#TWC 16

State-of-the-art (SOTA) updates for 14 – 20 Nov 2022
This weekly newsletter highlights the work of researchers who produced state-of-the-art work breaking existing records on benchmarks. They also
- authored their paper
- released their code
- released models in most cases
- released notebooks/apps in few cases
It is worth noting a significant proportion of the code release licenses allow commercial use. The only ask of these researchers in return from public is attribution. Also worth noting many of these SOTA researchers have little to no online presence.
New records were set on the following tasks
- Image Inpainting
- Instance segmentation,Semantic segmentation & Object detection
- Question Answering
- Multi-Object Tracking
- Action recognition
- Action classification
- Optical flow estimation
This weekly is a consolidation of daily twitter posts tracking SOTA researchers. Daily SOTA updates are also done on @twc@sigmoid.social - "a twitter alternative by and for the AI community"
To date, 27.5% (91,488) of total papers (332,347) published have code released along with the papers (source).
SOTA details below are snapshots of SOTA models at the time of publishing this newsletter. SOTA details in the link provided below the snapshots would most likely be different from the snapshot over time as new SOTA models emerge.
#1 in Image Inpainting on FFHQ 512x512 dataset



Model Name: SH-GAN
Notes: This paper introduces a StyleGAN-based image completion network, which attempts to address some of the drawbacks of image completion - pattern unawareness, blurry textures and structure distortion. It proposes a 2D spectral processing strategy and Heterogeneous Filtering and Gaussian Split that are a fit for deep learning models and may further be extended to other tasks.
Demo page: None to date
License: None to date
#1 in Instance segmentation,Semantic segmentation & Object detection
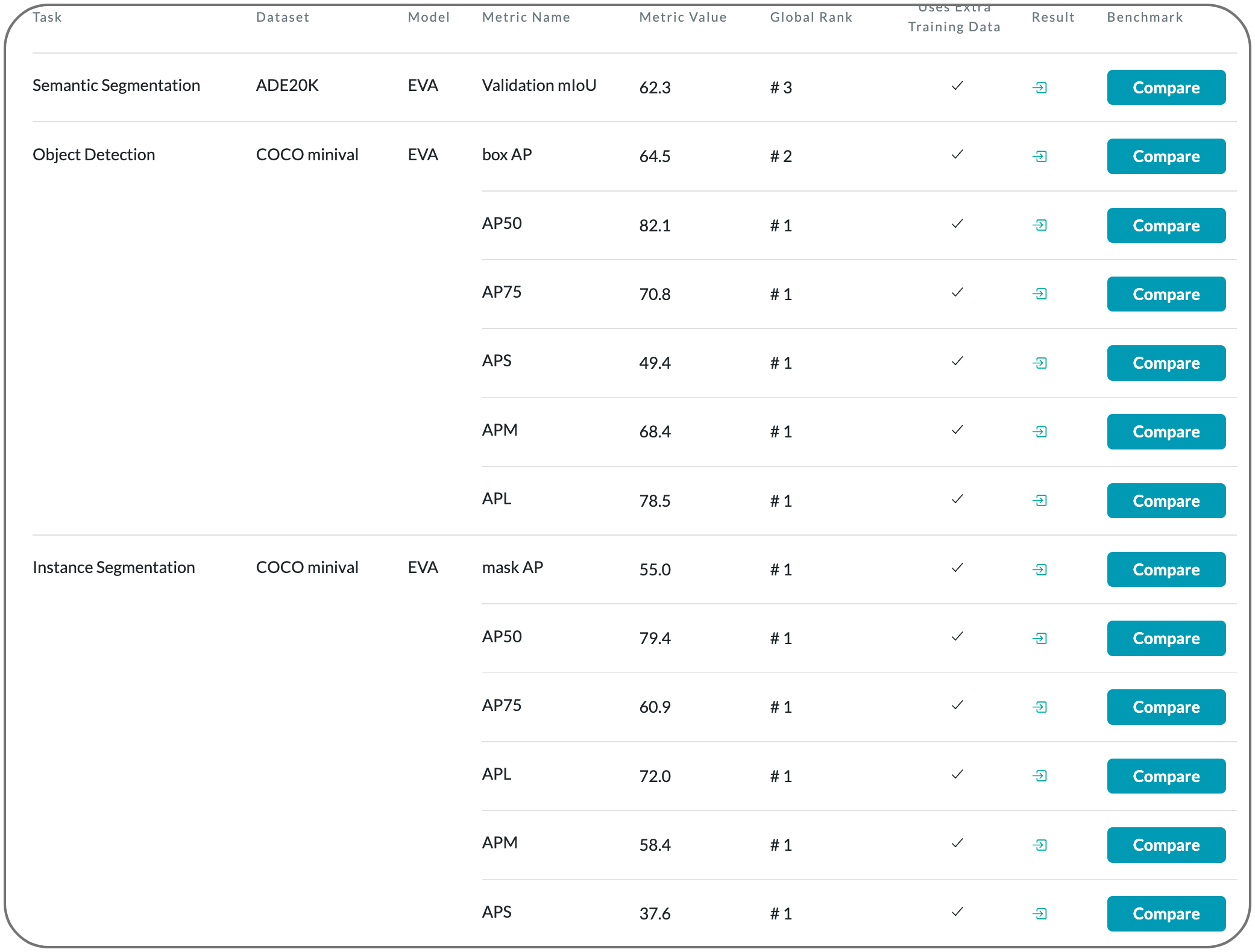
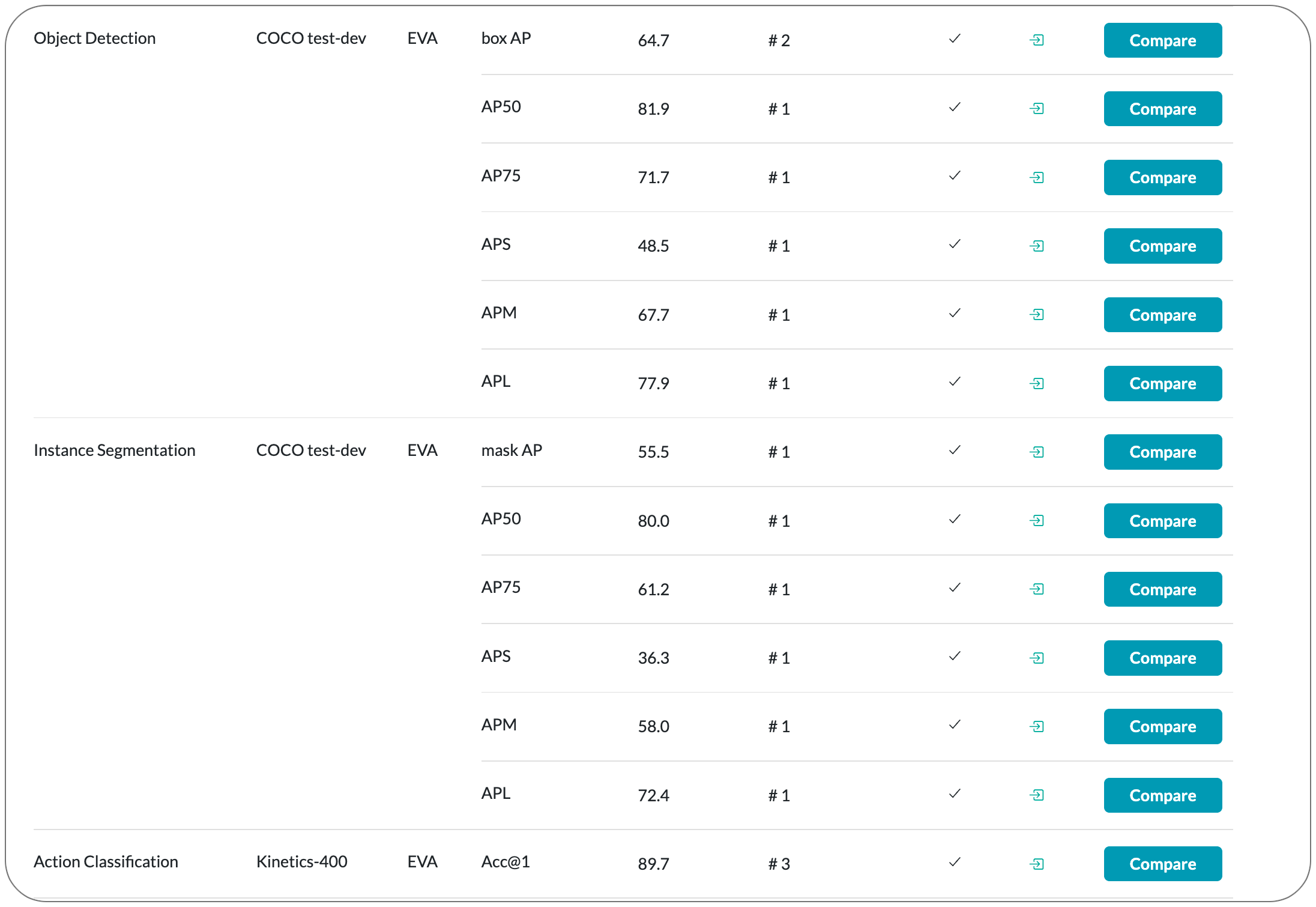
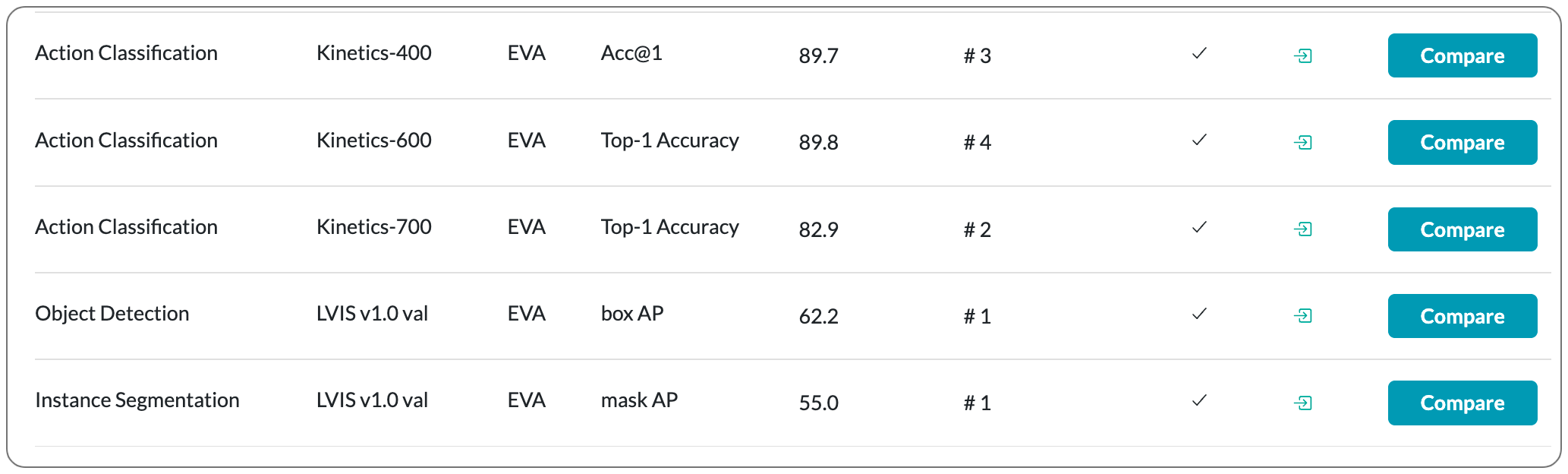

Model Name: EVA
Notes: This paper introduces a vision-centric foundation model EVA to explore the limits of visual representation at scale using only publicly accessible data. EVA is a vanilla ViT pre-trained to reconstruct the masked out image-text aligned vision features conditioned on visible image patches. This pretext task is used to scale up the model to one billion parameters, and set new records on a broad range of representative vision downstream tasks, such as image recognition, video action recognition, object detection, instance segmentation and semantic segmentation without heavy supervised training. Moreover, they observe quantitative changes in scaling EVA result in qualitative changes in transfer learning performance that are not present in other models. For instance, EVA performs relatively well in large vocabulary instance segmentation task: the model achieves almost the same state-of-the-art performance on LVISv1.0 dataset with over a thousand categories and COCO dataset with only eighty categories. Beyond a pure vision encoder, EVA can also serve as a vision-centric, multi-modal pivot to connect images and text.
