TWC #15

State-of-the-art (SOTA) updates for 7 – 13 Nov 2022
First of all... why another newsletter on ML papers?
It is nearly impossible to capture all the nuances of model implementation in a paper. Code release is key to replicate work or build off it. While a small percentage of researchers release code with paper, others may release code with a delay, at times starting with an empty placeholder repository. SOTA papers are reported here only when a Github repo contains official code release.
This weekly newsletter highlights the work of researchers who produced state-of-the-art work breaking existing records on benchmarks. They also
- authored their paper
- released their code
- released models in most cases
- released notebooks/apps in few cases
It is worth noting a significant proportion of the code release licenses allow commercial use. The only ask of these researchers in return from public is attribution. Also worth noting many of these SOTA researchers have little to no online presence.
New records were set on the following tasks
- Image Generation
- Video Quality Assessment
- Video Prediction
- Instance segmentation
This weekly is a consolidation of daily twitter posts tracking SOTA researchers. Daily SOTA updates are also done on @twc@sigmoid.social - "a twitter alternative by and for the AI community"
To date, 27.5% (90,902) of total papers (331,016) published have code released along with the papers (source).
SOTA details below are snapshots of SOTA models at the time of publishing this newsletter. SOTA details in the link provided below the snapshots would most likely be different from the snapshot over time as new SOTA models emerge.
#1 in Image Generation on FFHQ 256 x 256

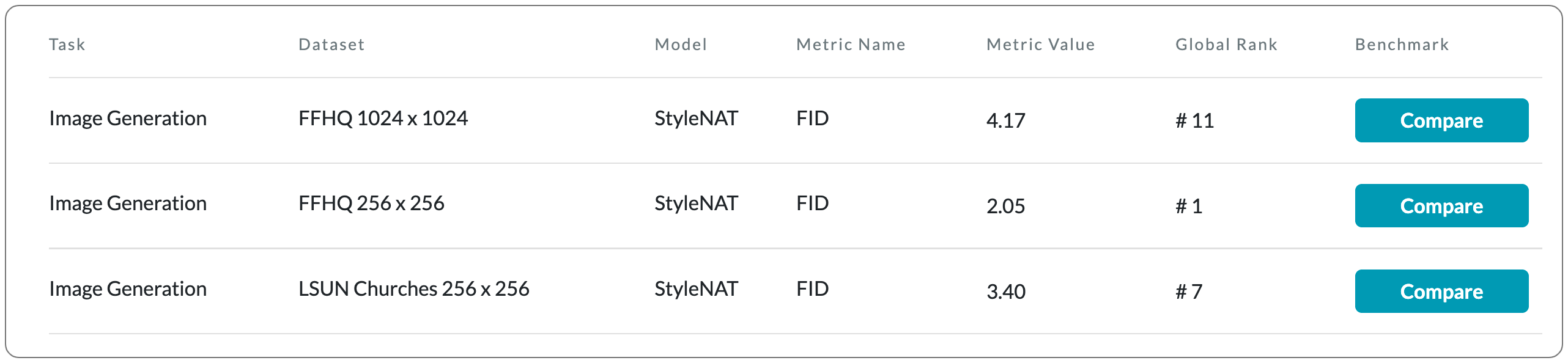

Model Name: StyleNAT
Notes: This paper presents a new transformer-based framework, dubbed StyleNAT, targeting high-quality image generation with superior efficiency and flexibility. This model has a framework that partitions attention heads to capture local and global information, which is achieved through using Neighborhood Attention (NA). With different heads able to pay attention to varying receptive fields, the model is able to better combine this information, and adapt, in a highly flexible manner, to the data at hand.
