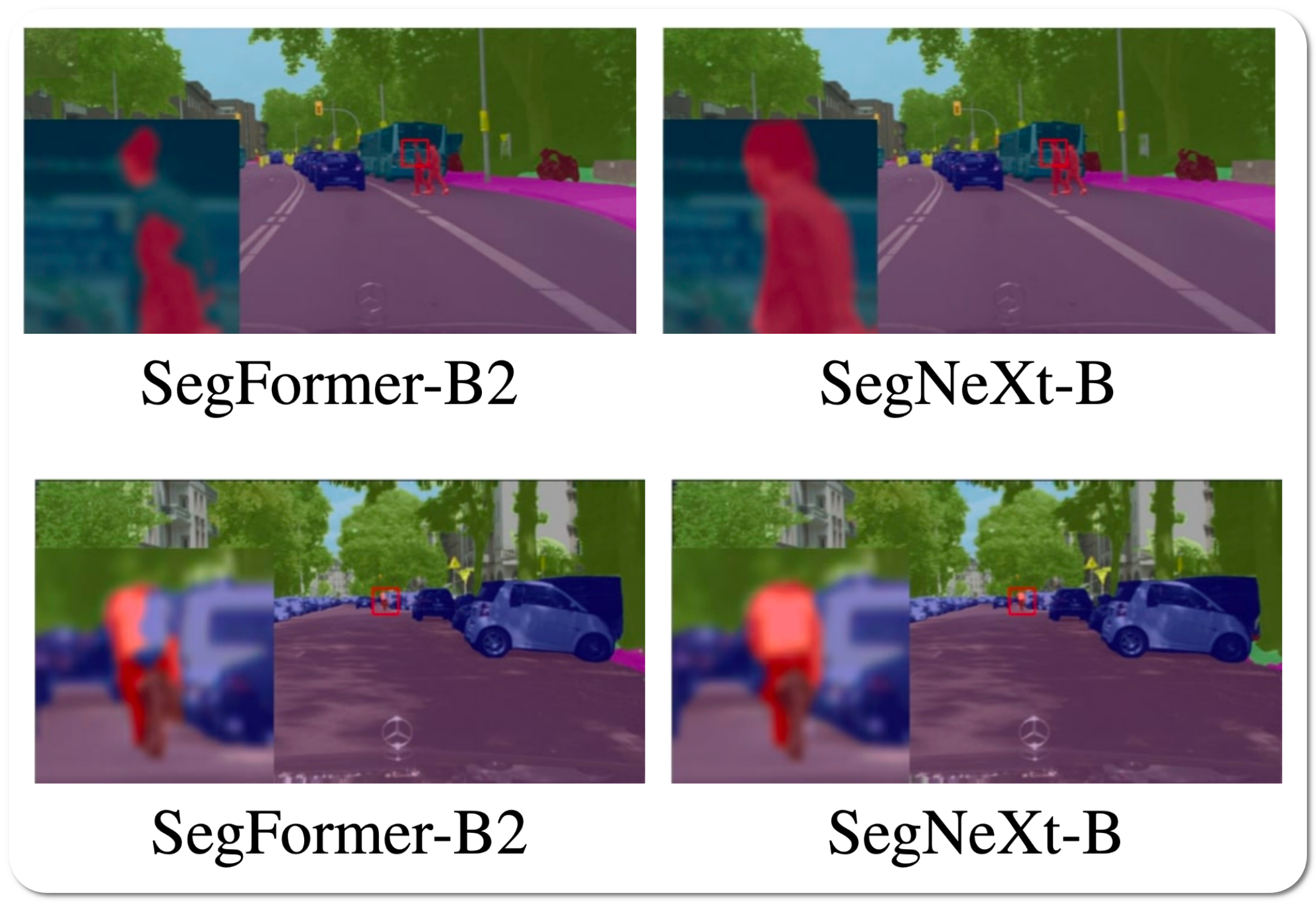
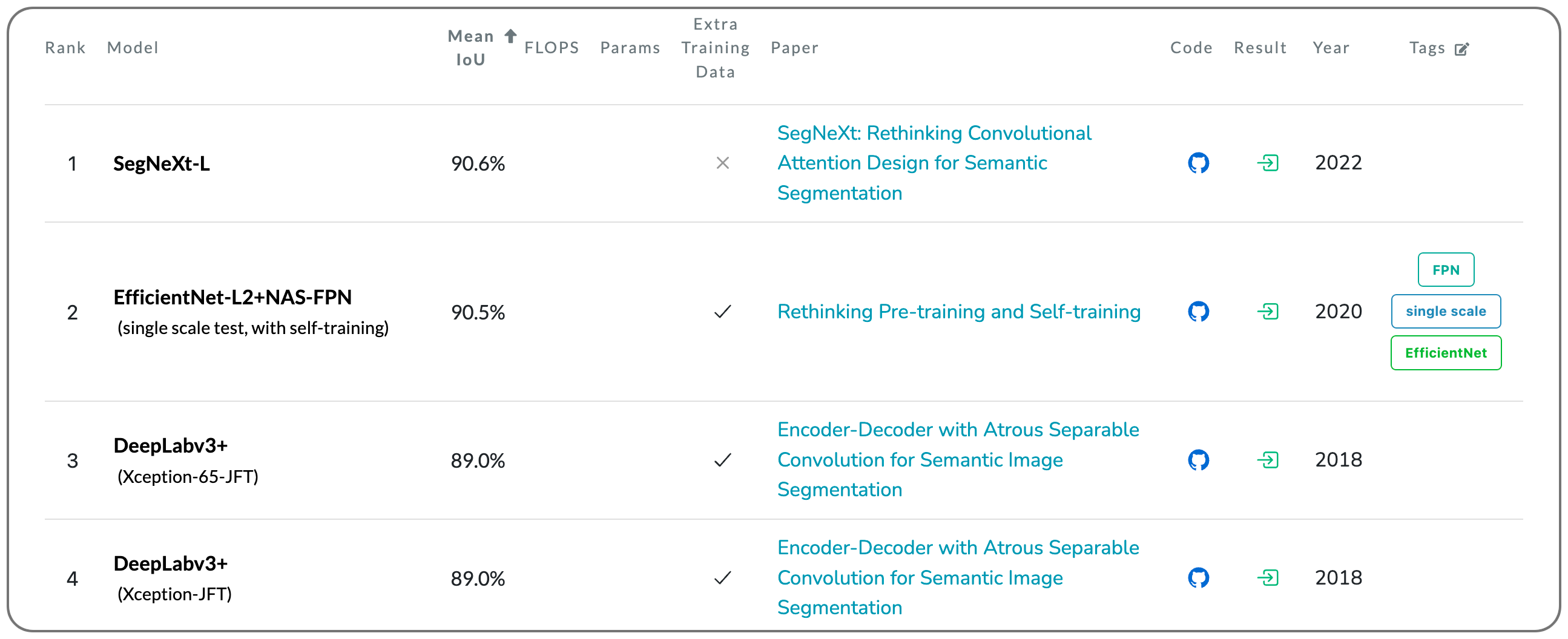

Model name: SegNeXt-L
Notes: This paper proposes a simple convolutional network architecture for semantic segmentation. This paper attempts to show that convolutional attention is a more efficient and effective way to encode contextual information than the self-attention mechanism in transformers. By re-examining the characteristics owned by successful segmentation models, they discover several key components leading to the performance improvement of segmentation models. They use this learning to design a novel convolutional attention network that uses cheap convolutional operations.
