TWC #10
State-of-the-art (SOTA) updates for 3 Oct– 9 Oct 2022
TasksWithCode weekly newsletter highlights the work of researchers who publish their code (often with models) along with their SOTA paper. This weekly is a consolidation of daily twitter posts tracking SOTA changes.
To date, 27 % (87,114) of total papers (322,182) published have code released along with the papers (source)
The selected researchers in figure above produced state-of-the-art work breaking existing records on benchmarks. They also
- authored their paper
- released their code
- released models in most cases
- released notebooks/apps in few cases
They broke existing records on the following tasks
- Link Prediction
- Generalized few-shot image Classification
- Few shot image classification
- Video Object Tracking
- 3D Instance Segmentation
- Temporal Action Proposal Generation
#1 in Link Prediction on YAGO3-10 dataset
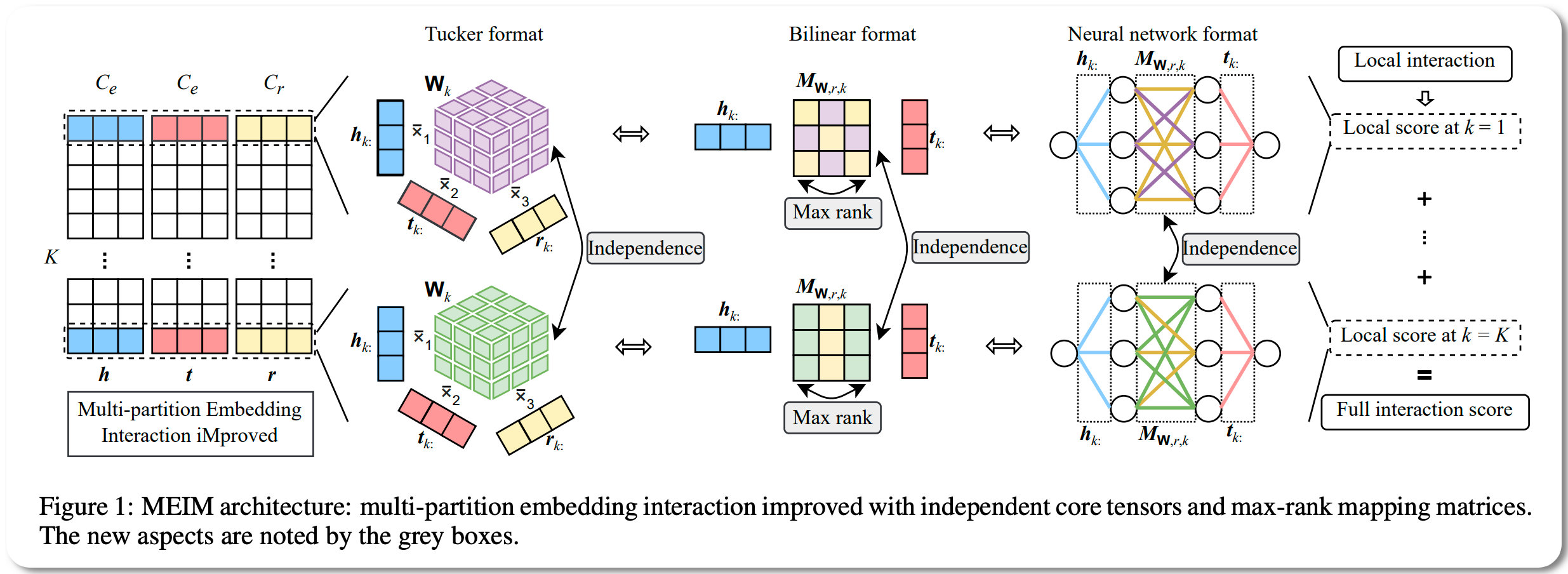
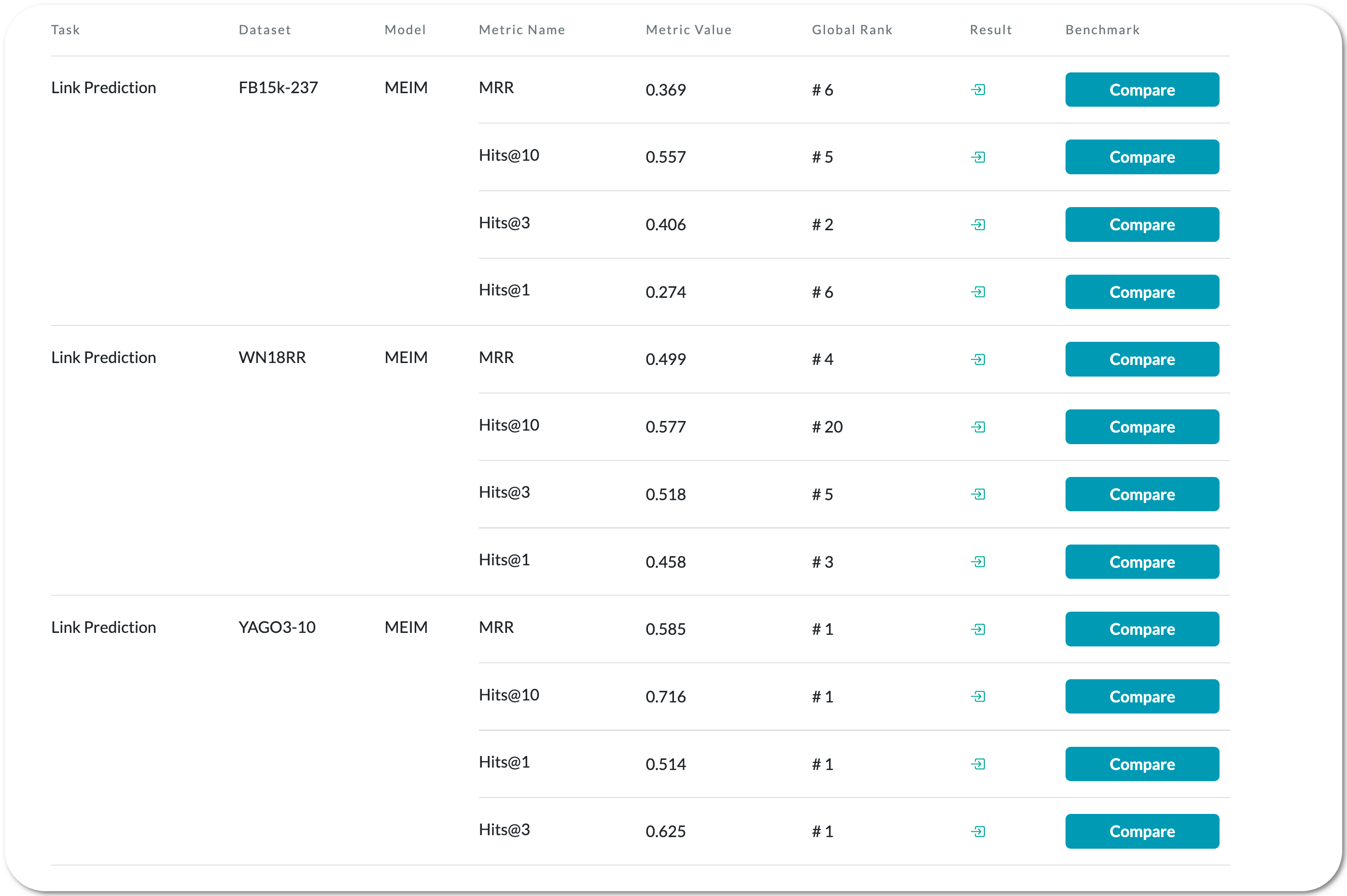

Model Name: MEIM
Notes: This is a knowledge graph embedding model to predict the missing relations between entities in knowledge graphs. The model proposed in this paper addresses some of the drawbacks of prior models and claims to be more expressive and efficient. It outperform strong baselines and achieve state-of-the-art results on difficult link prediction benchmarks using fairly small embedding sizes
Demo page link None to date
License: None to date