Demo page: None to date
License: None to date
#1 in Video Quality Assessment on 3 datasets
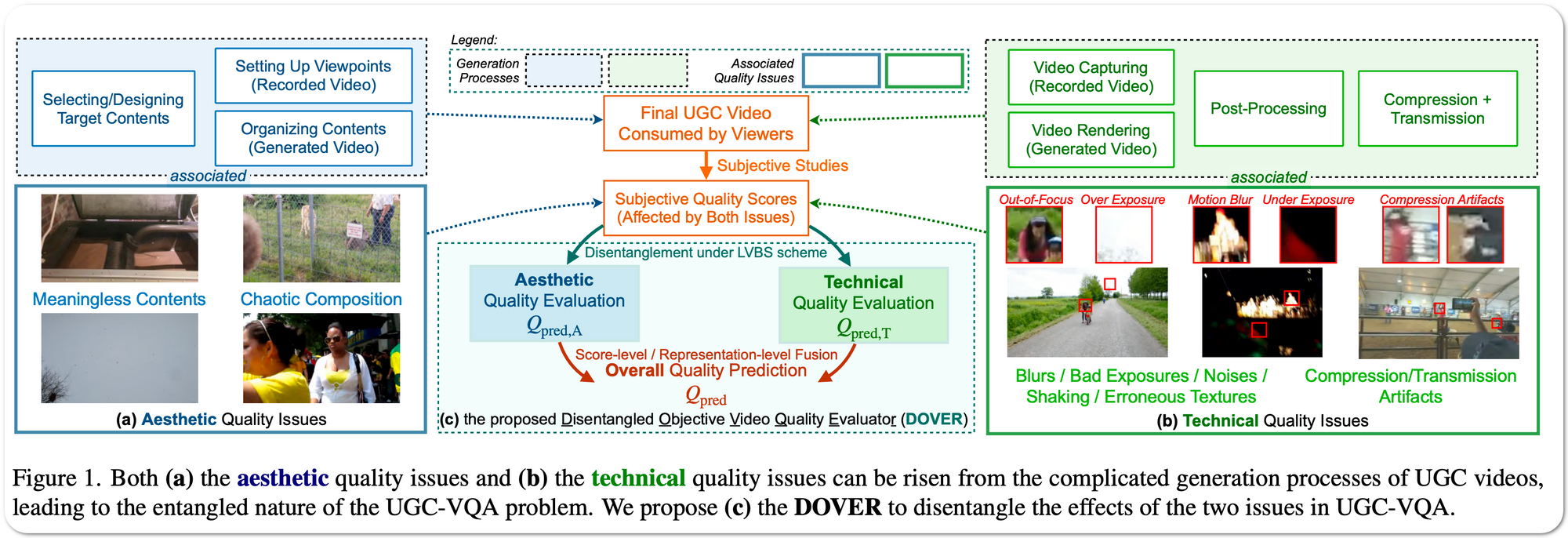
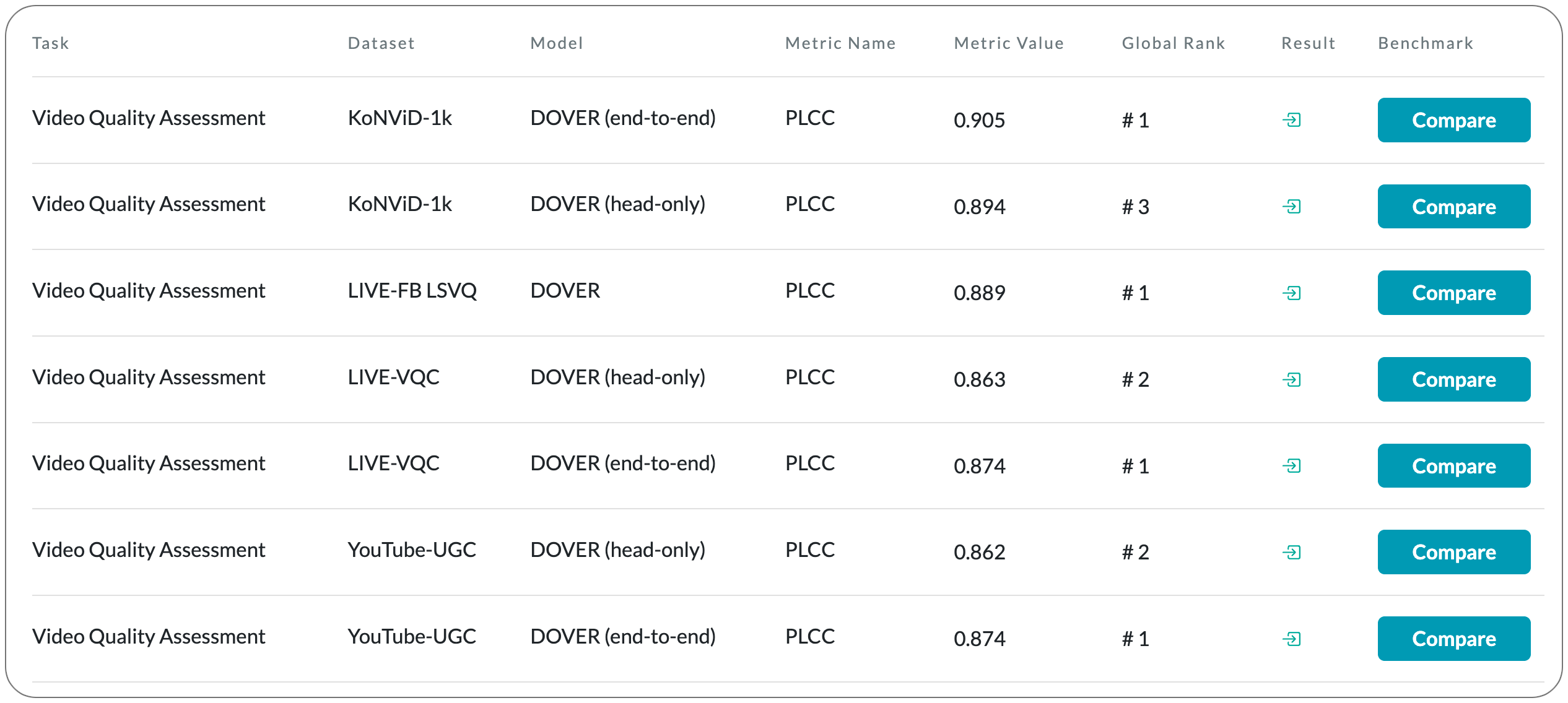

Model Name: DOVER
Notes: User-generated-content (UGC) videos have dominated the Internet during recent years. While many methods attempt to objectively assess the quality of these UGC videos, the mechanisms of human quality perception in the UGC-VQA problem is still yet to be explored. To better explain the quality perception mechanisms and learn more robust representations, this paper attempts to disentangle the effects of aesthetic quality issues and technical quality issues risen by the complicated video generation processes in the UGC-VQA problem. To