TWC #11

State-of-the-art (SOTA) updates for 10 Oct– 16 Oct 2022
TasksWithCode weekly newsletter highlights the work of SOTA researchers. Researchers in figure above produced state-of-the-art work breaking existing records on benchmarks. They also
- authored their paper
- released their code
- released models in most cases
- released notebooks/apps in few cases
The selected researchers broke existing records on the following tasks
- Open Vocabulary Object Detection
- Image Generation
- Prompt Engineering
- Semantic Textual Similarity
- Video Quality Assessment
This weekly is a consolidation of daily twitter posts tracking SOTA researchers.
To date, 27.14% (88,129) of total papers (324,745) published have code released along with the papers (source), averaging ~6 SOTA papers with code in a week.
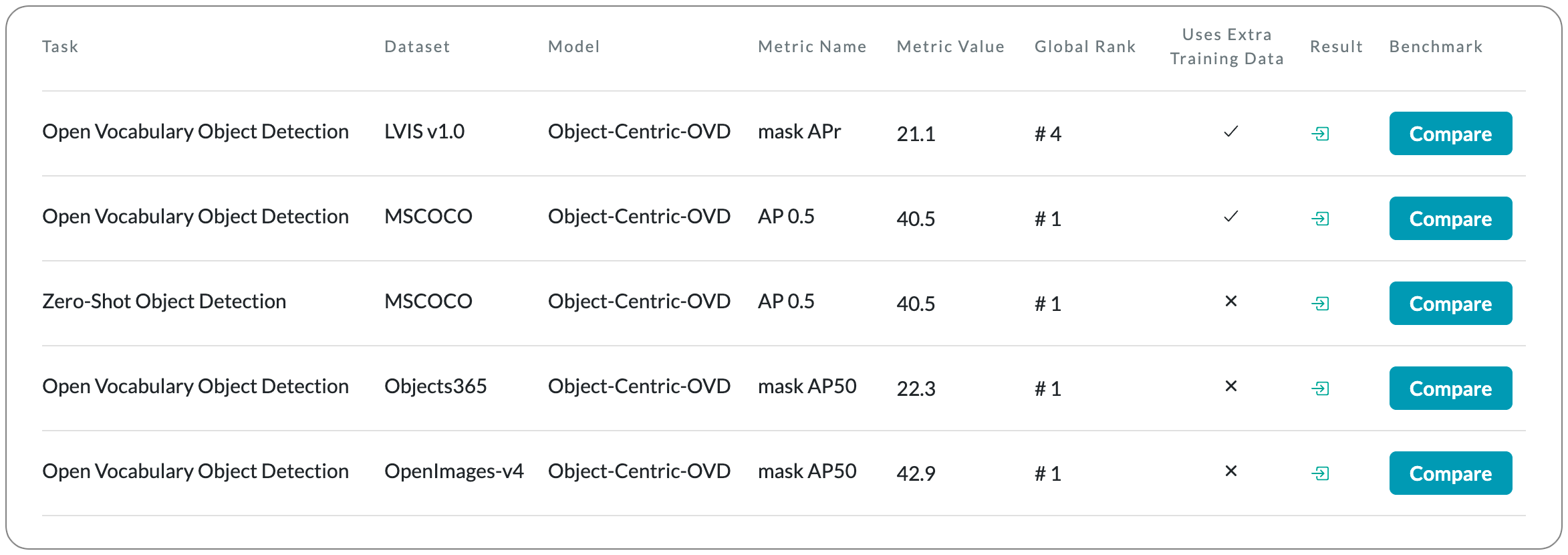
#1 in Open Vocabulary Object Detection on 3 datasets
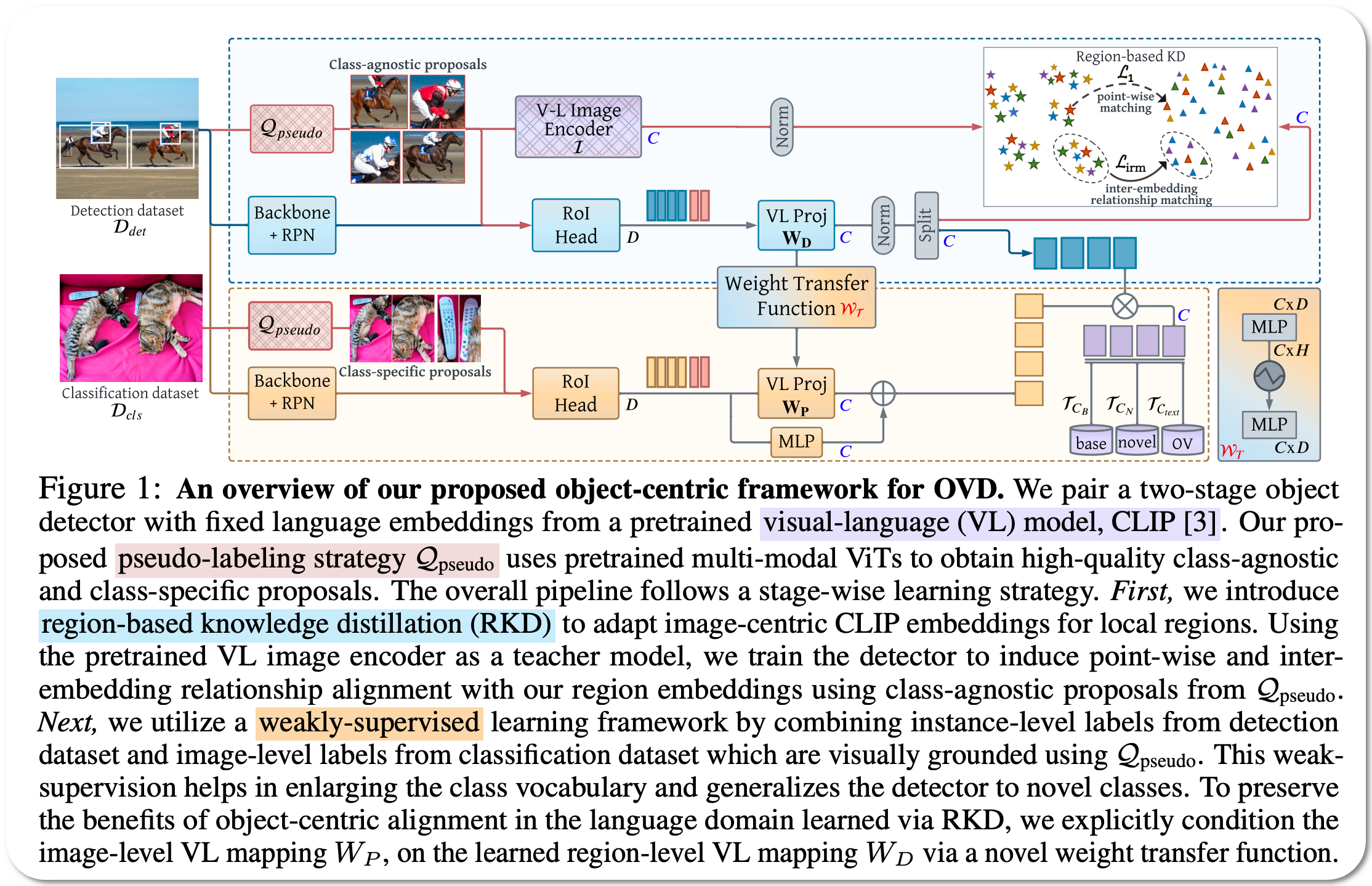

Model Name: Object-Centric-OVD
Notes: This paper aims to addresses the deficiency of open vocabulary detection using CLIP and weak supervision: - CLIP is trained with image-text pairs and lacks precise localization of objects while the image-level supervision has been used with heuristics that do not accurately specify local object regions. They address this problem by performing object-centric alignment of the language embeddings from the CLIP model. Also, they visually ground the objects with only image-level supervision using a pseudo-labeling process that provides high-quality object proposals and helps expand the vocabulary during training. They establish a bridge between the above two object-alignment strategies via a weight transfer function that aggregates their complimentary strengths. In essence, the proposed model seeks to minimize the gap between object and image-centric representations in the OVD setting.
Demo page link Hanoona graciously considered our suggestion to create a notebook showcasing her work. Thank you Hanoona. While the SOTA model is listed as an open domain object detection task, it performs instance segmentation - i.e. both delineating objects with class label assignment. The model performs quite well in the examples we tried below. Even in cases when its predictions do not agree with the ground truth, the predictions fall in the same "visual semantic class" as the ground truth class.
We can choose from two vocabularies or add our own words to a custom vocabulary and have the model recognize objects present in our vocabulary.