#1 in Generalized few-shot image Classification
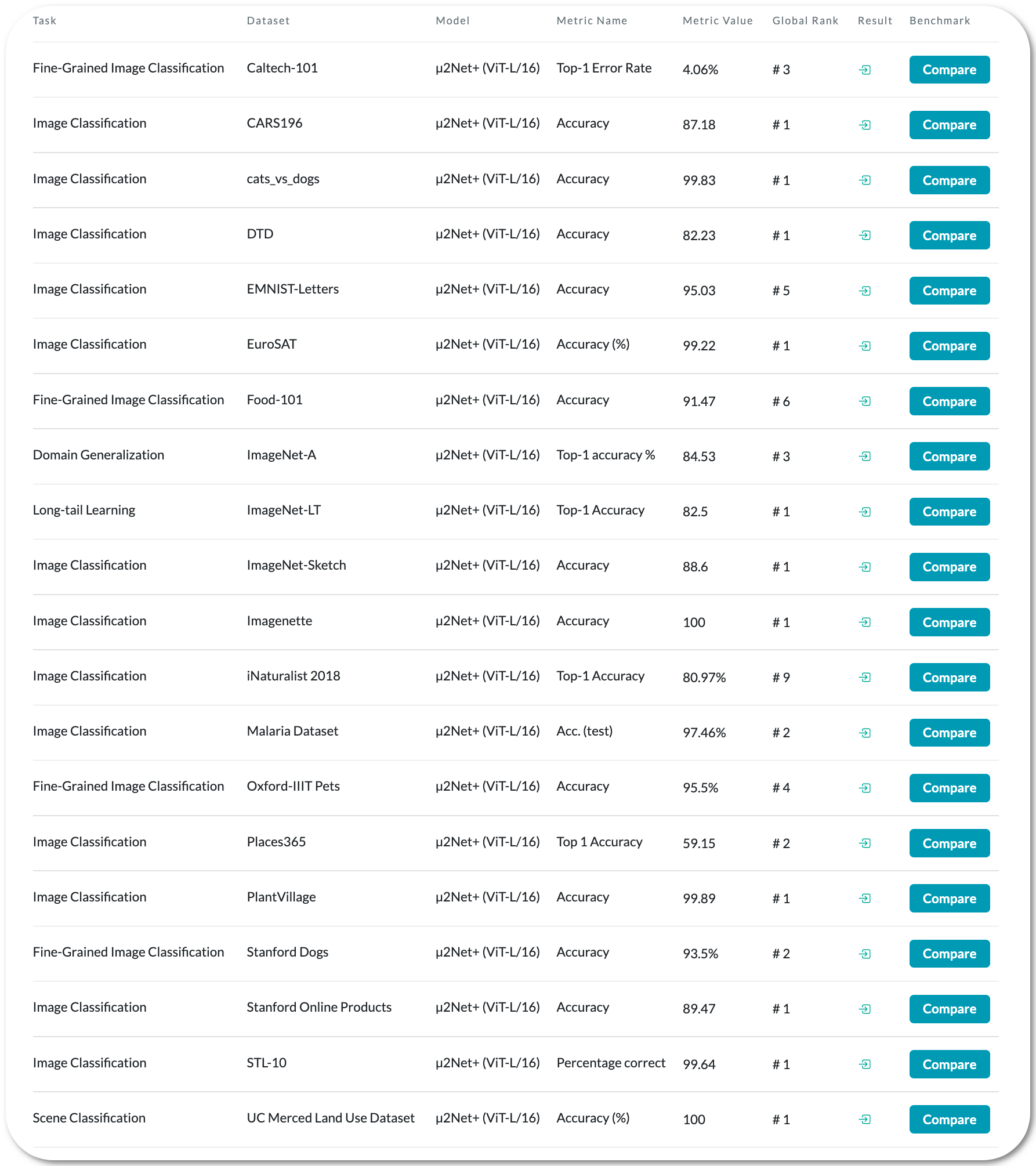

Model Name: µ2Net+ & µ2Net
Notes: This paper proposes a method for the generation of dynamic multitask ML models as a sequence of extensions and generalizations. They first analyze the capabilities of the proposed method by using the standard ML empirical evaluation methodology. They then propose a novel continuous development methodology that allows to dynamically extend a pre-existing multitask large-scale ML system while analyzing the properties of the proposed method extensions. This results in the generation of an ML model capable of jointly solving 124 image classification tasks achieving state of the art quality with improved size and compute cost.