Demo page link None to date
License: For commercial use, author permission required
#1 in Long-range modeling on LRA dataset
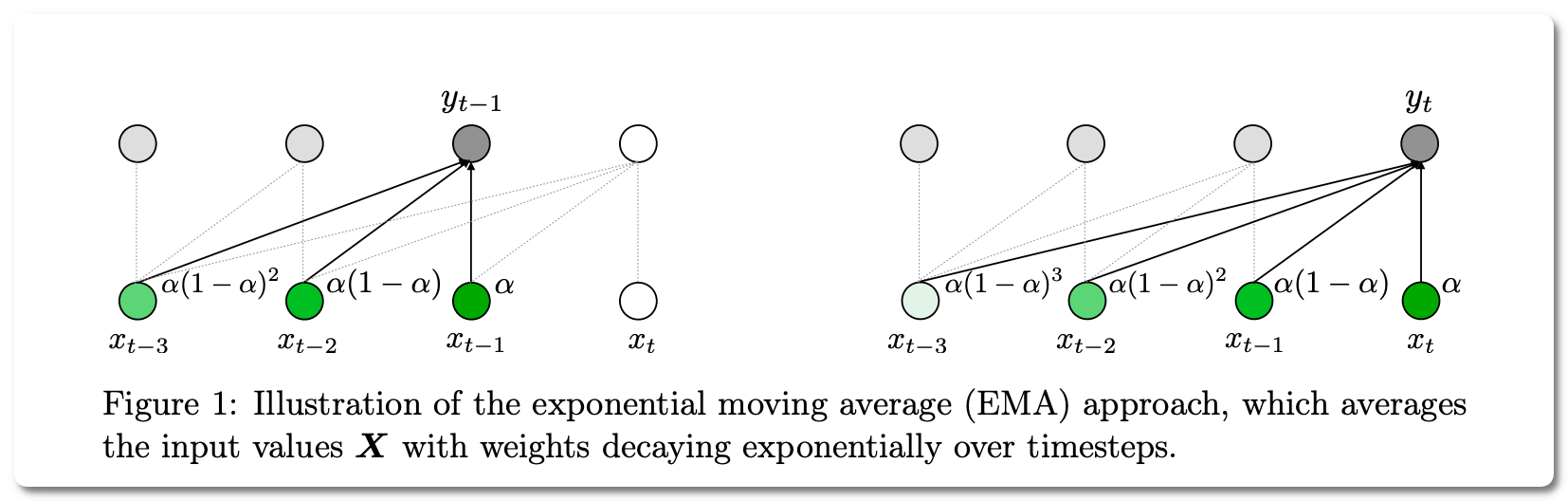
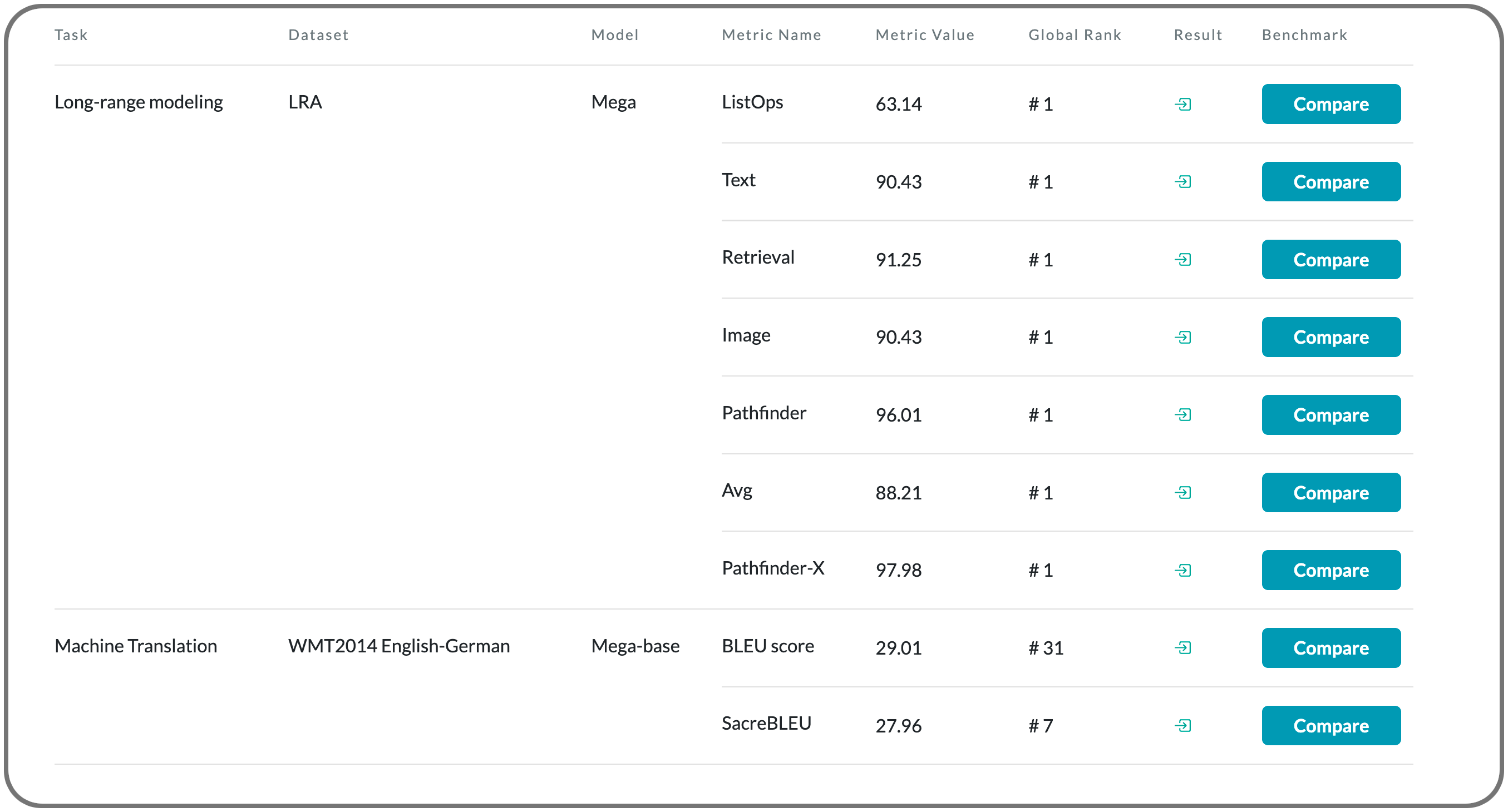

Model Name:Mega
Notes: The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. This paper introduces a theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. The paper also explores a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length.
Demo page link None to date
License: MIT license