Demo page: None to date
License: None to date
#1 in Question Answering on Natural questions
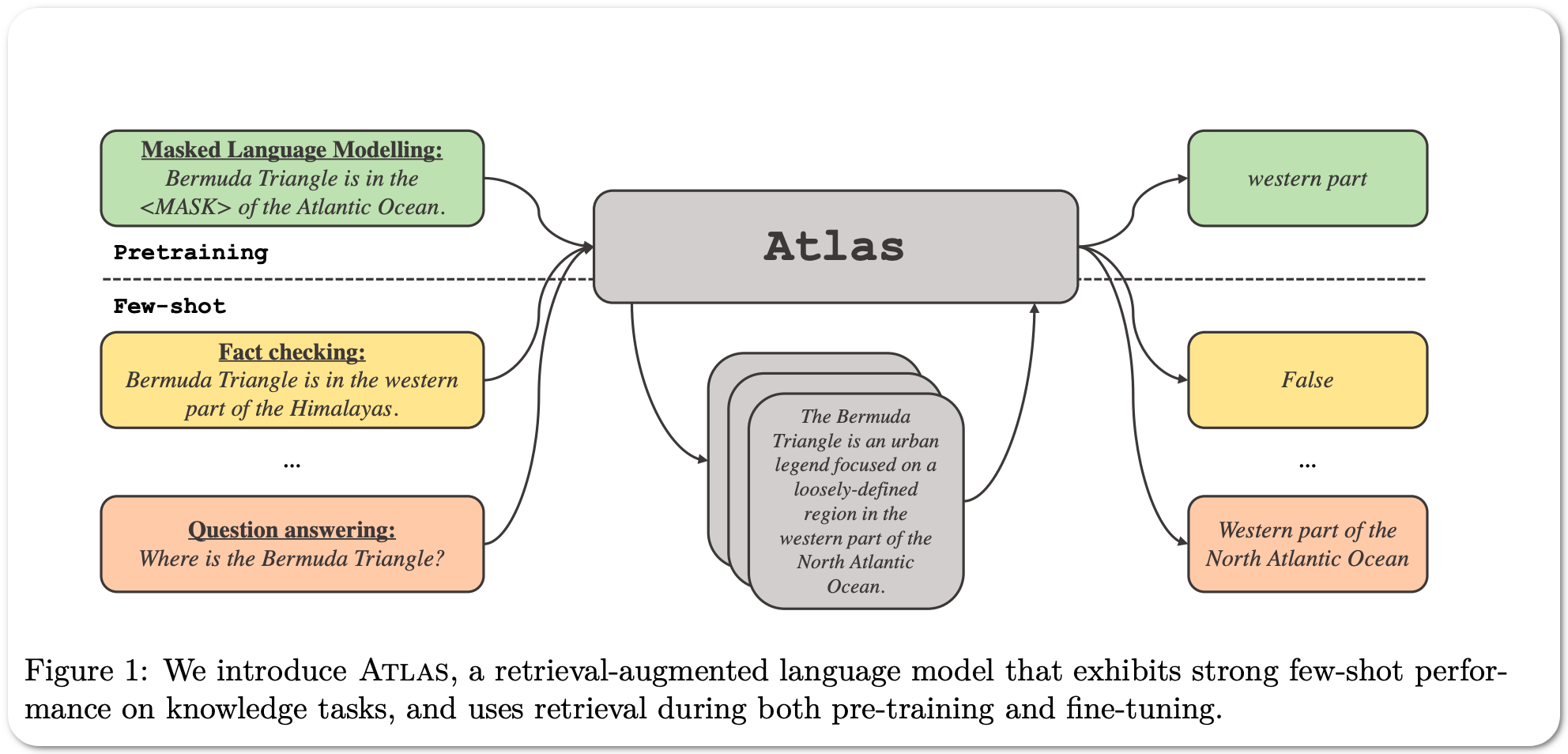
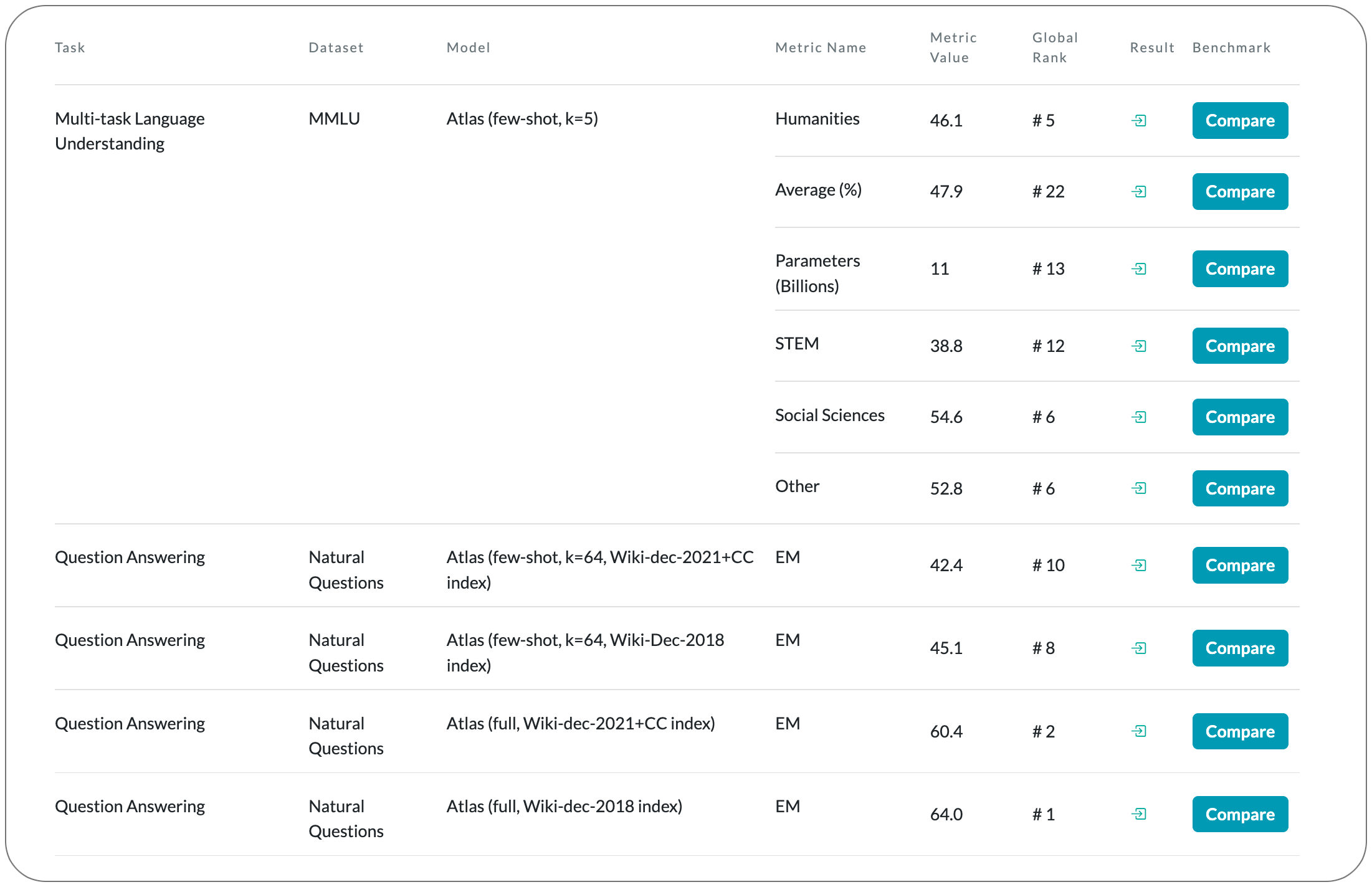

Model Name: Atlas
Notes: Even though large language models have shown impressive few-shot results on a wide range of tasks, when knowledge is key for such results, as is the case for tasks such as question answering and fact checking, massive parameter counts to store knowledge seem to be needed. Retrieval augmented models are known to excel at knowledge intensive tasks without the need for as many parameters, but it is unclear