Demo page link Multiple Colab notebook links available on Github page
License: Colab notebooks mention Apache 2.0 license
#1 in Few-Shot Image Classification on Mini and Tiered Imagenet datasets
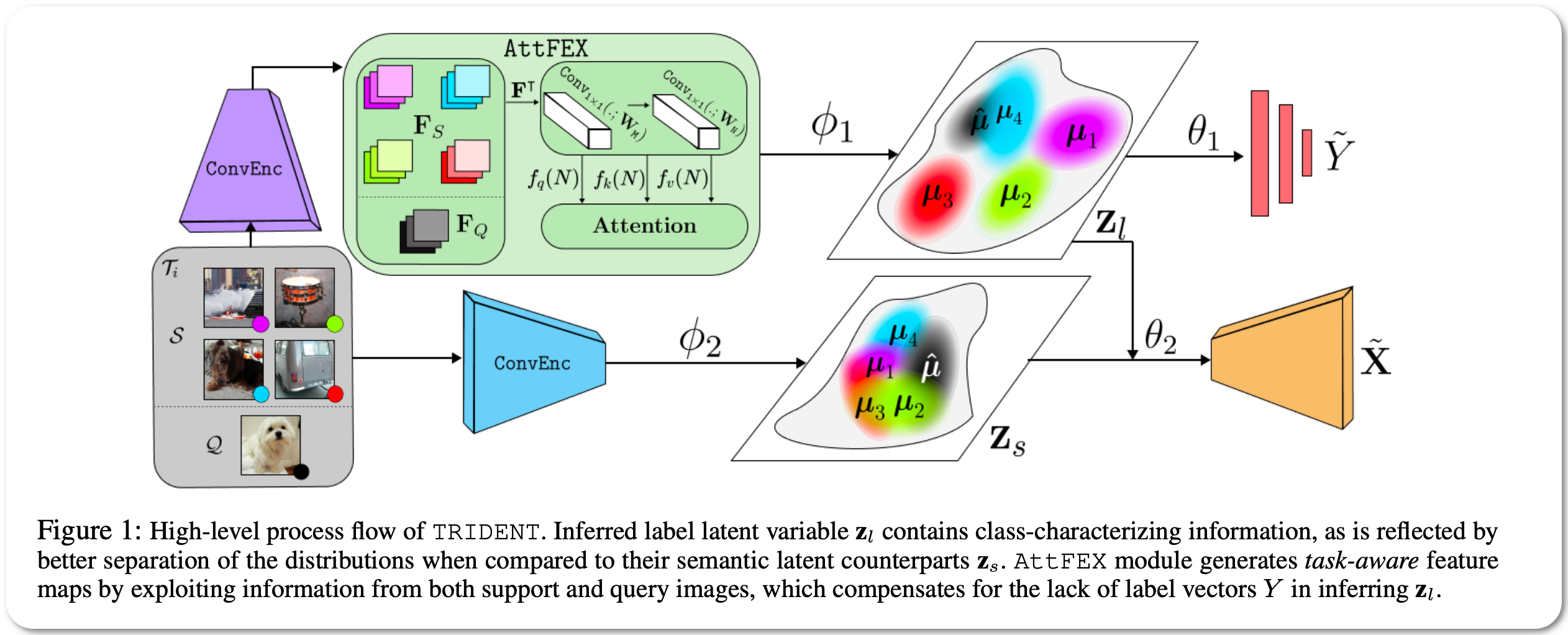
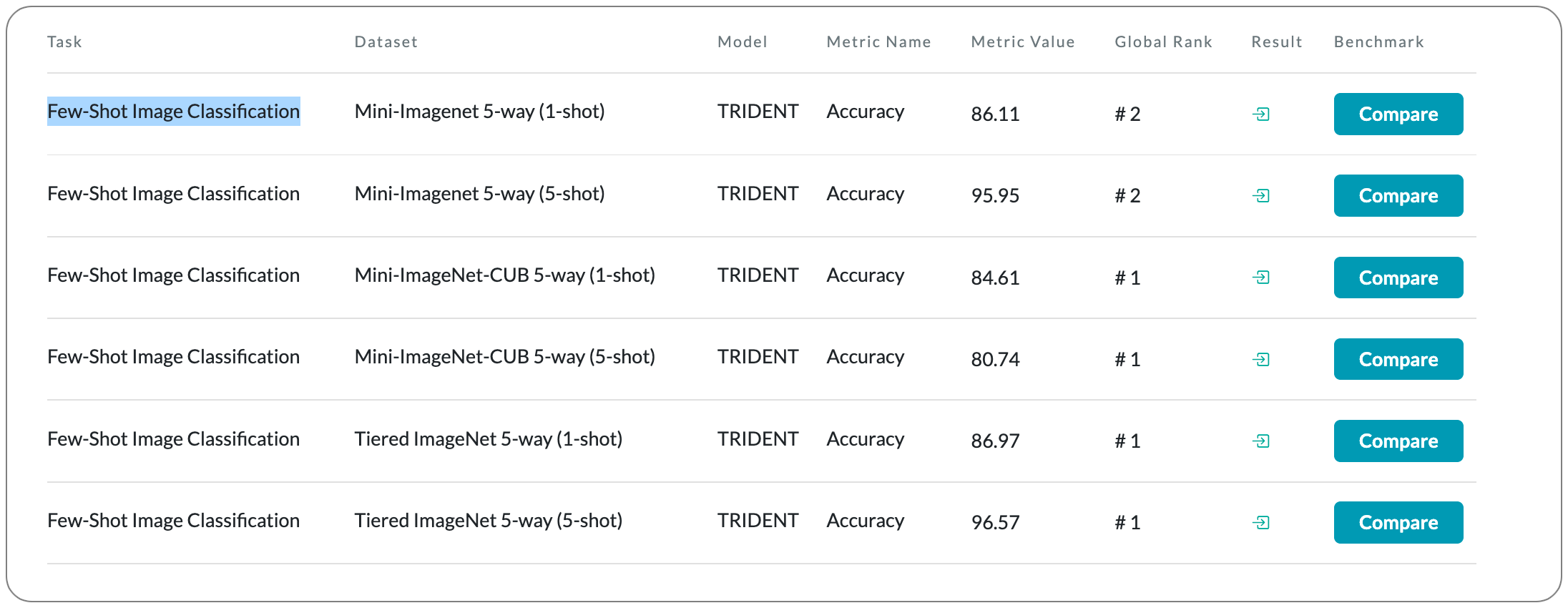

Model Name: TRIDENT
Notes: This paper proposes a novel variational inference network for few-shot classification to decouple the representation of an image into semantic and label latent variables, and simultaneously infer them in an intertwined fashion. To induce task-awareness, as part of the inference mechanics of the model, they exploit