License: Apache-2.0 license
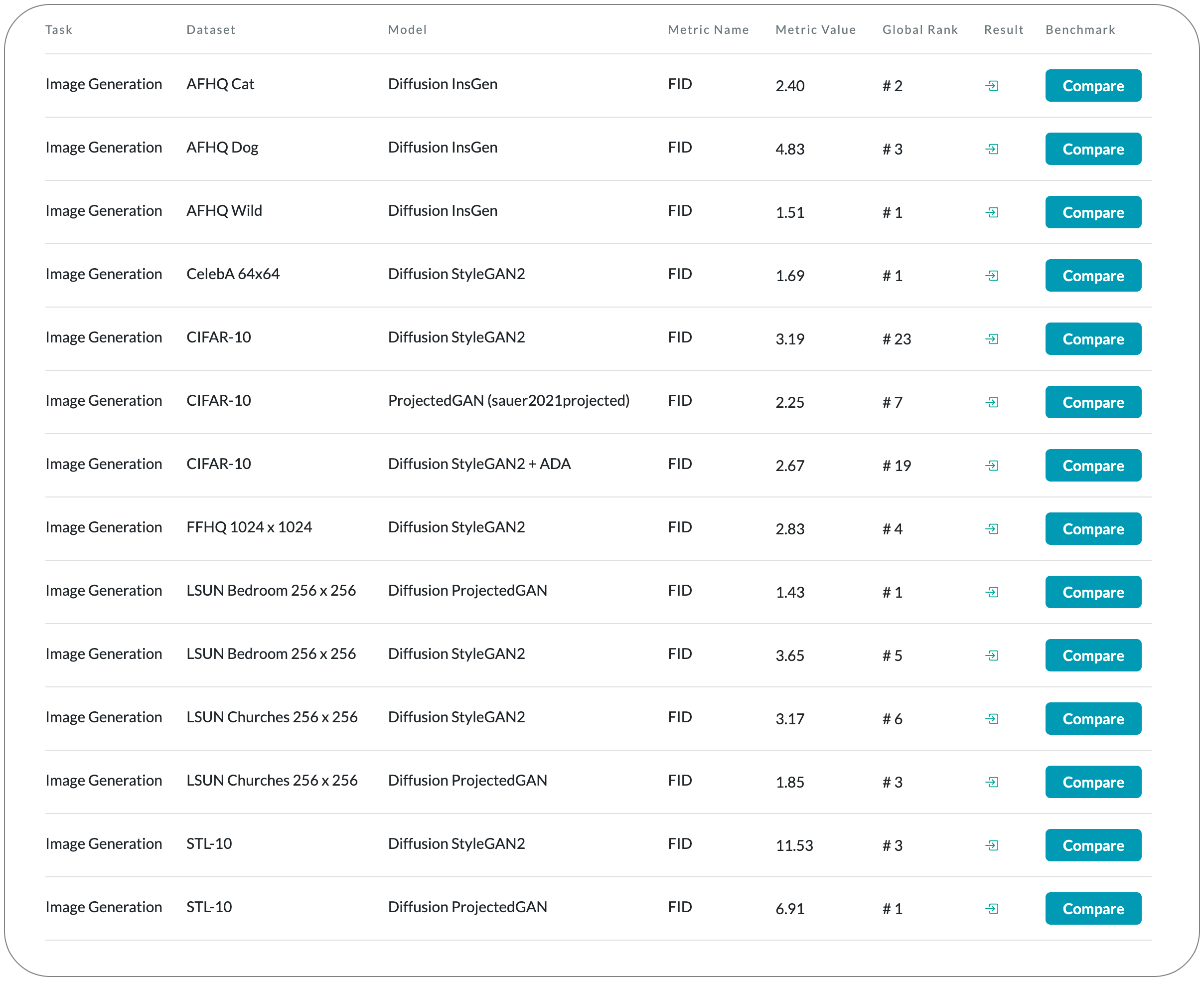
#1 in Image Generation on CelebA 64x64
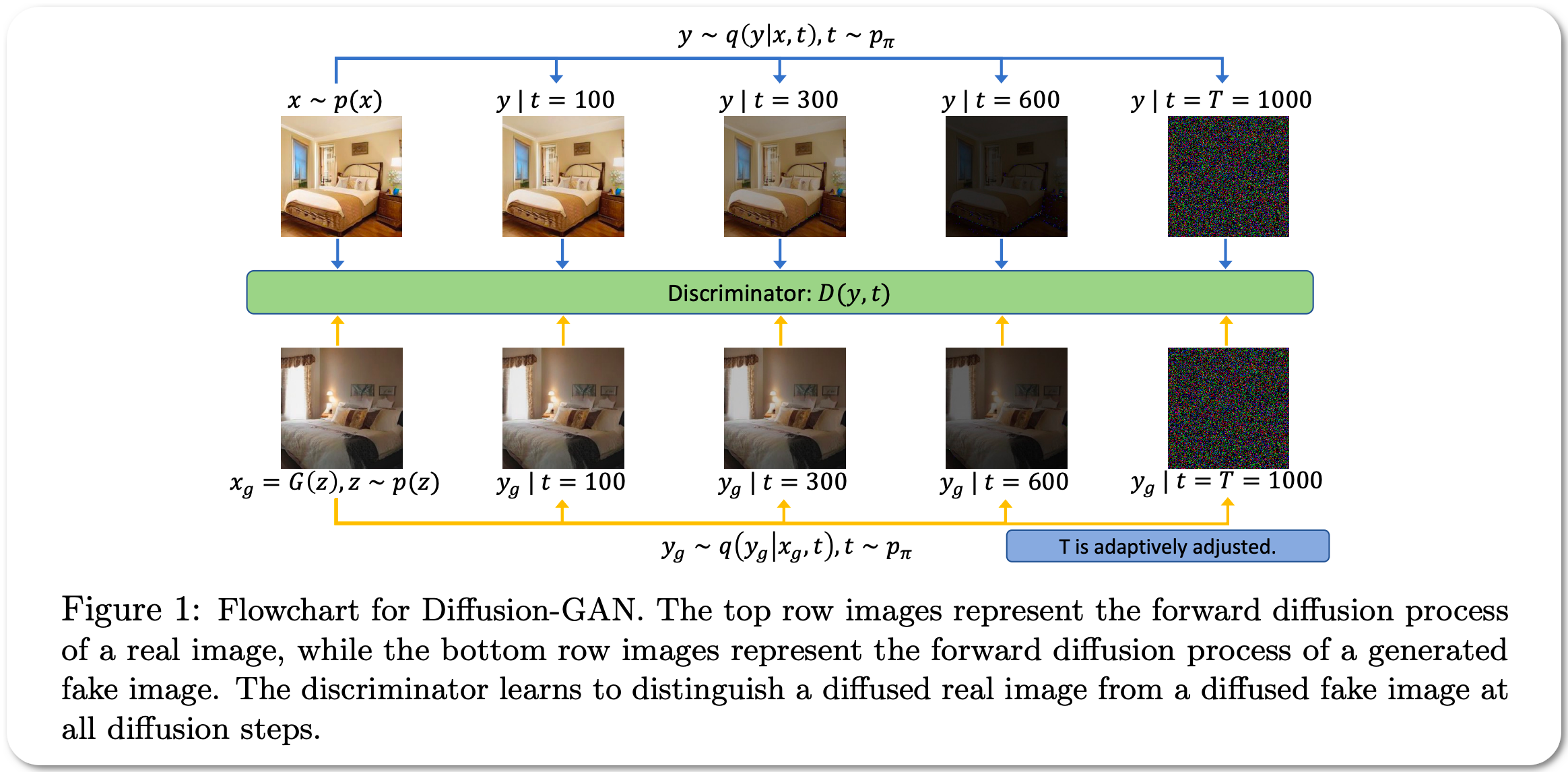

Model Name: Diffusion StyleGAN2
Notes: This paper proposes a GAN framework that leverages a forward diffusion chain to generate Gaussian-mixture distributed instance noise (injecting instance noise into the discriminator input has not been very effective in practice, to address the training stability problem). This approach consists of three components, including an adaptive diffusion process, a diffusion timestep-dependent discriminator, and a generator. Both the observed and generated data are diffused by the same adaptive diffusion process. At each diffusion timestep, there is a different noise-to-data ratio and the timestep-dependent discriminator learns to distinguish the diffused real data from the diffused generated data. The generator learns from the discriminator's feedback by backpropagating through the forward diffusion chain, whose length is adaptively adjusted to balance the noise and data levels.