overcome the absence of respective supervisions during disentanglement, the paper proposes a Limited View Biased Supervisions (LVBS) scheme where two separate evaluators are trained with decomposed views specifically designed for each issue.
Demo page: Added a notebook to test the model. Quality of custom videos can be uploaded and evaluated using the notebook. Sample test below
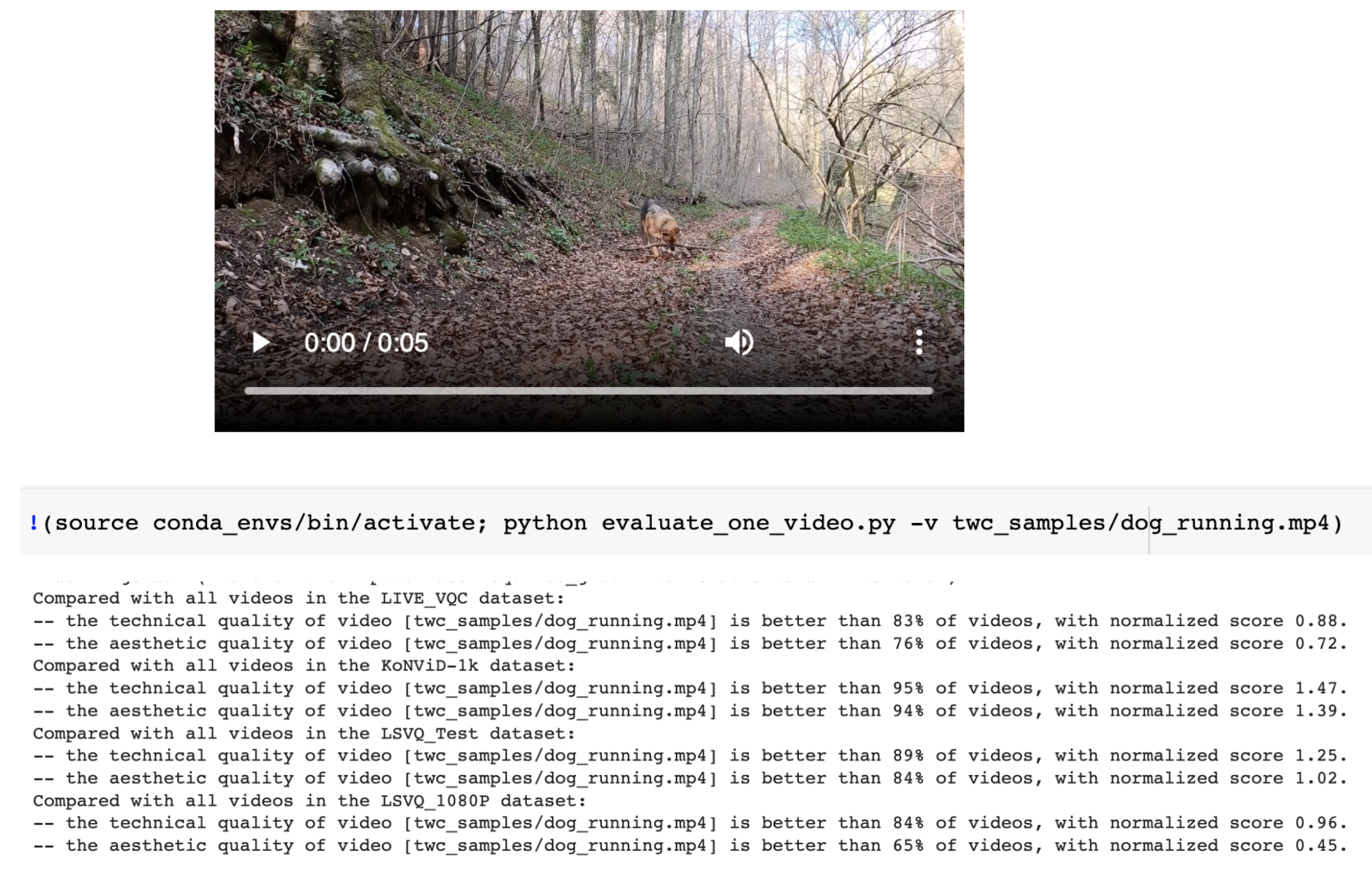
License: MIT license
#1 in Video Prediction on Kinetics-600 12 frames, 64x64 dataset

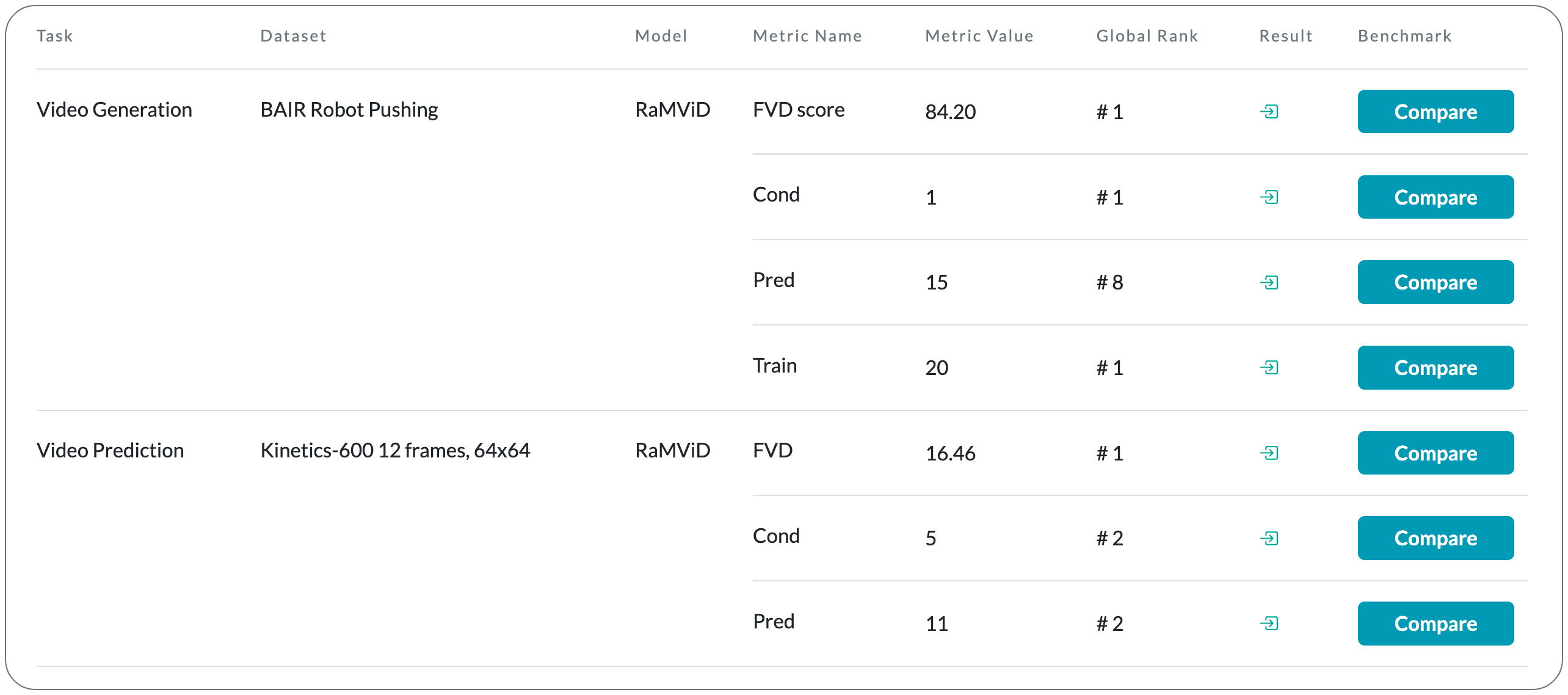

Model Name: RaMViD
Notes: Predicting and anticipating future outcomes or reasoning about missing information in a sequence are critical skills for agents to be able to make intelligent decisions. This requires strong, temporally coherent generative capabilities. Diffusion models have shown remarkable success in several generative tasks, but have not been extensively explored in the video domain. This paper presents Random-Mask Video Diffusion (RaMViD), which extends image diffusion models to videos using 3D convolutions, and introduces a new conditioning technique during training. By varying the mask that is conditioned on, the model is able to perform video prediction, infilling, and upsampling. With a simple conditioning scheme, they can utilize the same architecture as used for unconditional training, which allows them to train the model in a conditional and unconditional fashion at the same time.
