TWC #13

State-of-the-art (SOTA) updates for 24 Oct– 30 Oct 2022
TasksWithCode weekly newsletter highlights the work of SOTA researchers. Researchers in figure above produced state-of-the-art work breaking existing records on benchmarks. They also
- authored their paper
- released their code
- released models in most cases
- released notebooks/apps in few cases
The selected researchers broke existing records on the following tasks
- Anomaly detection
- Person Search
- Link Prediction
This weekly is a consolidation of daily twitter posts tracking SOTA researchers.
To date, 27.3% (89,704) of total papers (328,168) published have code released along with the papers (source), averaging ~6 SOTA papers with code in a week.
SOTA details below are snapshots of SOTA models at the time of publishing this newsletter. SOTA details in the link provided below the snapshots would most likely be different from the snapshot over time as new SOTA models emerge.
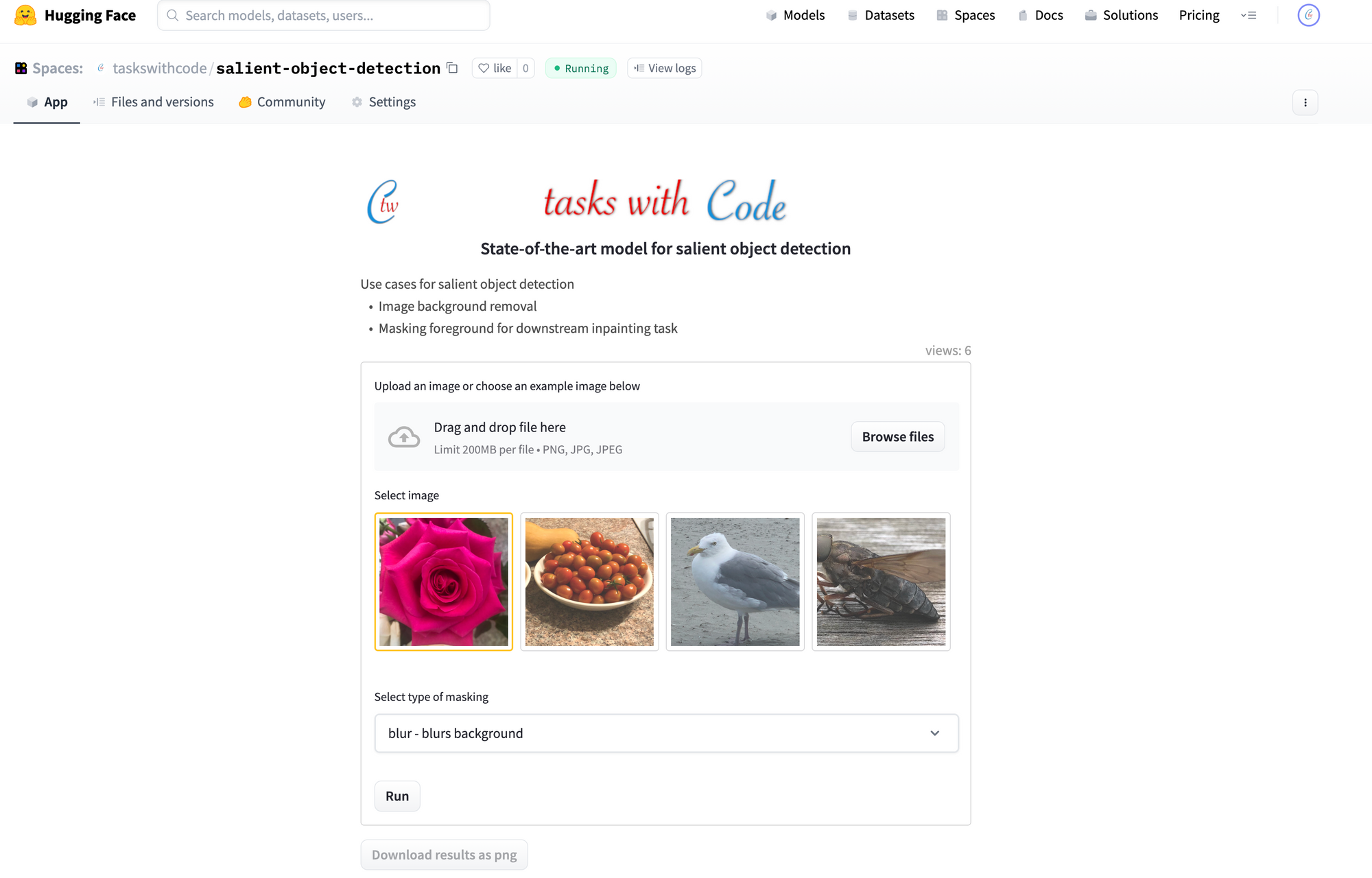
TWC App updates
Last week we released an app built on top of a SOTA model InSPyReNet we reviewed in TWC #9 The app is also hosted on HuggingFace. This app addresses the use case of removing background from a picture. User can upload any picture and have the background removed by a state-of-the art model. This could be a handy tool for removal of background in pictures we take on a phone.