information across both query and support images of a few-shot task using a built-in attention-based transductive feature extraction module
Demo page link None to date
License: MIT license
#1 in Video Object Tracking
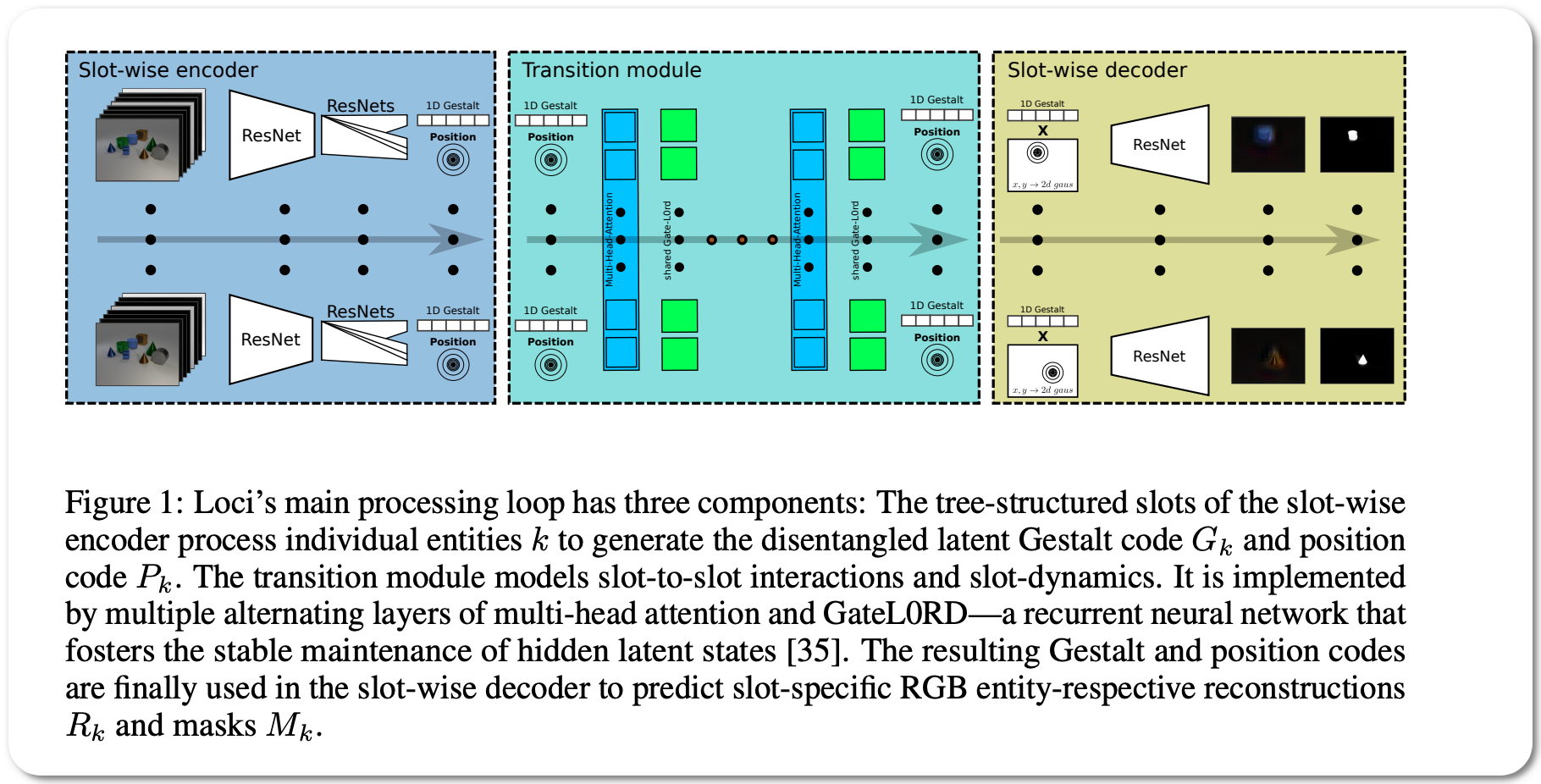
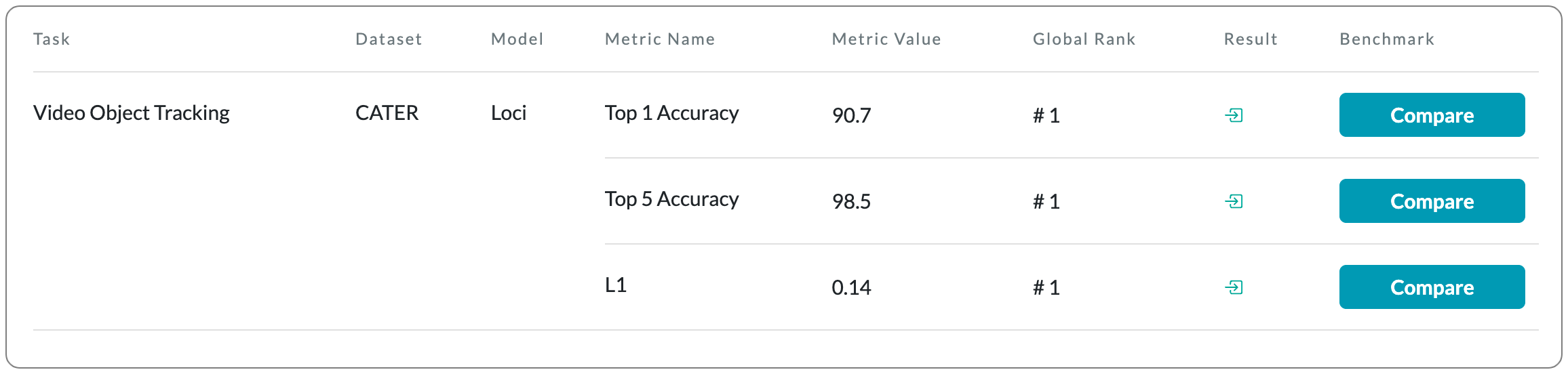

Model Name: Loci
Notes: This paper introduces a self-supervised LOCation and Identity tracking system (Loci). Inspired by the dorsal-ventral pathways in the brain, Loci addresses the binding problem by processing separate, slot-wise encodings of 'what' and 'where'. Loci's predictive coding-like processing encourages active error minimization, such that individual slots tend to encode individual objects. Interactions between objects and object dynamics are processed in the disentangled latent space. Truncated backpropagation through time combined with forward eligibility accumulation significantly speeds up learning and improves memory efficiency. Loci effectively extracts objects from video streams and separates them into location and Gestalt components (an organized whole that is perceived as more than the sum of its parts). This separation offers an encoding that could facilitate effective planning and reasoning on conceptual levels.