Demo page: None to date. Few examples on papers' blog page
License: MIT license
#1 in Instance segmentation on COCO dataset
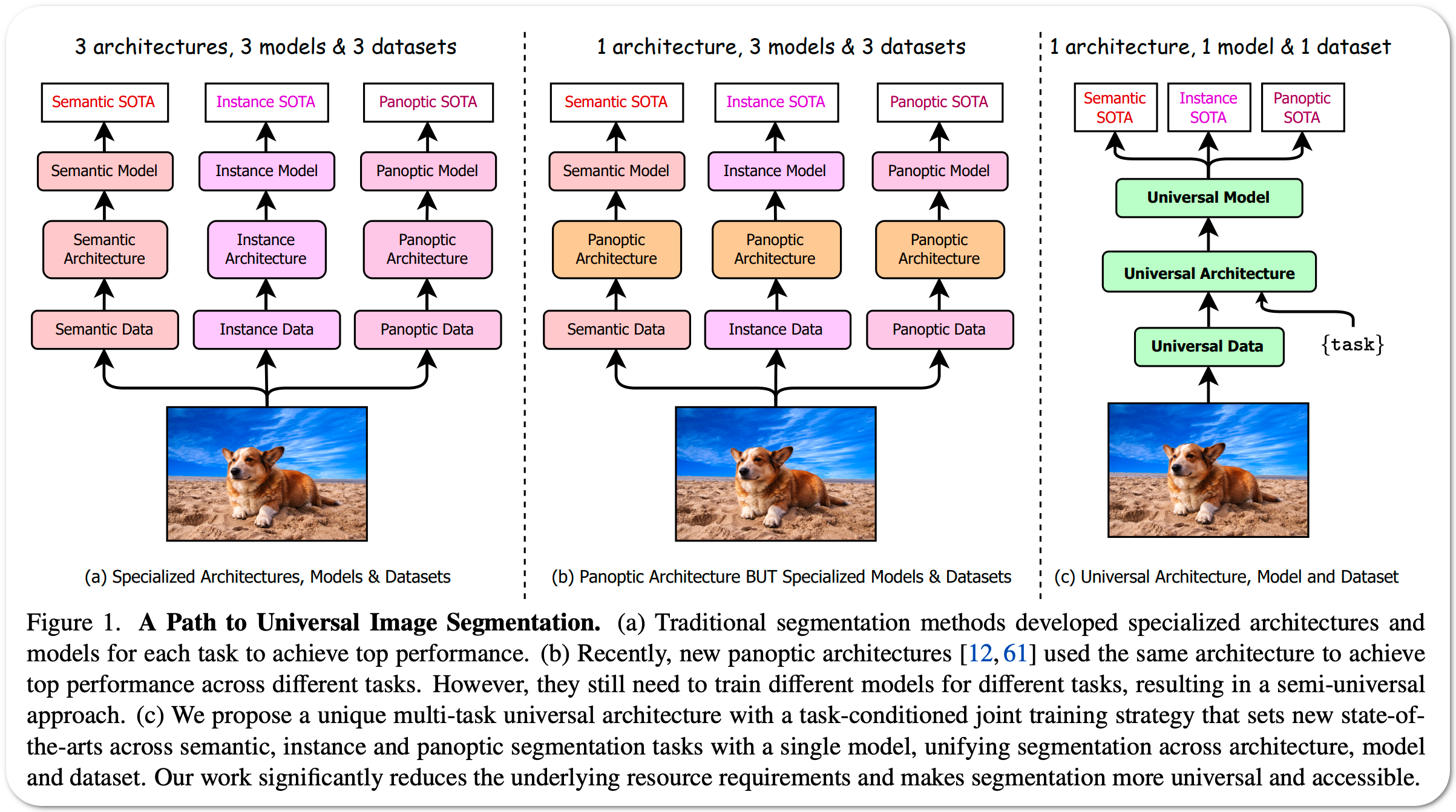
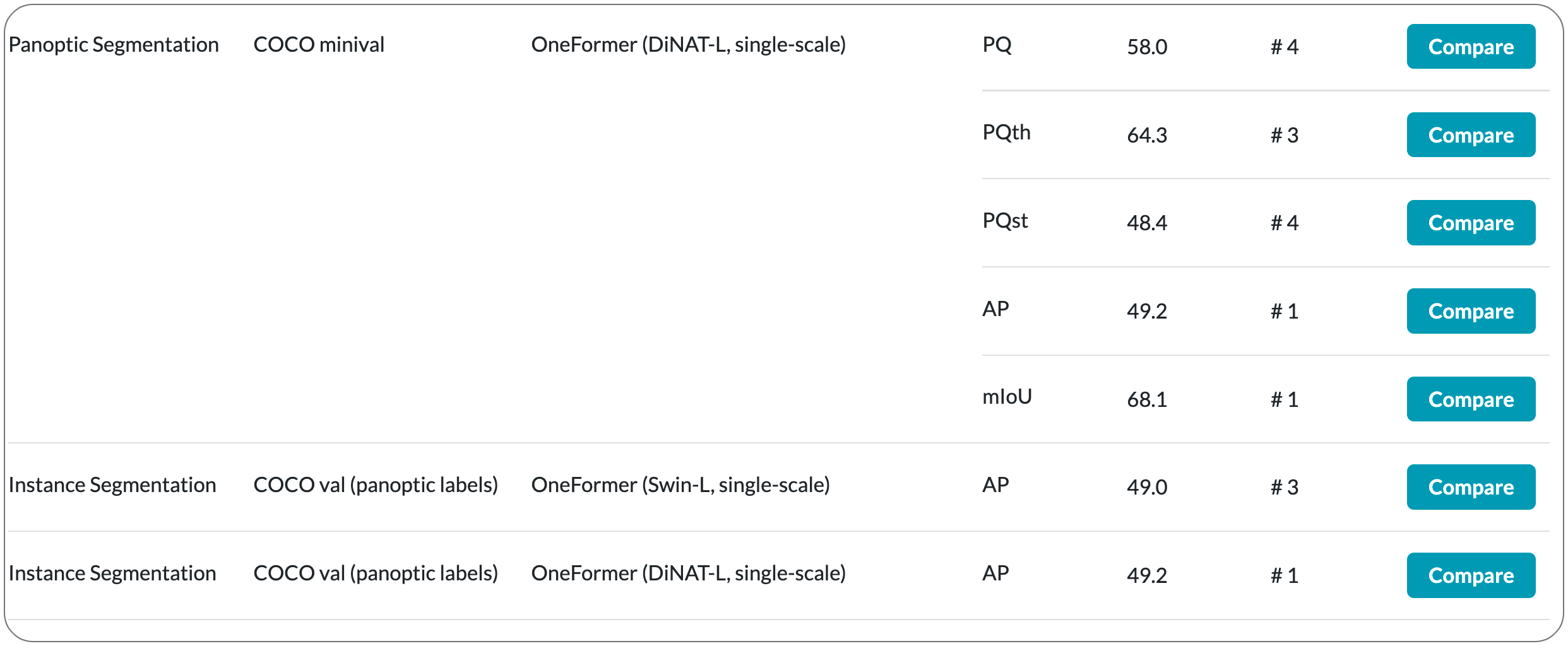

Model Name: DiNAT-L
Notes: Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and perform well across all three image segmentation tasks. This paper proposes OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. First a task-conditioned joint training strategy enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, a task token is used to condition the model on the task at hand, making the model task-dynamic to support multi-task training and inference. Thirdly, a query-text contrastive loss is used during training to establish better inter-task and inter-class distinctions.
Demo page: Colab Notebook link
License: MIT license