TWC issue #4

SOTA updates between 22–28 August 2022
- Image captioning
- Visual Q&A and Visual reasoning
- Video Object detection
- Motion Blur removal
- Skeleton based action recognition
- Semantic segmentation for remote sensing (aerial views)
- Entity typing, entity linking & entity disambiguation
- Facial expression recognition
This post is a consolidation of daily twitter posts tracking SOTA changes.
Official code release (with pre-trained models in most cases) also available for these tasks
#1 in Image captioning

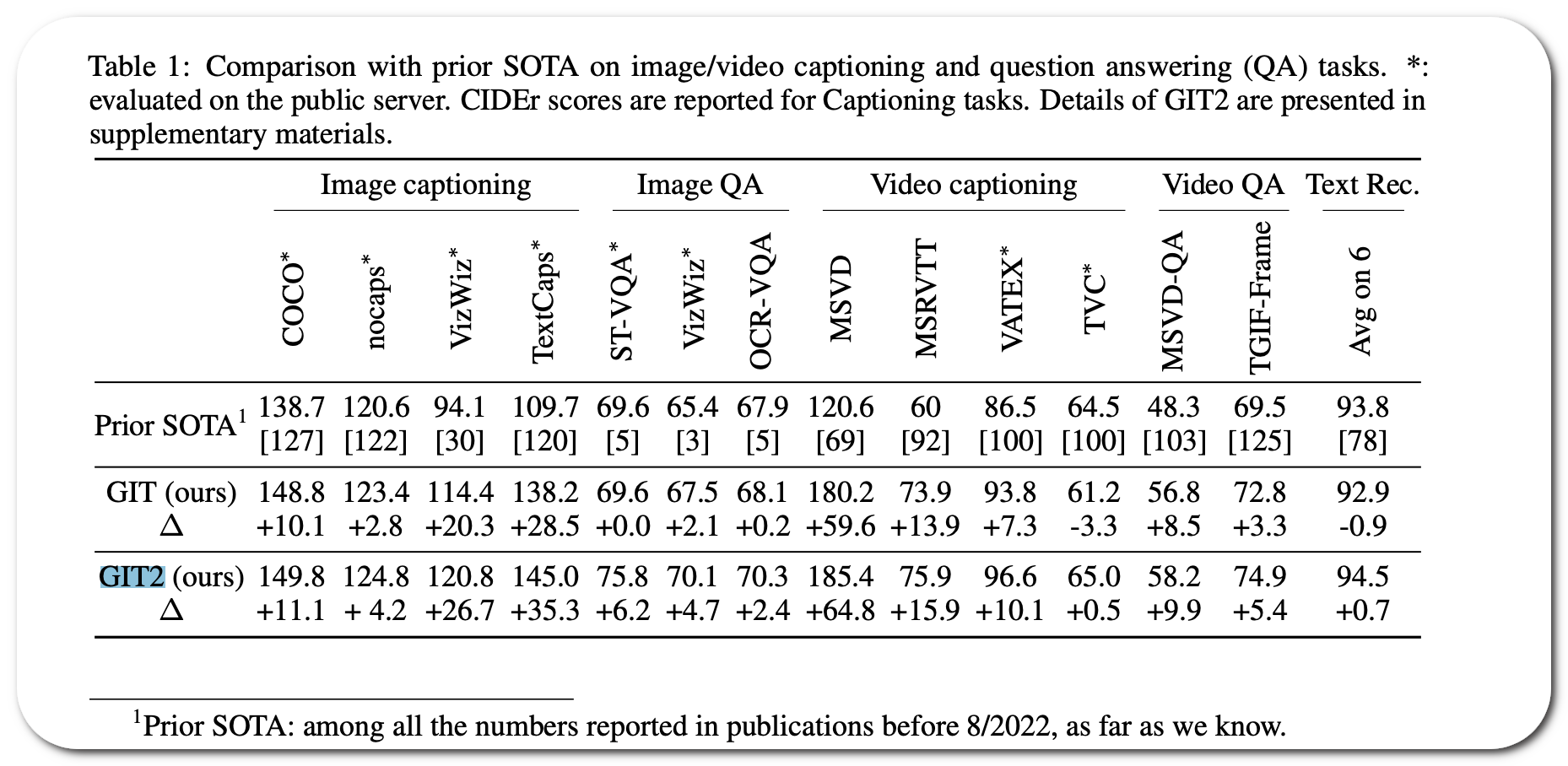
Paper: GIT: A Generative Image-to-text Transformer for Vision and Language. Submitted on 27 May 2022 (v1), last revised 22 Aug 2022 (v4) . Code updated 5 Aug 2022
Notes: The image and text encoder in GIT2 is scaled up from GIT. The image encoder is scaled 4.b B parameters based on DaViT and the text encoder is scaled to .3 B with hyperparameters same as BERT-large.