#1 in Anomaly detection on CUHK Avenue dataset
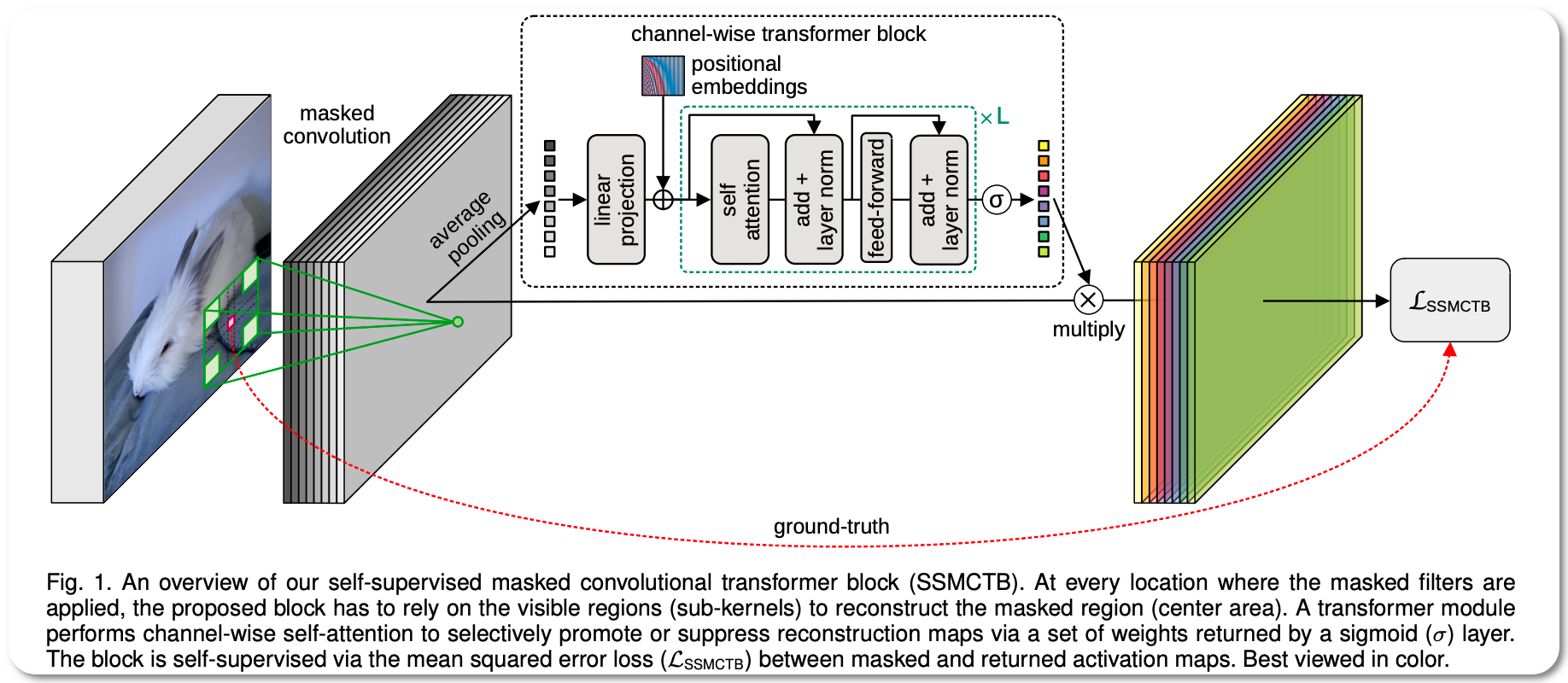
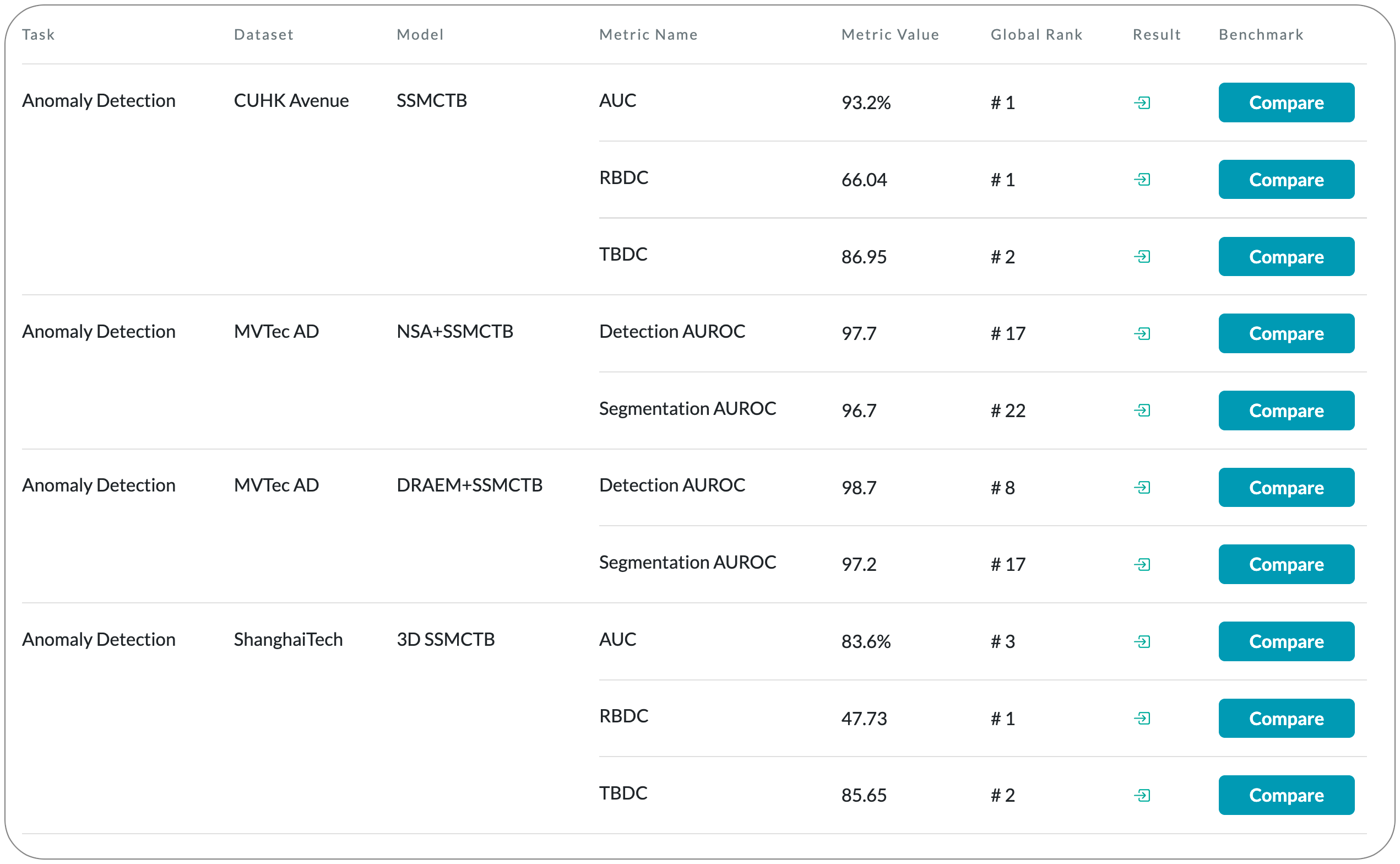

Model Name: SSMCTB
Notes: Anomaly detection is typically framed as a one-class classification task, where the learning is conducted on normal examples only. An entire family of successful anomaly detection methods is based on learning to reconstruct masked normal inputs (e.g. patches, future frames, etc.) and exerting the magnitude of the reconstruction error as an indicator for the abnormality level. Unlike other reconstruction-based methods, this paper proposes a self-supervised masked convolutional transformer block (SSMCTB) that comprises the reconstruction-based functionality at a core architectural level. The proposed self-supervised block enables information masking at any layer of a neural network and compatible with a wide range of neural architectures. Also this work extends their previous self-supervised predictive convolutional attentive block (SSPCAB) with a 3D masked convolutional layer, as well as a transformer for channel-wise attention. This approach is applicable to a wider variety of tasks, adding anomaly detection in medical images and thermal videos to the previously considered tasks based on RGB images and surveillance videos.