whether they work in few-shot settings. This paper presents a pre-trained retrieval augmented language model able to learn knowledge intensive tasks with very few training examples. The model reaches over 42% accuracy on Natural Questions using only 64 examples, outperforming a 540B parameters model by 3% despite having 50x fewer parameters.
Demo page: None to date
License: Majority of the code is released under CC-BY-NC, and the rest under a separate license.
#1 in Multi-Object Tracking on DanceTrack dataset
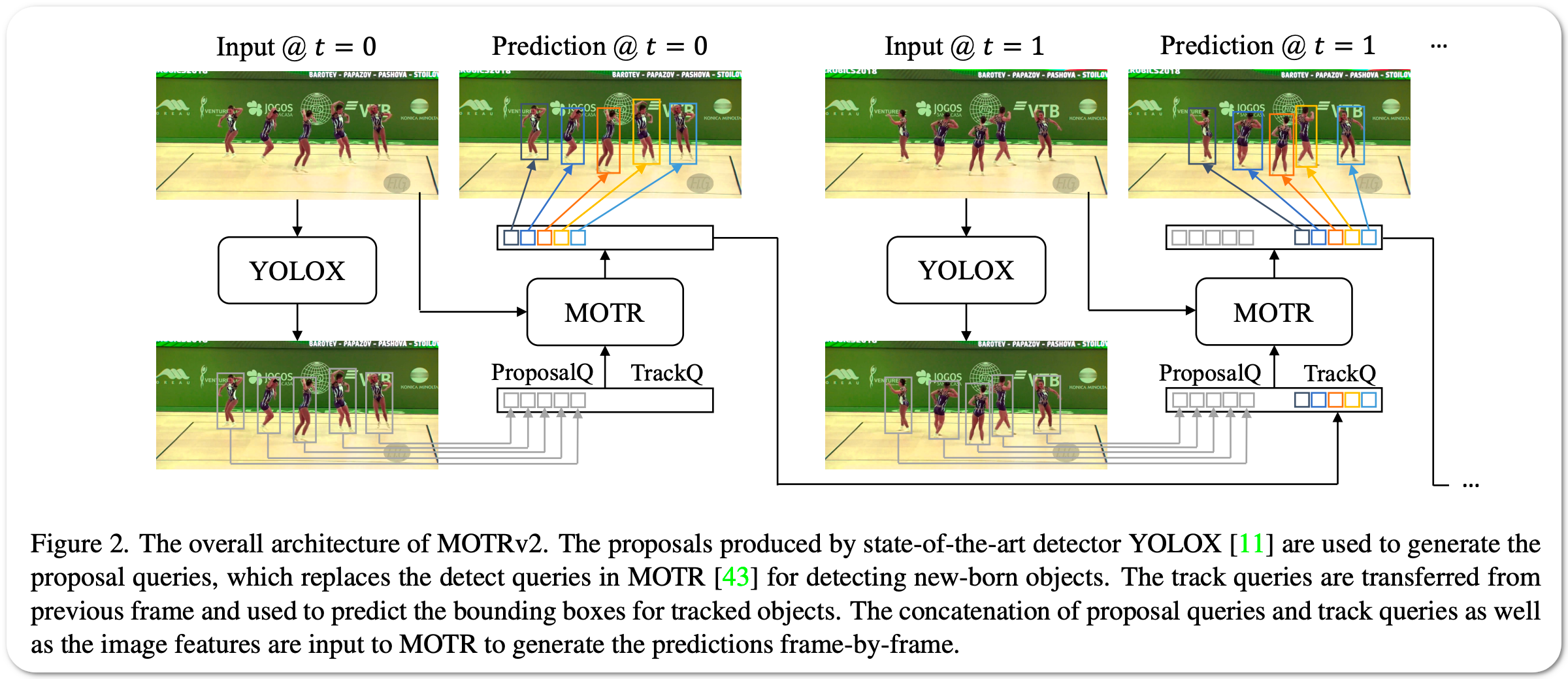

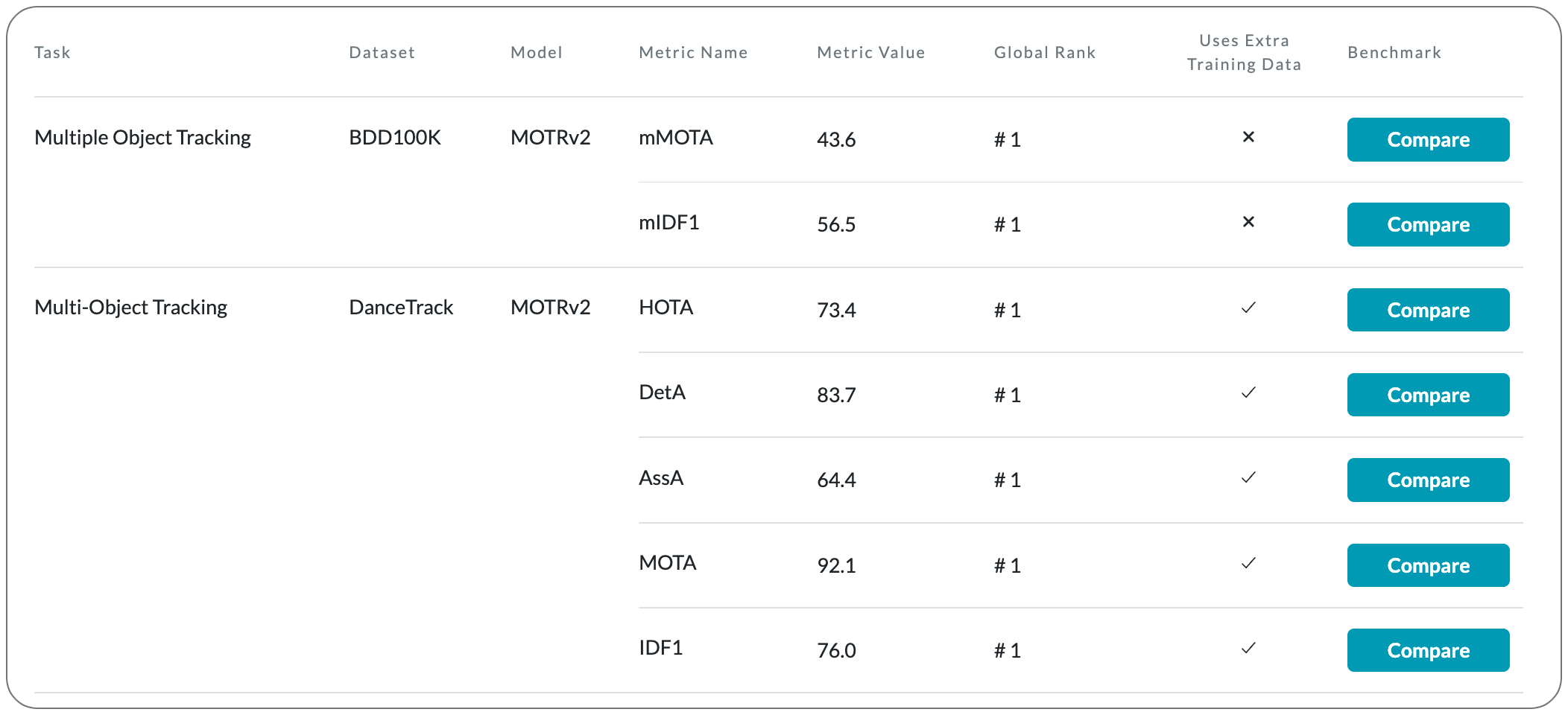

Model Name: MOTRv2
Notes: This paper propose a pipeline to bootstrap end-to-end multi-object tracking with a pretrained object detector. Existing end-to-end methods, e.g. MOTR and TrackFormer, are inferior to their tracking-by-detection counterparts due to their poor detection performance. This model MOTRv2 improves upon MOTR by incorporating an extra object detector. We first adopt the anchor formulation of queries and then use an extra object detector to generate proposals as anchors, providing detection prior to MOTR. The modification eases the conflict between joint learning detection and association tasks in MOTR.