Code: Github link
Model Name: GIT2
Score (↑) : GIT2 surpasses its prev SOTA(its own prior version) on 13 datasets
Model links. Pretrained models on Github page
Demo page link? None to date
Google colab link? None to date
Container image? None to date
#1 in Image captioning on COCO

Paper: ExpansionNet v2: Block Static Expansion in fast end to end training for Image Captioning
Paper submitted on 13 Aug 2022 (v1), last revised 19 Aug 2022. Code updated 21 Aug 2022 .
Github code released by Jia Cheng Hu (first author in paper) Model link: Not released to date
Notes: This model attempts to address the performance bottlenecks in the input length for image captioning. The approach distributes and processes the input over a heterogeneous and arbitrarily big collection of sequences characterized by a different length compared to the input one. This training strategy is designed to be not only effective but also 6 times faster compared to the standard approach of recent works in image captioning.
Model Name: ExpansionNet v2
Score (↑) : 143.7(Prev: 131.2)
Δ: 12.5 (Metric: CIDEr)
Dataset: COCO
Demo page link? None to date
Google colab link? None to date
Container image? None to date
#1 in Visual Q&A and Visual reasoning
Paper:Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
Paper submitted 22 Aug 2022. Code updated 15 Aug 2022
Github code released by gitnlp Model link: Pretrained models on Github page for prior versions
Notes: This model uses a common backbone for masked "language modeling" on images, text and image-text pairs ("parallel sentences") in a unified manner.
Model Name: BEiT-3
Score (↑) : 84.19 (Prev 82.78);84.03(81.98) Q&A
Score (↑) : 91.51(Prev 86.1);92.58(87) visual reasoning
Metric: Accuracy