#1 in Graph matching on SPair-71k dataset

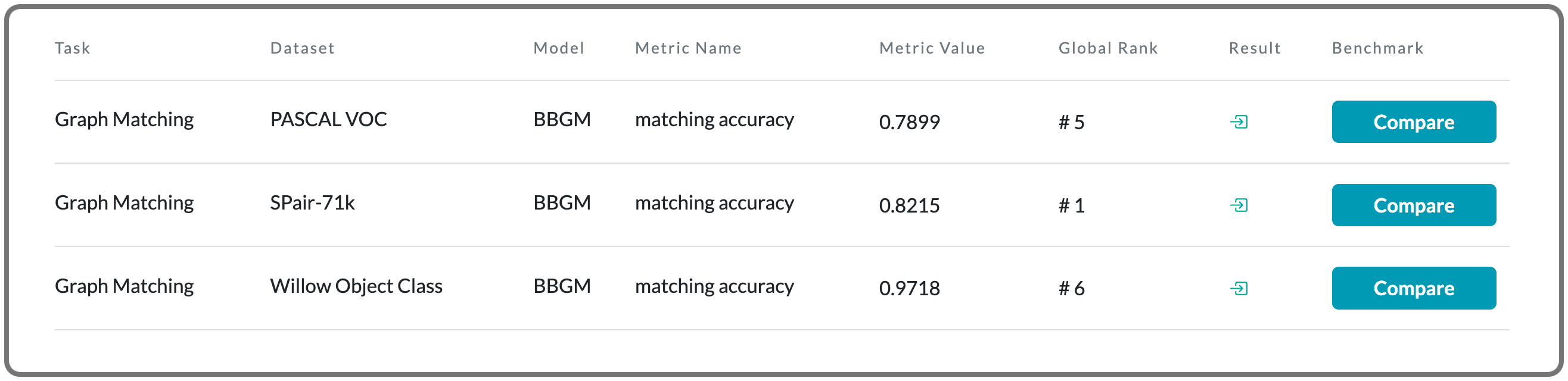

Model Name: BBGM
Notes: This paper proposes an end-to-end trainable architecture for deep graph matching that contains unmodified combinatorial solvers. In addition, this paper highlight the conceptual advantages of incorporating solvers into deep learning architectures, such as the possibility of post-processing with a strong multi-graph matching solver or the indifference to changes in the training setting.