Demo page: None to date
License: MIT license
#1 in Action recognition on 7 datasets
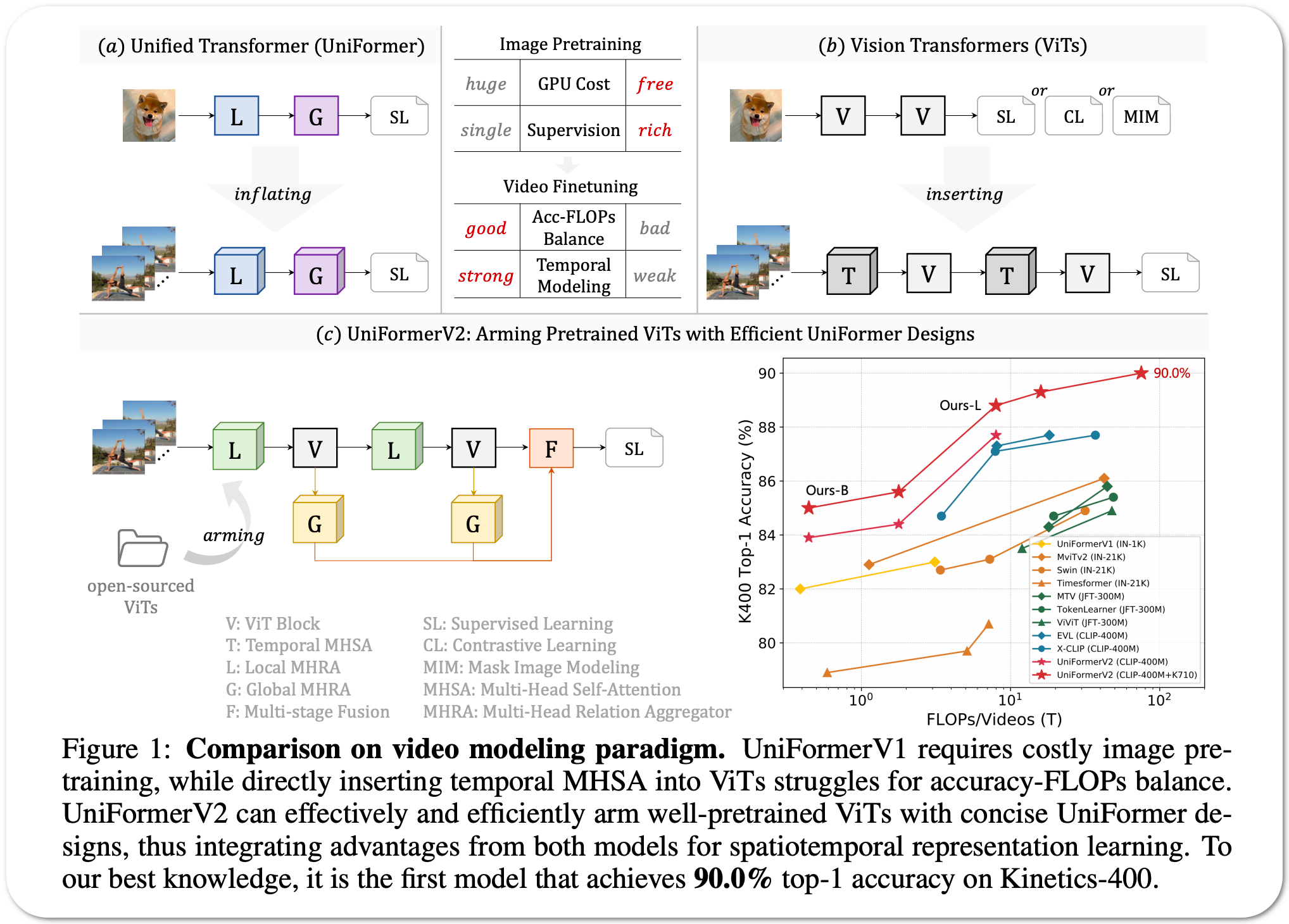
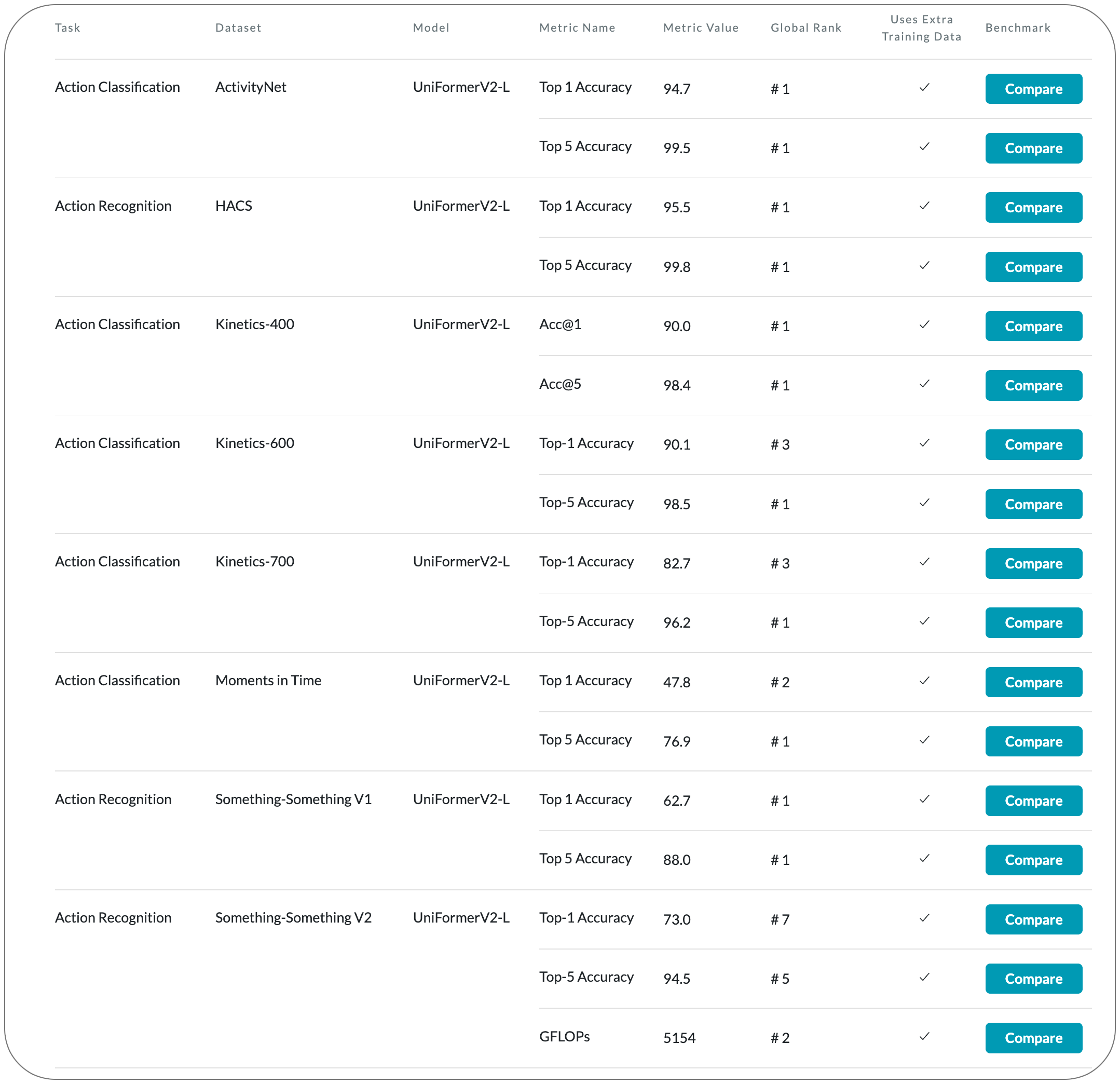

Model Name: UniFormerV2
Notes: Learning discriminative spatiotemporal representation is the key problem of video understanding. Recently, Vision Transformers (ViTs) have shown their power in learning long-term video dependency with self-attention. However, they exhibit limitations in tackling local video redundancy, due to the blind global comparison among tokens. UniFormer has successfully alleviated this issue, by unifying convolution and self-attention as a relation aggregator in the transformer format. However, this model has to require a tiresome and complicated image pretraining phrase, before being finetuned on videos. This blocks its wide usage in practice. On the contrary, open-sourced ViTs are readily available and well pretrained with rich image supervision. Based on these observations, this paper proposes a generic paradigm to build a powerful family of video networks, by arming the pretrained ViTs with efficient UniFormer designs. This model is names UniFormerV2, since it inherits the concise style of the UniFormer block. It contains new local and global relation aggregators, which allow for preferable accuracy computation balance by seamlessly integrating advantages from both ViTs and UniFormer.