Dataset: VQA v2(test/std); NLVR2(dev/test)
Demo page link? Spaces link (prior version - image classification)
Google colab link? None to date
Container image? None to date
#1 in Video Object detection

Paper: YOLOV: Making Still Image Object Detectors Great at Video Object Detection
Paper submitted 20 Aug 2022. Code updated 25 Aug 2022
Github code released by Yuheng Shi (first author in paper) Model link: Pretrained models on Github page
Notes: This work proposes a one-stage object detector that only contains pixel level information to build a practical object detector that is both fast and accurate
Model Name: YOLOV
Score (↑) : 87.5 (Prev 85.5)
Δ: 2 (Metric: Mean Average Precision)
Dataset: ImageNet VID
Demo page link? None to date
Google colab link? None to date
Container image? None to date
#1 in Motion Blur removal
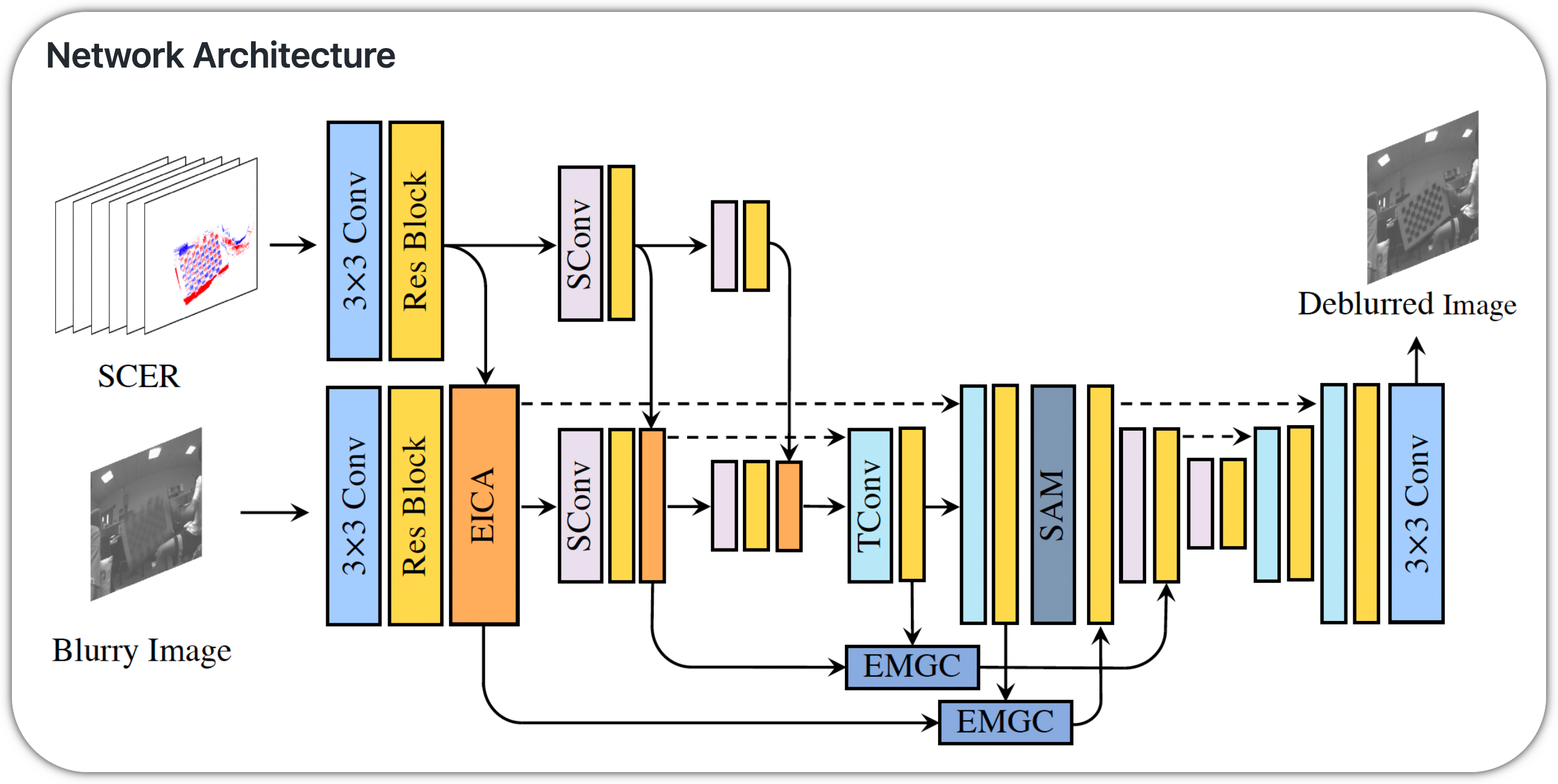
Paper: Event-Based Fusion for Motion Deblurring with Cross-modal Attention
Paper submitted on 30 Nov 2021 (v1), last revised 7 Apr 2022. Code updated 23 Aug 2022
Github code released by Lei Sun (first author in paper) Model link: Pretrained models on Github page
Notes: This paper attempts to address motion blur in frame based cameras due to long exposures. The model takes as input the blurry image as well as the event camera recording of the intensity changes in an asynchronous way with high temporal resolution. This provides valid image degradation information within the exposure time. Deblurring is performed using both these inputs.
Model Name: EFNet
Score (↑) : 35.46 (Prev 34.81)
Δ: .65 (Metric: PSNR)
Dataset: GoPro
Demo page link? None to date
Google colab link? None to date
Container image? None to date
#1 in Skeleton based action recognition
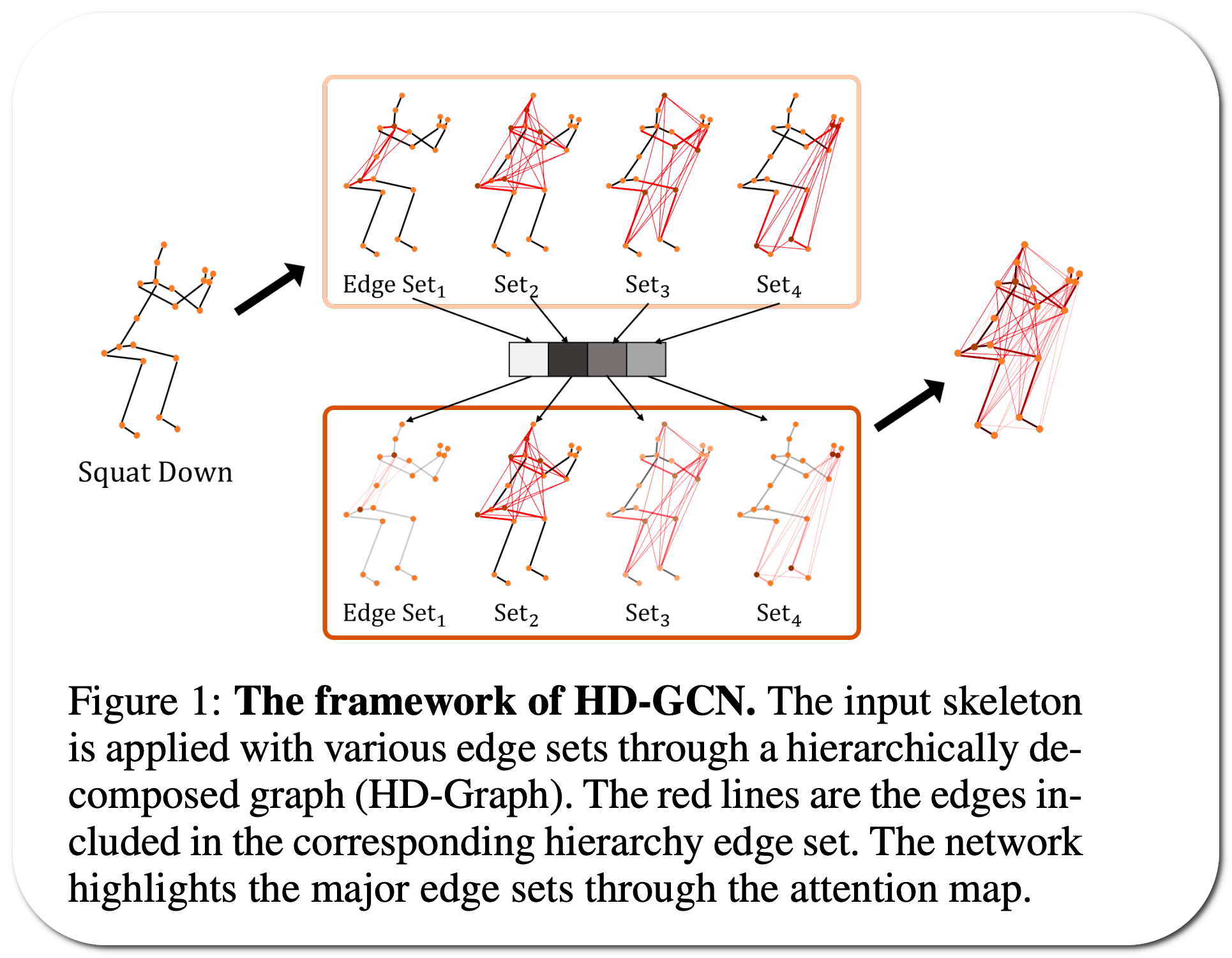