Demo page: None to date
License: CC BY-NC-SA 4.0 (non-commercial use)
#1 in Person search on 2 datasets
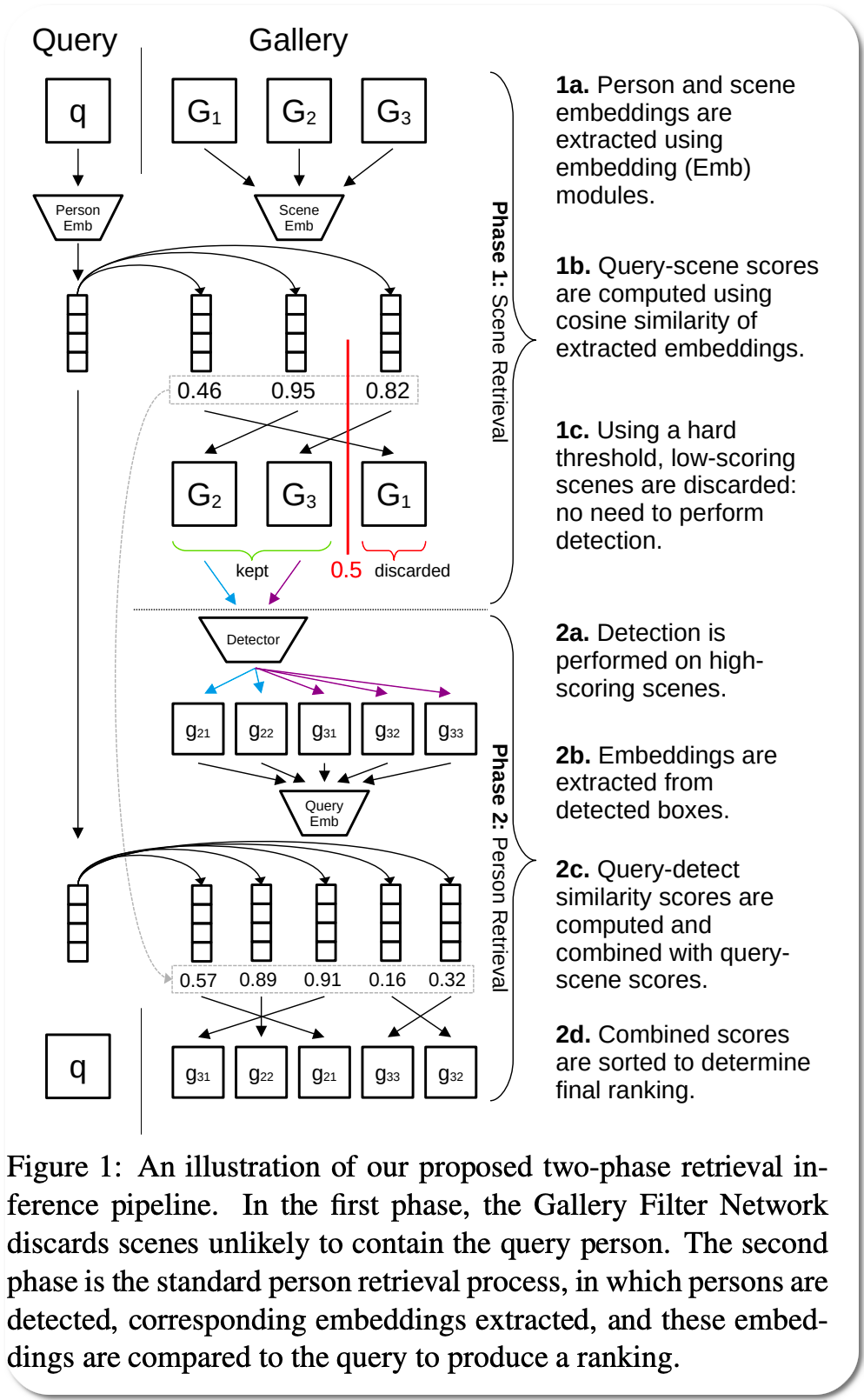
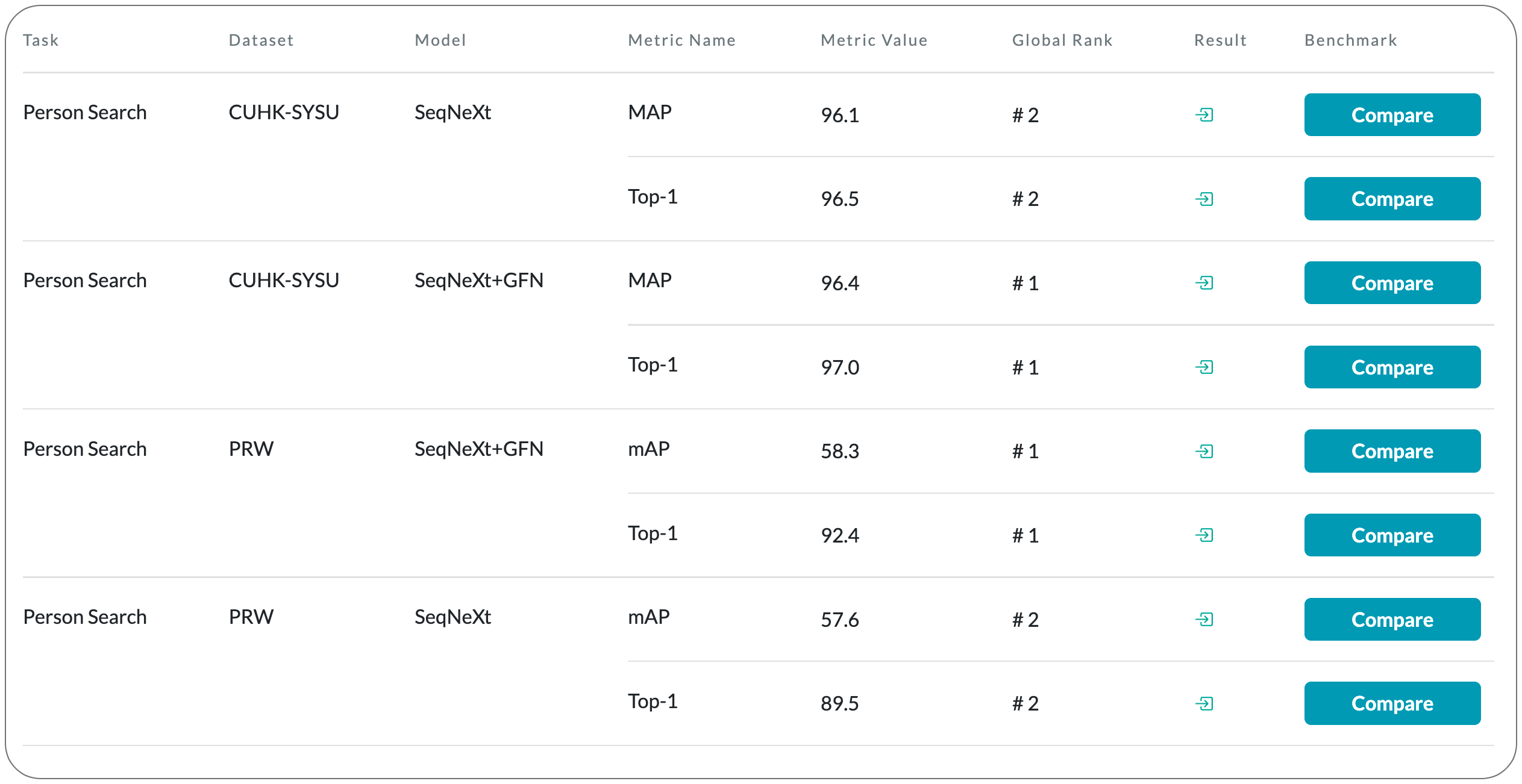

Model Name: SeqNeXt+GFN
Notes: Person search task aims to localize a query person from one scene in other gallery scenes. The cost of this search operation is dependent on the number of gallery scenes, making it beneficial to reduce the pool of likely scenes. This paper describes and demonstrates a module which can efficiently discard gallery scenes from the search process, and benefit scoring for persons detected in remaining scenes.