Demo page link None to date
License: MIT license
#1 in Prompt engineering on 5 dataset families
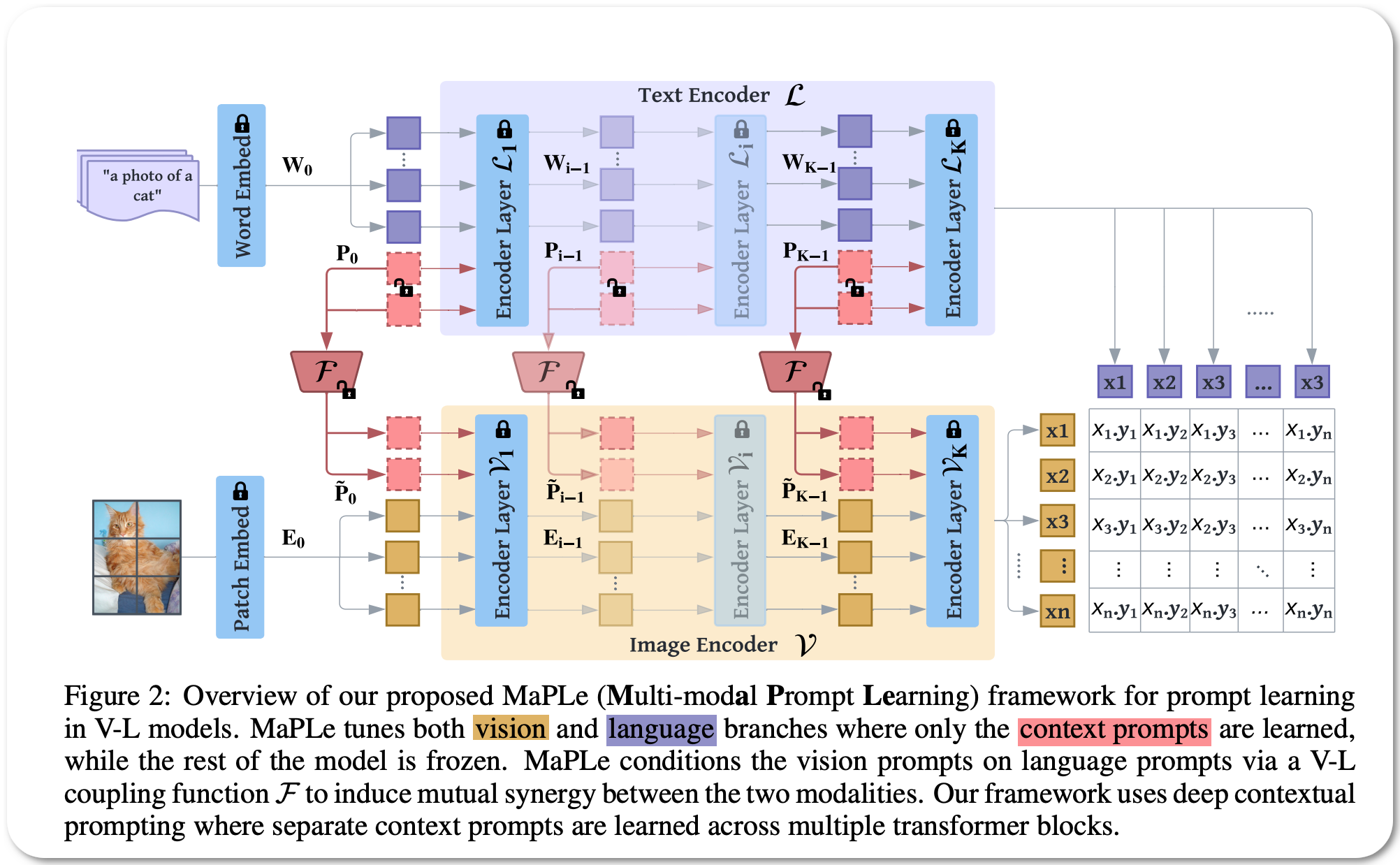
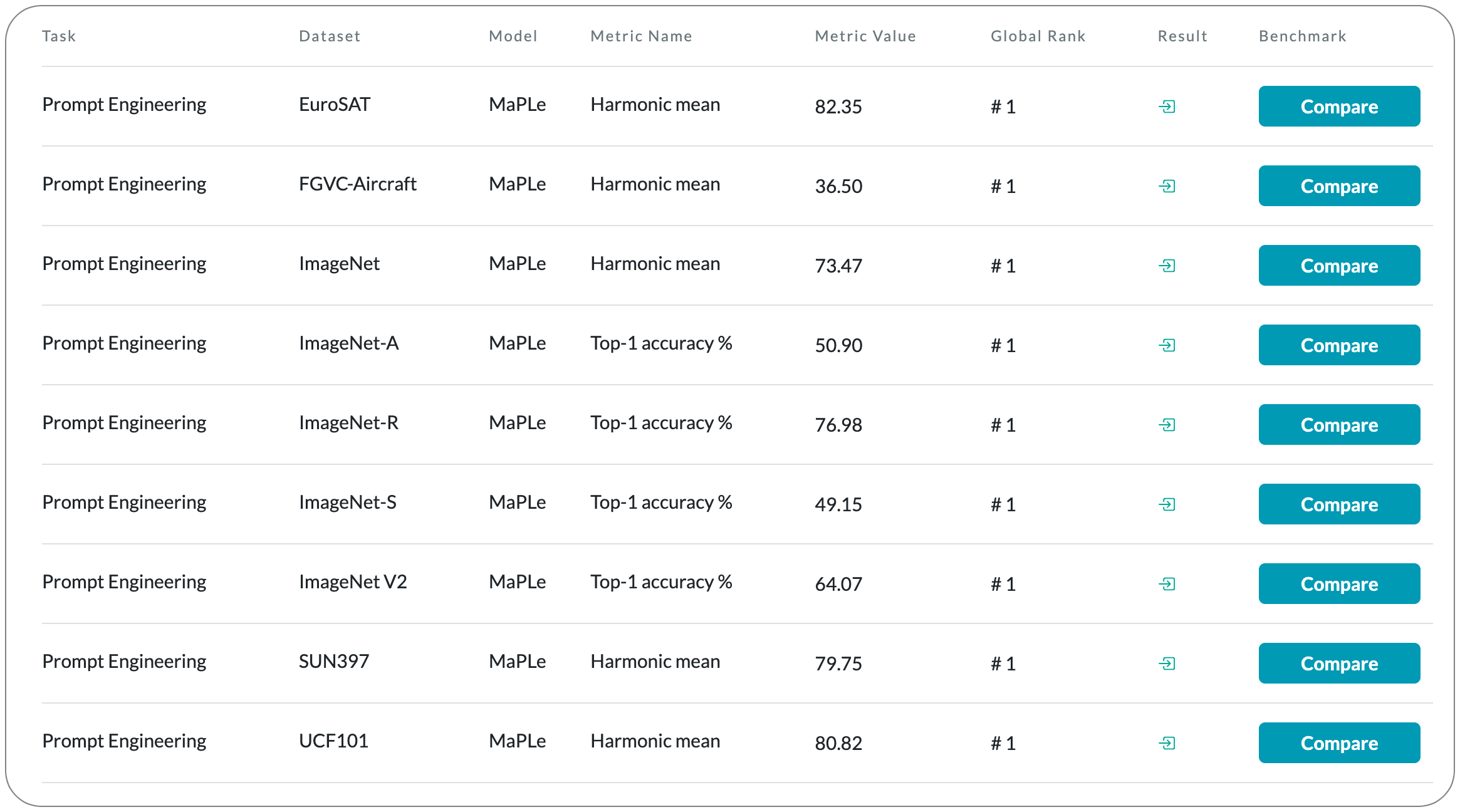

Model Name: MaPLe
Notes: Pre-trained vision-language (V-L) models such as CLIP have shown excellent generalization ability to downstream tasks. However, they are sensitive to the choice of input text prompts and require careful selection of prompt templates to perform well. Inspired by the Natural Language Processing (NLP) literature, recent CLIP adaptation approaches learn prompts as the textual inputs to fine-tune CLIP for downstream tasks. We note that using prompting to adapt representations in a single branch of CLIP (language or vision) is sub-optimal since it does not allow the flexibility to dynamically adjust both representation spaces on a downstream task. This paper proposes Multi-modal Prompt Learning (MaPLe) for both vision and language branches to improve alignment between the vision and language representations. This design promotes strong coupling between the vision-language prompts to ensure mutual synergy and discourages learning independent uni-modal solutions. They learn separate prompts across different early stages to progressively model the stage-wise feature relationships to allow rich context learning.