Paper: Hierarchically Decomposed Graph Convolutional Networks for Skeleton-Based Action Recognition
Paper submitted on 23 Aug 2022. Code updated 23 Aug 2022
Github code released by Jho-Yonsei (first author in paper) Model link: Pretrained models on Github page
Notes: Graph convolutional networks (GCNs) are the most commonly used method for skeleton-based action recognition. Generating adjacency matrices with semantically meaningful edges is particularly important for this task, but extracting such edges is challenging problem. This paper proposes a hierarchically decomposed graph convolutional network architecture with a hierarchically decomposed graph. Also an attention-guided hierarchy aggregation module to highlight the dominant hierarchical edge sets of the hierarchically decomposed graph.
Model Name: HD-GCN
Score (↑) : 90.1 (Prev 89.9)
Δ: .2 (Metric: Accuracy - cross-object)
Dataset: Dataset: NTU RGB+D 120 (link appears to be broken)
Demo page link? None to date
Google colab link? None to date
Container image? None to date
#1 in Semantic segmentation

Paper: Advancing Plain Vision Transformer Towards Remote Sensing Foundation Model
Submitted on 8 Aug 2022 (v1), last revised 10 Aug 2022. Code updated 22 Aug 2022
Github code released by Di Wang (first author in paper) Model link: Pretrained models on Github page
Notes: This paper adapts vision transformer for remote sensing tasks. To address the large image size and the various object orientations in remote sensing images, a rotate varied-size window attention is used to replace full attention in transformers. This reduces computational cost as well as memory footprint while learning better representations from the rich context obtained from the diverse windows.