Demo page: HuggingFace spaces demo. Image from spaces demo
License: Apache-2.0 license
#1 in Action classification on 2 datasets
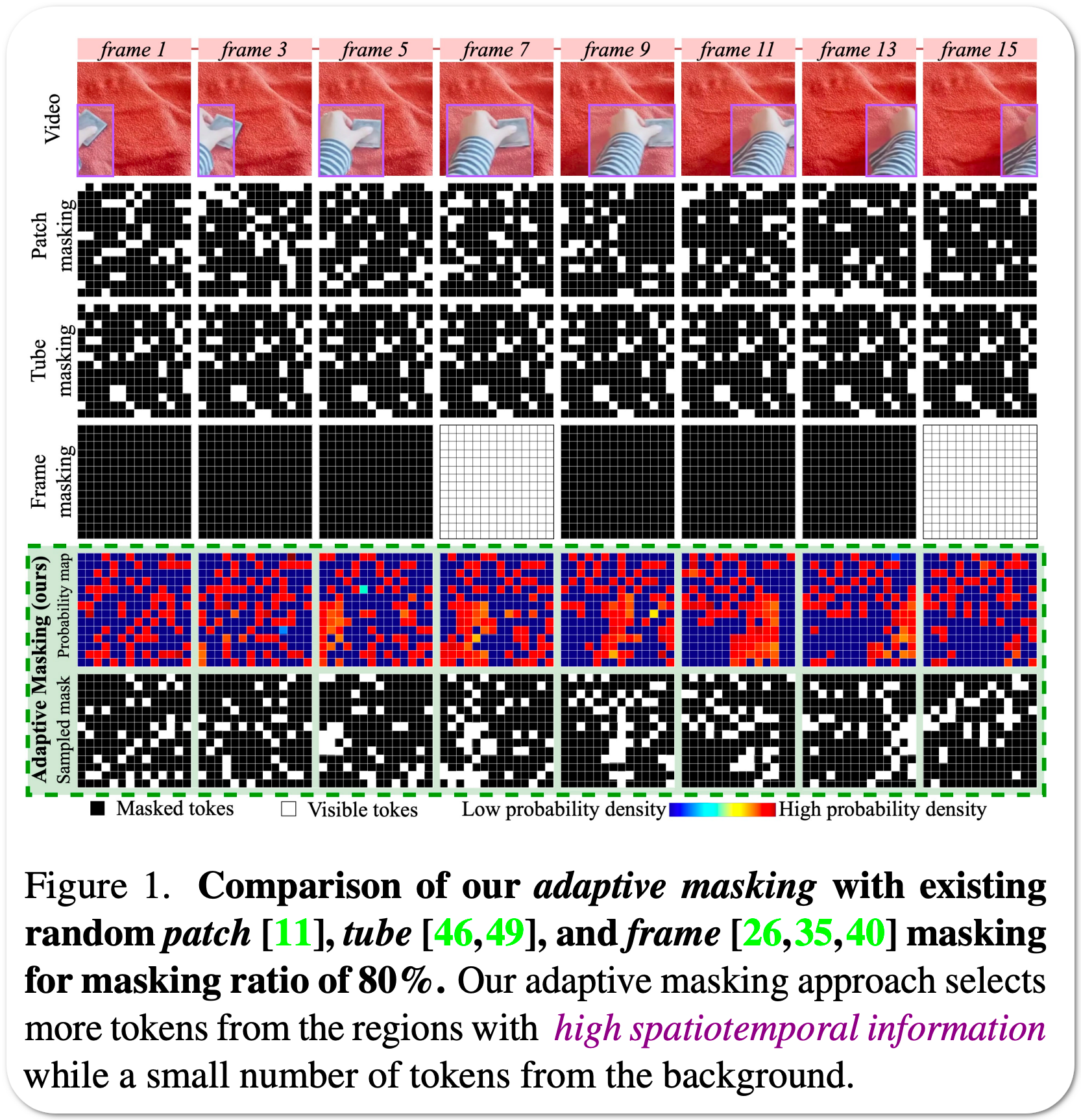
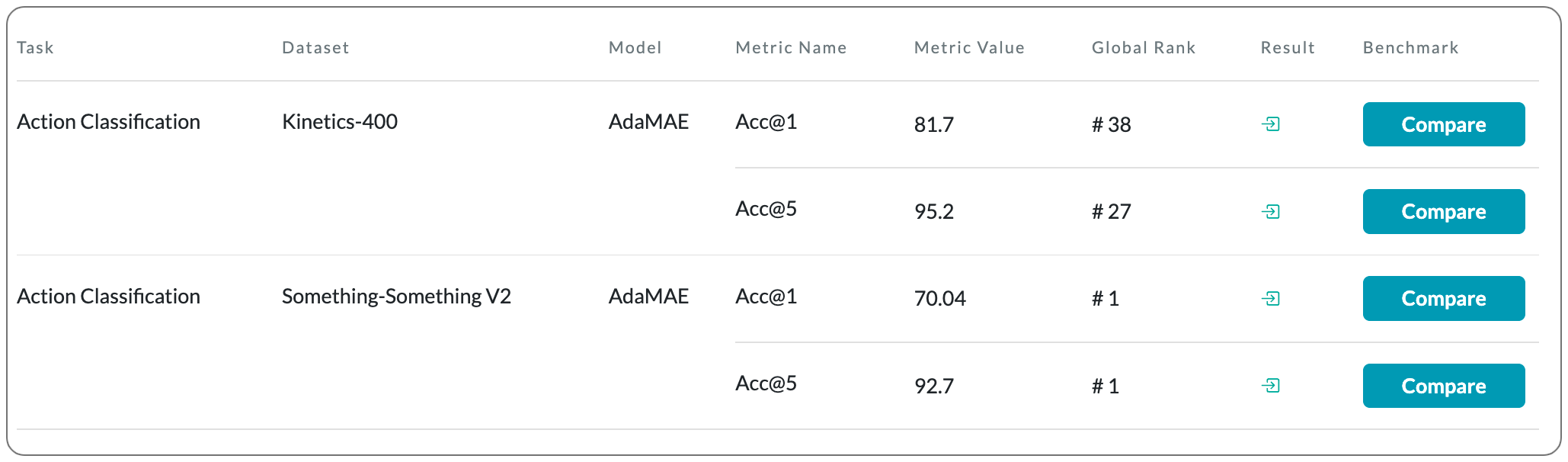

Model Name: AdaMAE
Notes: Masked Autoencoders (MAEs) learn generalizable representations for image, text, audio, video, etc., by reconstructing masked input data from tokens of the visible data. Current MAE approaches for videos rely on random patch, tube, or frame-based masking strategies to select these tokens. This paper proposes AdaMAE, an adaptive masking strategy for MAEs that is end-to-end trainable. The adaptive masking strategy samples visible tokens based on the semantic context using an auxiliary sampling network. This network estimates a categorical distribution over spacetime-patch tokens. The tokens that increase the expected reconstruction error are rewarded and selected as visible tokens, motivated by the policy gradient algorithm in reinforcement learning. They show that AdaMAE samples more tokens from the high spatiotemporal information regions, thereby allowing masking of 95% of tokens, resulting in lower memory requirements and faster pre-training.
Demo page: None to date
License: None to date
#1 in Optical flow estimation on Sintel dataset



Model Name: GMFlow
Notes: This paper proposes a unified formulation and model for three motion and 3D perception tasks: optical flow, rectified stereo matching and unrectified stereo depth estimation from posed images. Unlike previous specialized architectures for each specific task, all three tasks are formulated as a unified dense correspondence matching problem, which can be solved with a single model by directly comparing feature similarities. Such a formulation calls for discriminative feature representations, which is achieved using a Transformer, in particular the cross-attention mechanism. They demonstrate that cross-attention enables integration of knowledge from another image via cross-view interactions, which improves the quality of the extracted features.
Demo page: A Hugging Face spaces app, as well as a Google Colab notebook released
License: MIT license
Why another newsletter on ML papers?
It is nearly impossible to capture all the nuances of model implementation in a paper. Code release is key to replicate work or build off it. While a small percentage of researchers release code with paper, others may release code with a delay, at times starting with an empty placeholder repository. SOTA papers are reported here only when a Github repo contains official code release.