Demo page link None to date
License: MIT license
#1 in Semantic Textual Similarity on 2 dataset families
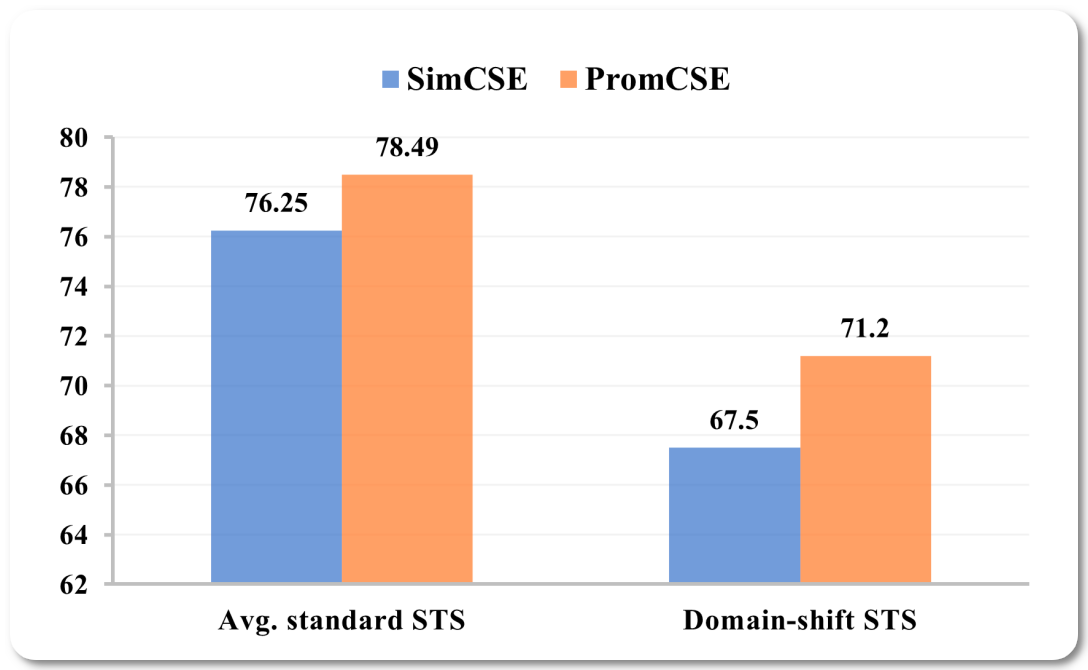
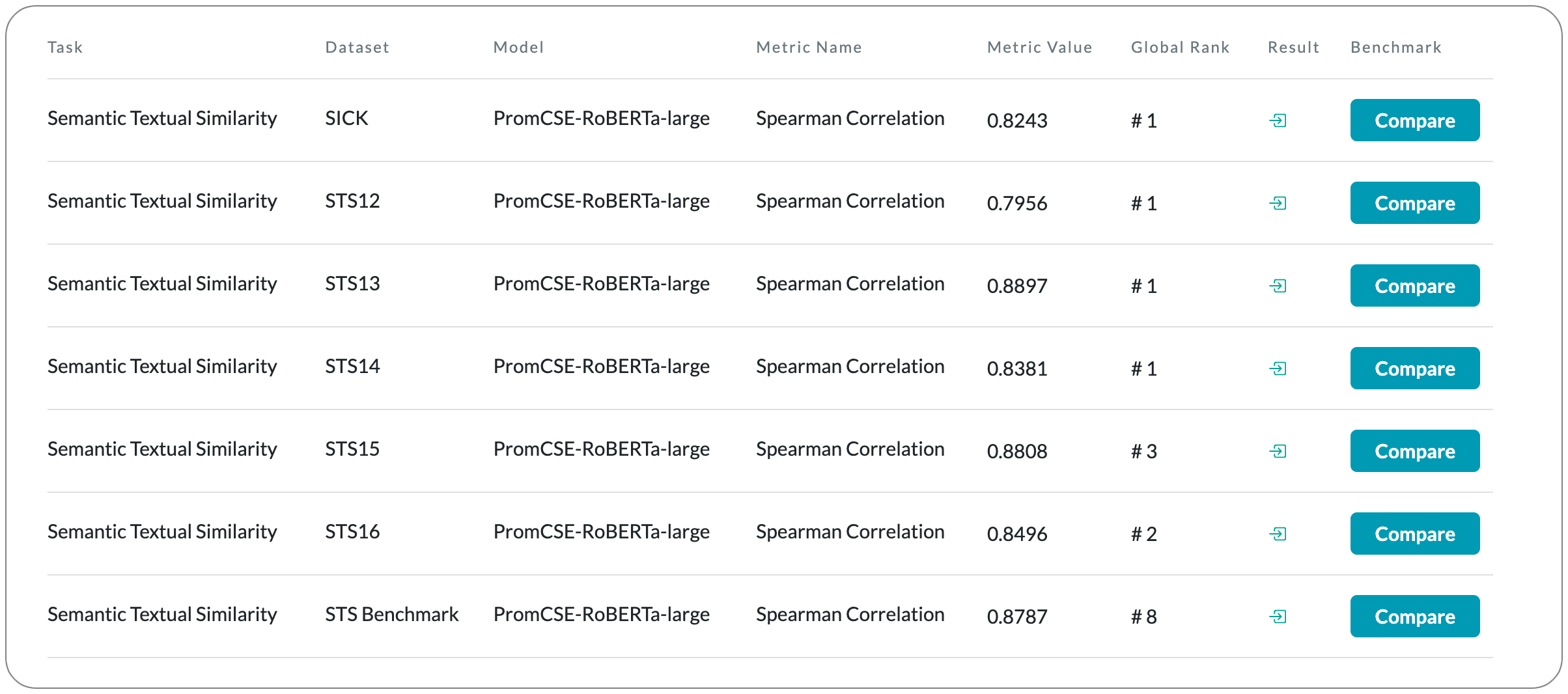

Model Name: PromCSE-RoBERTa-large
Notes: This paper proposes to address the limitations of learning sentence embeddings using contrastive methods - (1) poor performance under domain shift settings and (2) the fact that the loss function of contrastive learning does not fully exploit hard negatives in supervised learning settings. To alleviate the first limitation, they only train at a small-scale while keeping PLMs fixed. For the second limitation, they propose to integrate an energy-based hinge loss to enhance the pairwise discriminative power.