Model Name: ViTAE-B + RVSA-UperNet
Score (↑) : 52.44(Prev 52.40)
Δ: 04 (Metric: Category mIoU; mean intersection over union)
Dataset: LoveDA
Demo page link? None to date
Google colab link? None to date
Container image? None to date
#1 in Entity typing, entity linking & entity disambiguation
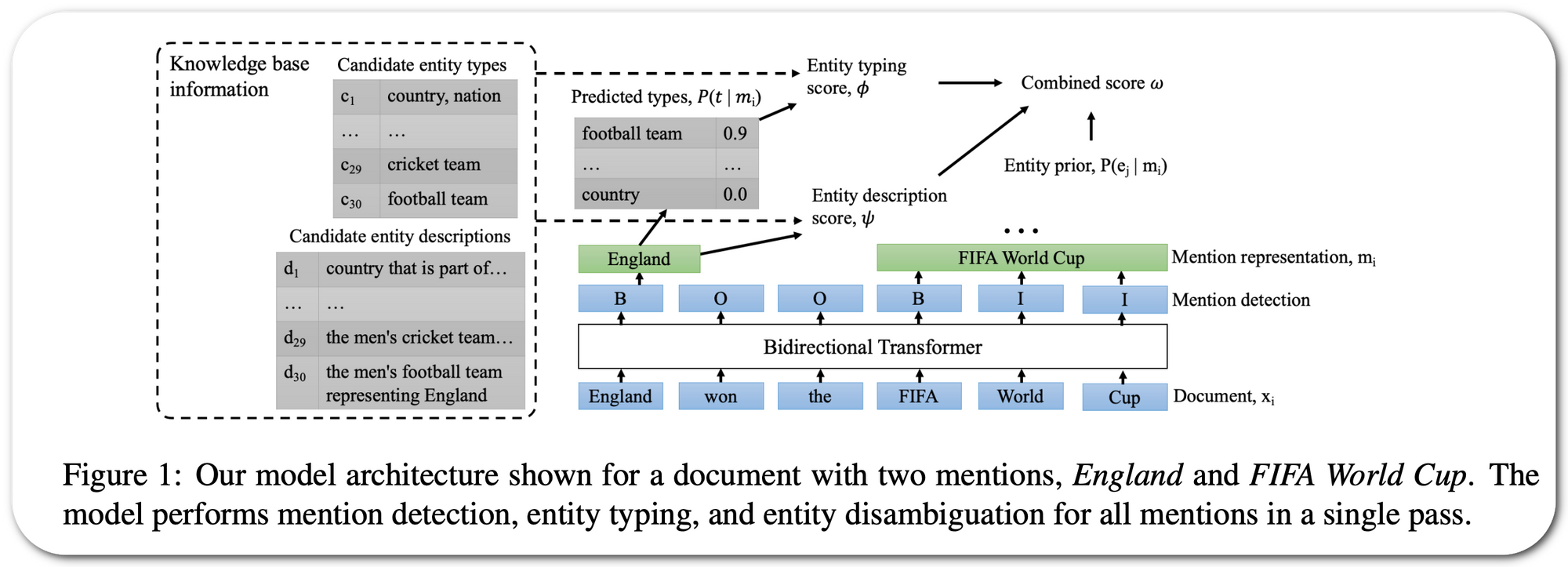
Paper: ReFinED: An Efficient Zero-shot-capable Approach to End-to-End Entity Linking
Paper submitted on 8 Jul 2022. Code updated 25 Aug 2022
Github code released by Tom Ayoola (first author in paper) Model link: Model downloaded automatically when testing.
Notes: A transformer model is used to perform mention detection, entity typing, and entity disambiguation for all mentions in a document in a single forward pass. The model is trained on a dataset generated dataset using Wikipedia hyperlinks, which consists of over 150M entity mentions. The model uses entity descriptions and fine-grained entity types to perform linking. New entities can be added to the system without retraining.
Code: Github link
Model Name: ReFinED
Score (↑) : 79.4(Prev 78.9)
Δ: .5 (Metric: Micro F1)
Dataset: WNED-CWEB Test dataset downloaded automatically when testing. Training dataset link inaccessible
Model links. Model downloaded automatically when testing.