Demo page link None to date
License: Mulan permissive license
#1 SOTA in fine-grained image classification on 6 datasets
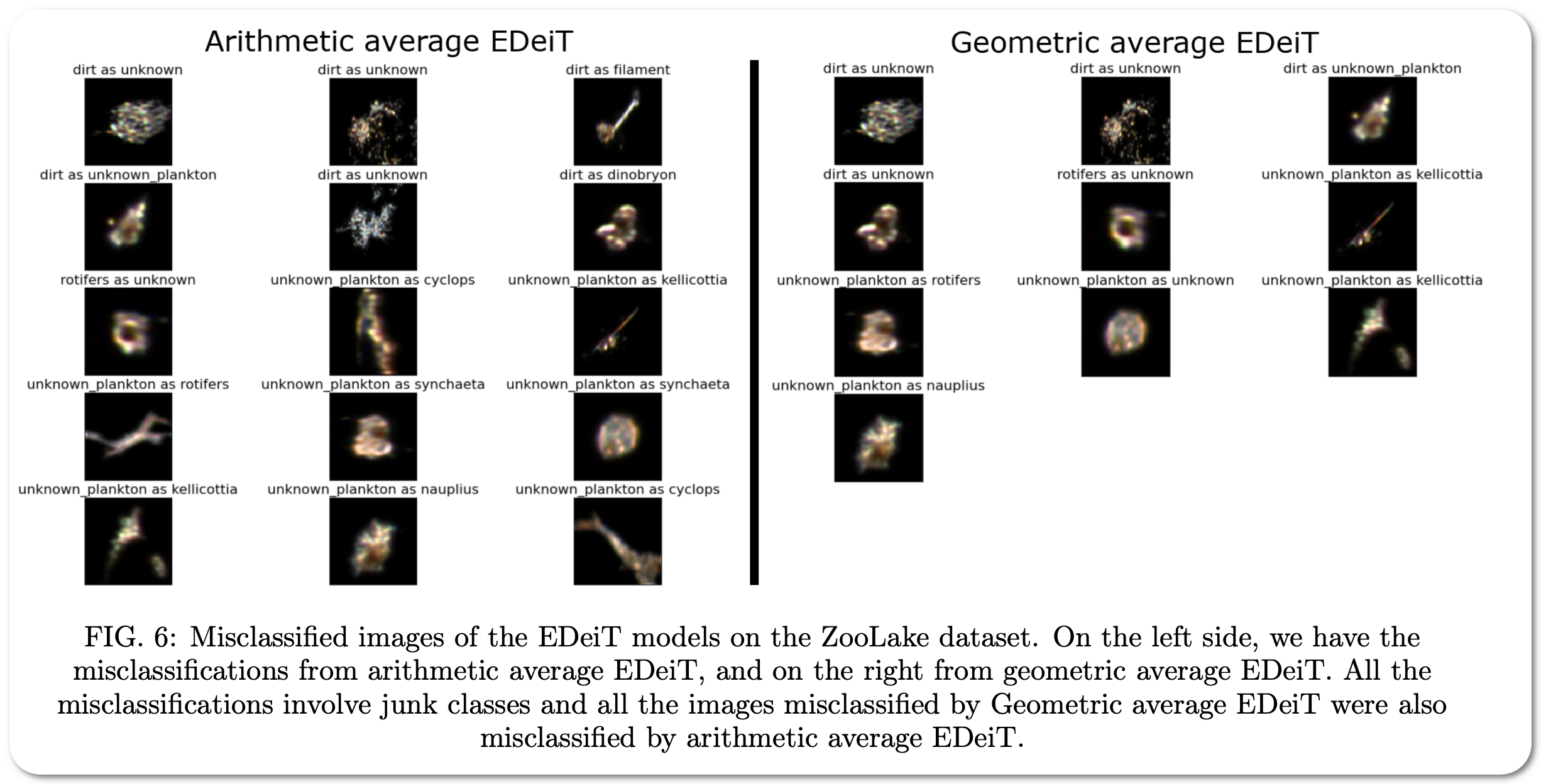
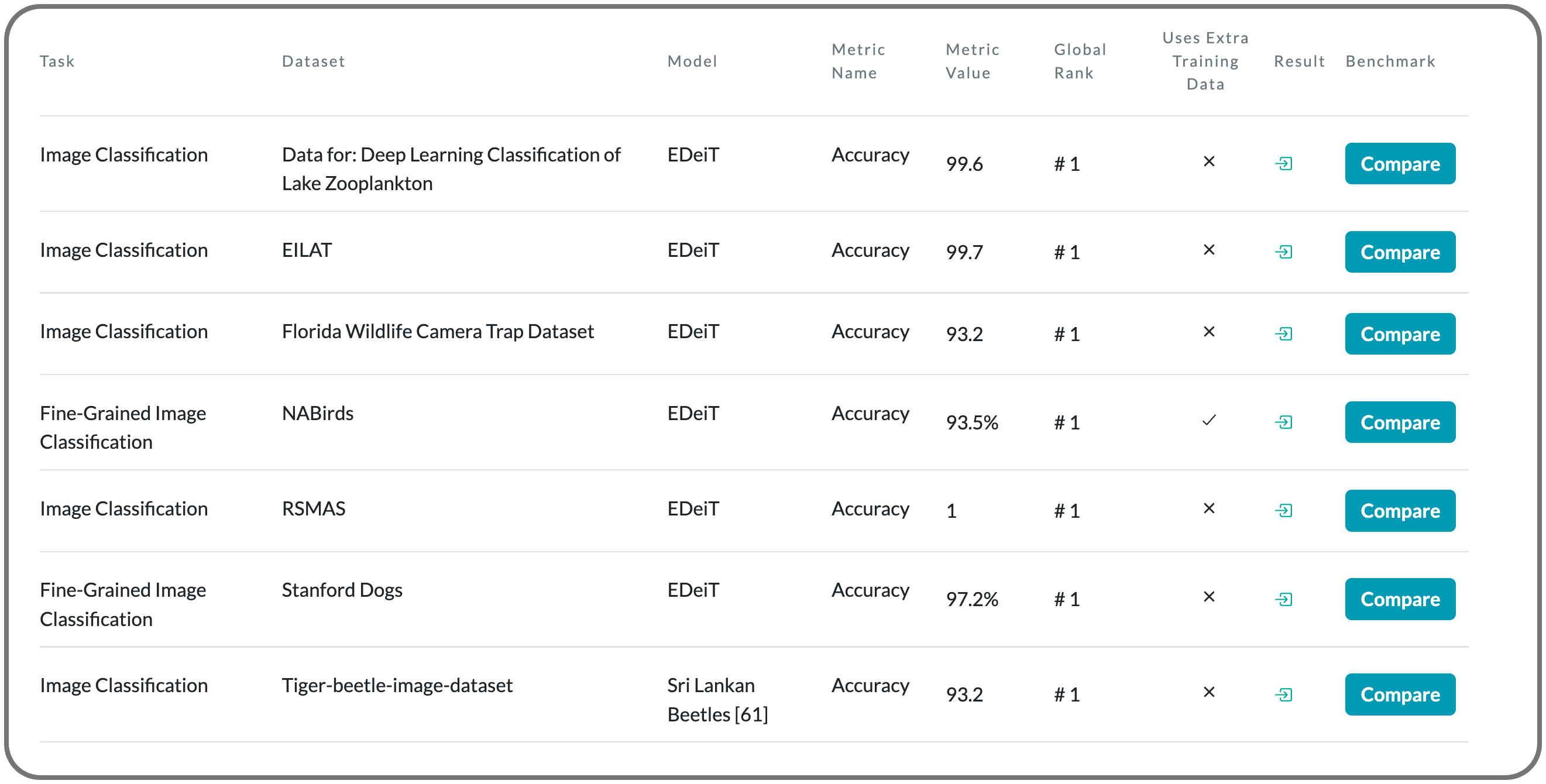

Model Name: EDeiT
Notes: The paper proposed to address the limitation of imprecision in classifiers by ensembles of Data-efficient image Transformers (DeiTs). They validate their results on a large number of ecological imaging datasets of diverse origin, and organisms of study ranging from plankton to insects, birds, dog breeds, animals in the wild, and corals. They achieve a new SOTA, with a reduction of the error with respect to the previous SOTA ranging from 18.48% to 87.50%, depending on the data set, and often achieving performances very close to perfect classification. The main reason why ensembles of DeiTs perform better is not due to the single-model performance of DeiTs, but rather to the fact that predictions by independent models have a smaller overlap, and this maximizes the profit gained by ensembling.
License: Not specified to date