Demo page link None to date
License: License not specified but this code is based on one codebase that is covered by MIT license and another based on Apache-2.0 license, both of which allow commercial use if compliant with the license.
#1 in Video Quality Assessment on 2 datasets

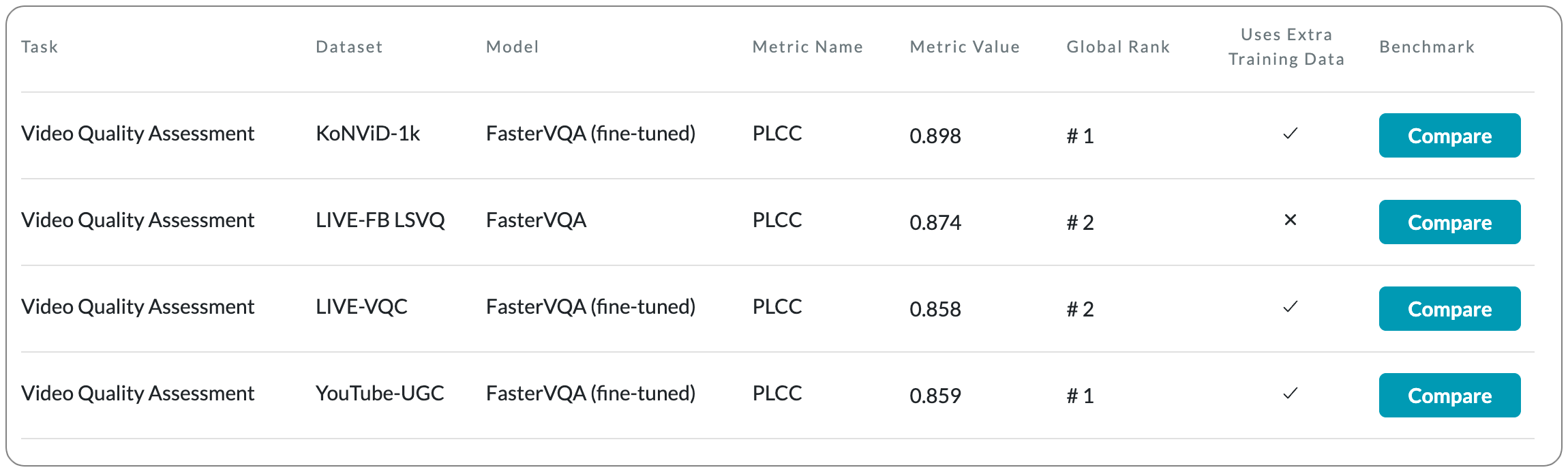

Model Name: FasterVQA
Notes: This paper proposes a scheme - spatial-temporal grid mini-cube sampling (St-GMS) to get a novel type of sample, named fragments. Full-resolution videos are first divided into mini-cubes with preset spatial-temporal grids, then the temporal-aligned quality representatives are sampled to compose the fragments that serve as inputs for VQA. In addition, they propose a Fragment Attention Network (FANet), a network architecture tailored specifically for fragments.
Demo page link None to date. There is a script on Github page to test any video input
License: Apache-2.0 license