Demo page: None to date
License: MIT license
#1 in Link Prediction on two datasets
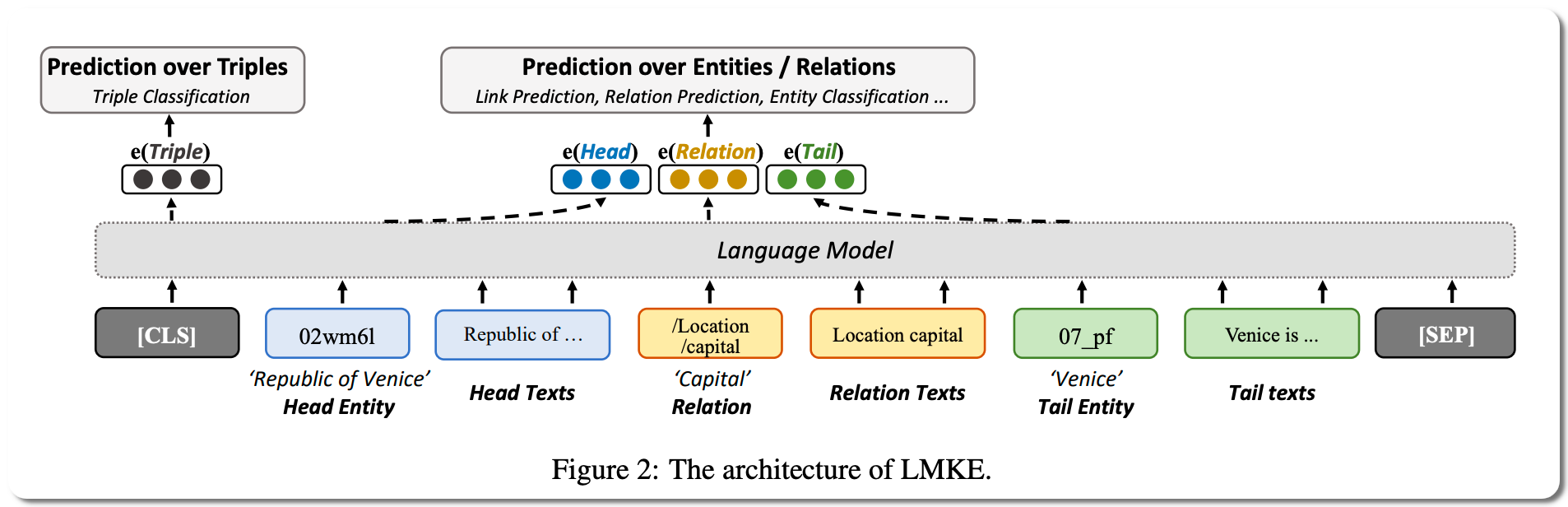
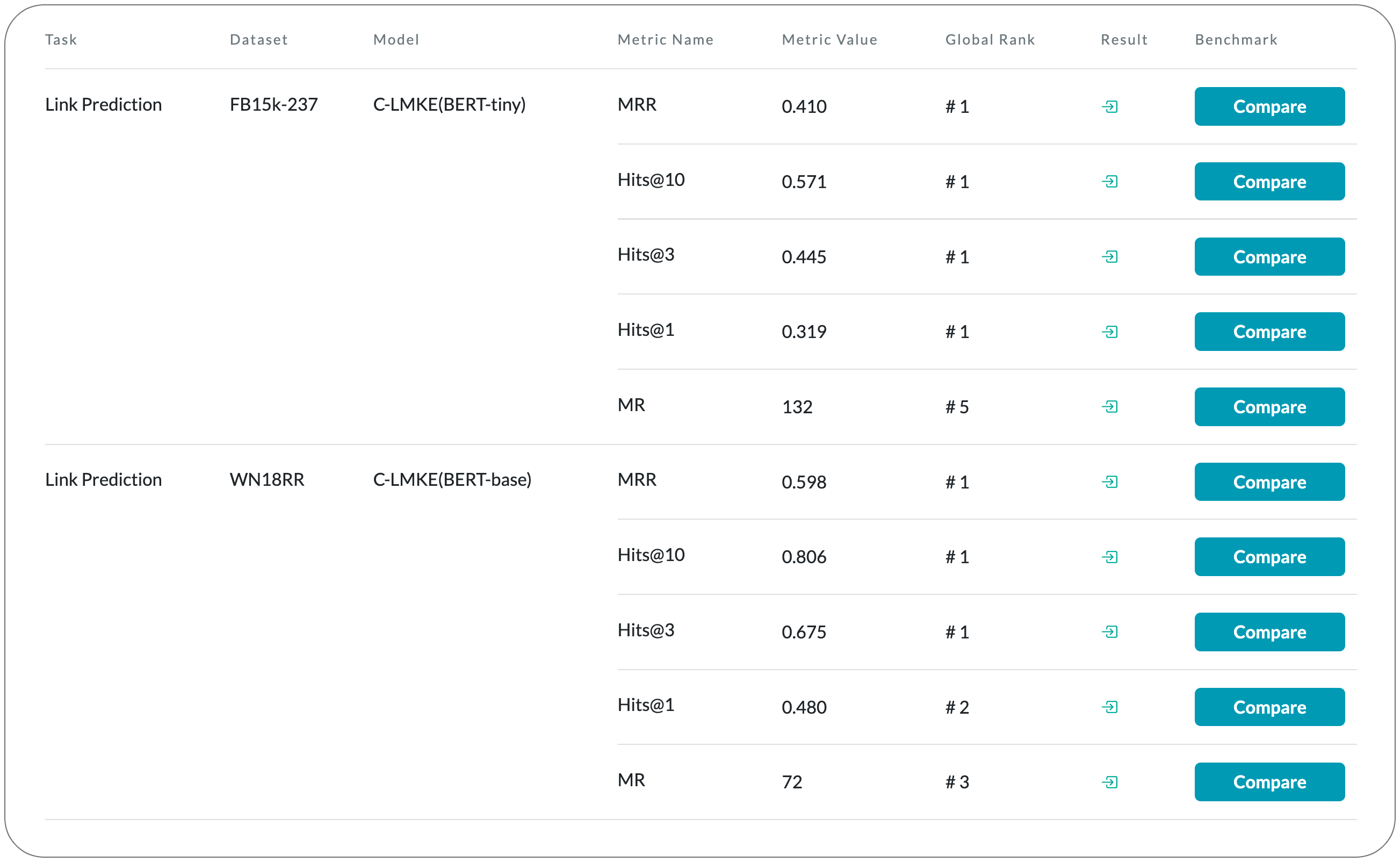

Model Name: C-LMKE
Notes: Knowledge embeddings (KE) represent a knowledge graph (KG) by embedding entities and relations into continuous vector spaces. Existing methods fail to well represent abundant long-tail entities in real-world KGs with limited structural information. Description-based methods leverage textual information and language models. Prior approaches in this direction barely outperform structure-based ones, and suffer from problems like expensive negative sampling and restrictive description demand. This paper propose LMKE, which adopts Language Models to derive Knowledge Embeddings, aiming at both enriching representations of long-tail entities and solving problems of prior description-based methods. This paper formulates description-based KE learning with a contrastive learning framework to improve efficiency in training and evaluation.
Demo page: None to date
License: None to date