Demo page link? None to date
Google colab link? None to date
Container image? None to date
#1 in facial expression recognition
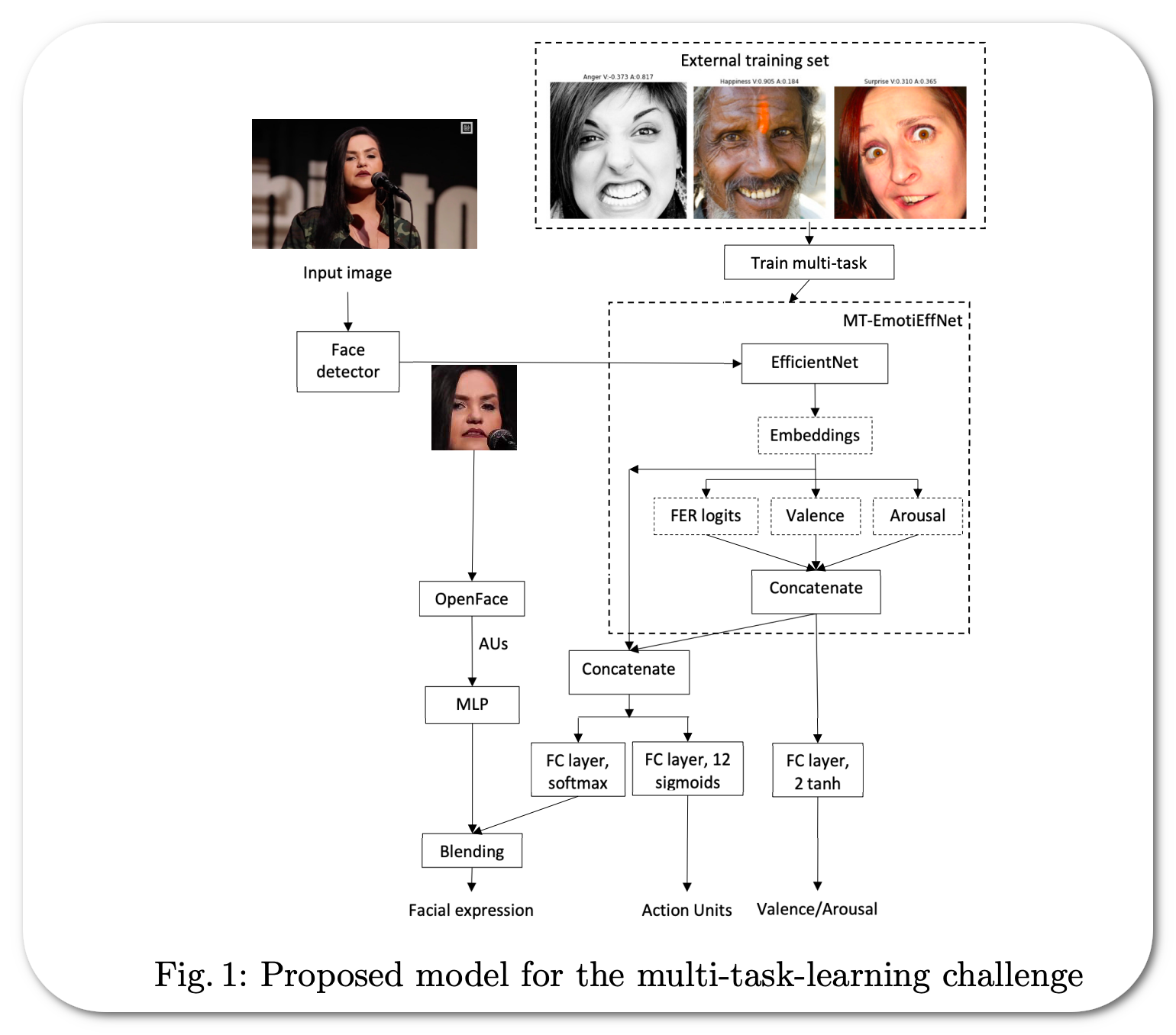
Paper: Classifying emotions and engagement in online learning based on a single facial expression recognition neural network (this paper requires login and/or payment. An accompanying paper using the same model family was submitted for a challenge is public
Accompanying Paper submitted 19 July 2022 . Code updated 26 Aug 2022 .
Github code released by Andrey Savchenko (first author in paper) Model link: Pretrained models on Github page
Notes: The model is trained for simultaneous recognition of facial expressions and prediction of valence and arousal on static photos. The resulting model extracts visual features that are fed into simple feed-forward neural networks in the multi-task learning challenge
Model Name: Multi-task EfficientNet-B2
Score (↑) : 63.03(Prev 63)
Δ: .03 (Metric: Accuracy - 8 emotion)
Dataset: AffectNet
Demo page link? None to date
Google colab link? Python notebooks for training is on Github page
Container image? None to date