Demo page link An interface to explore learned latent representations also released
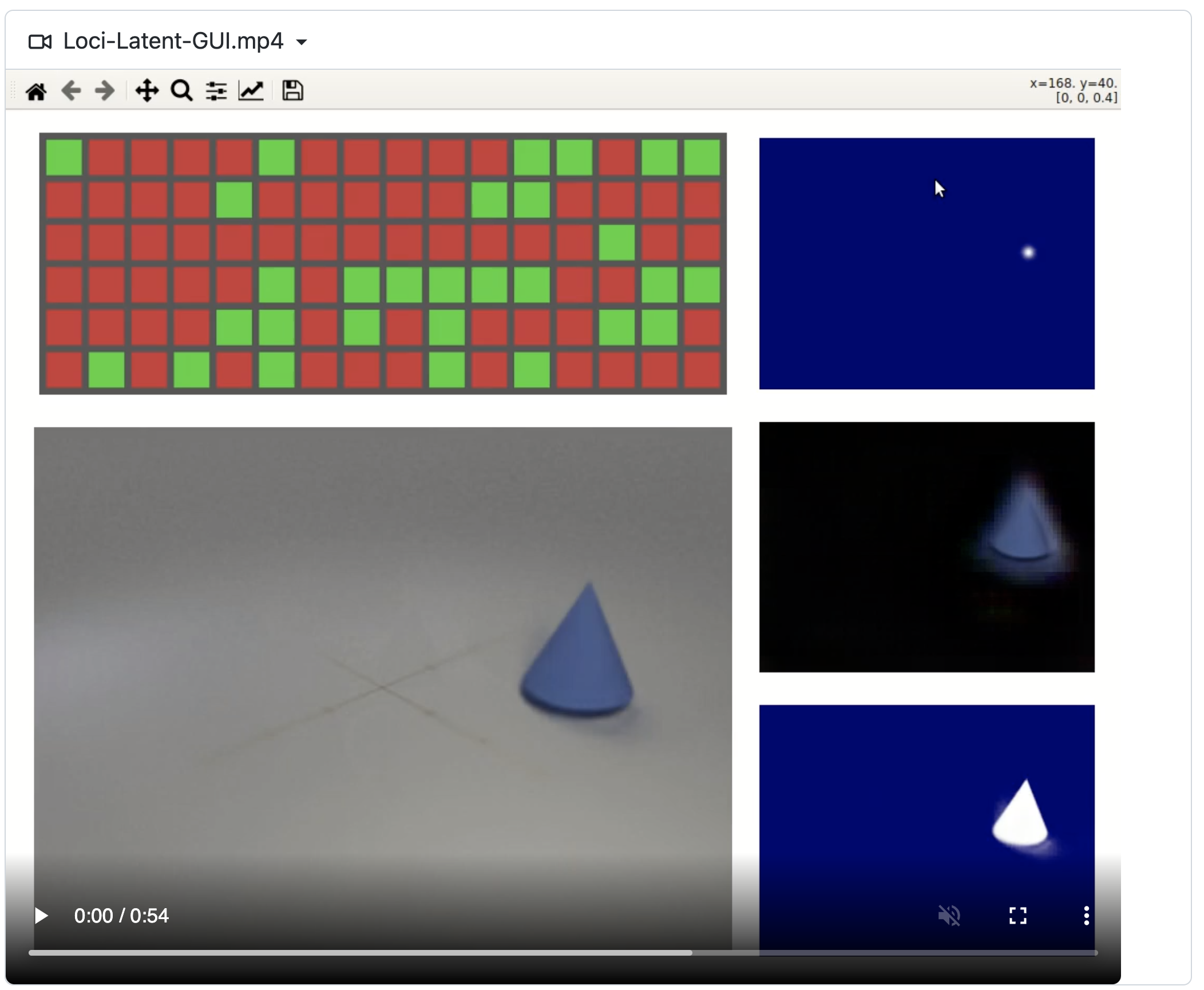
License: MIT license
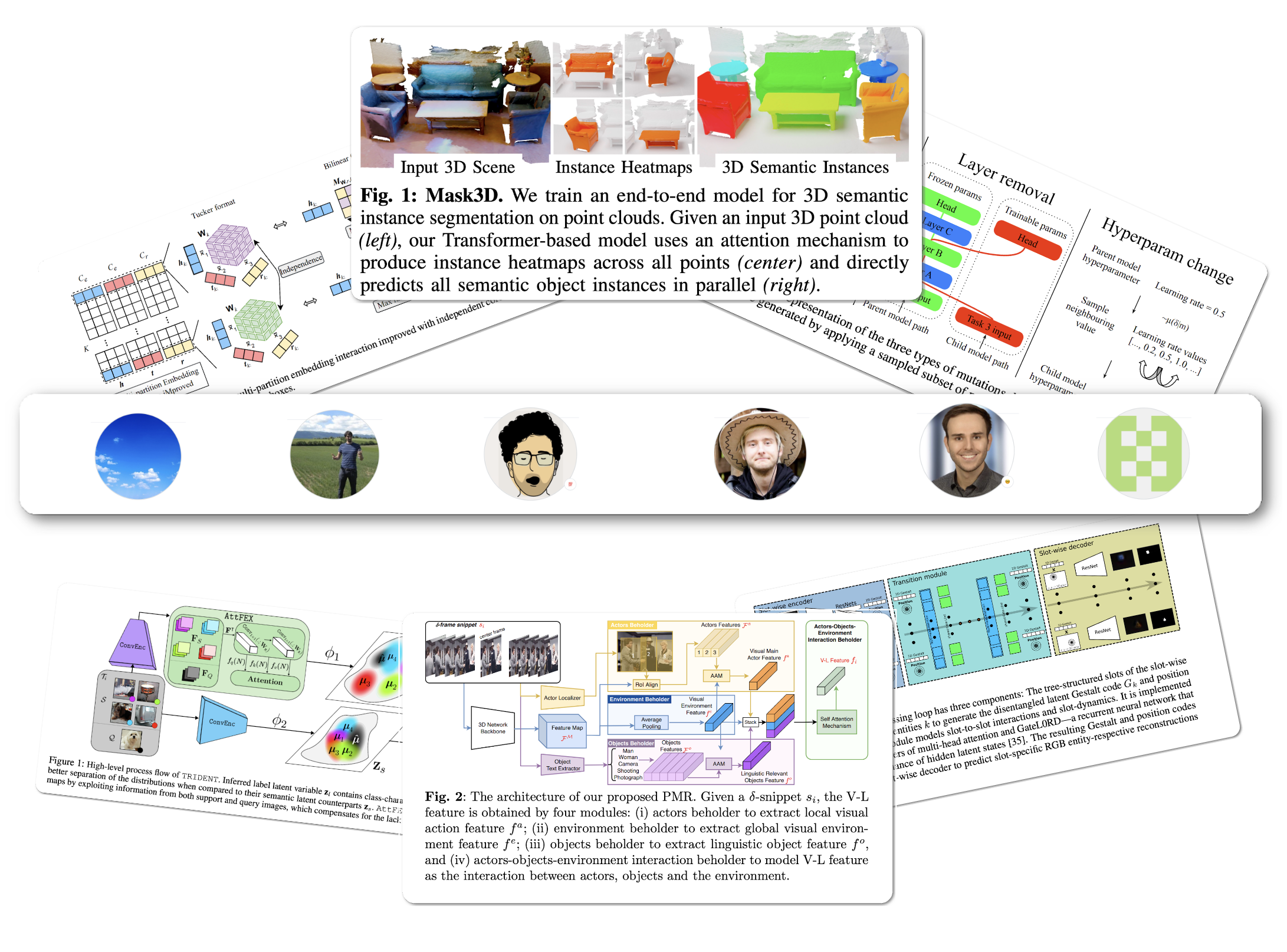
#1 in 3D Instance Segmentation
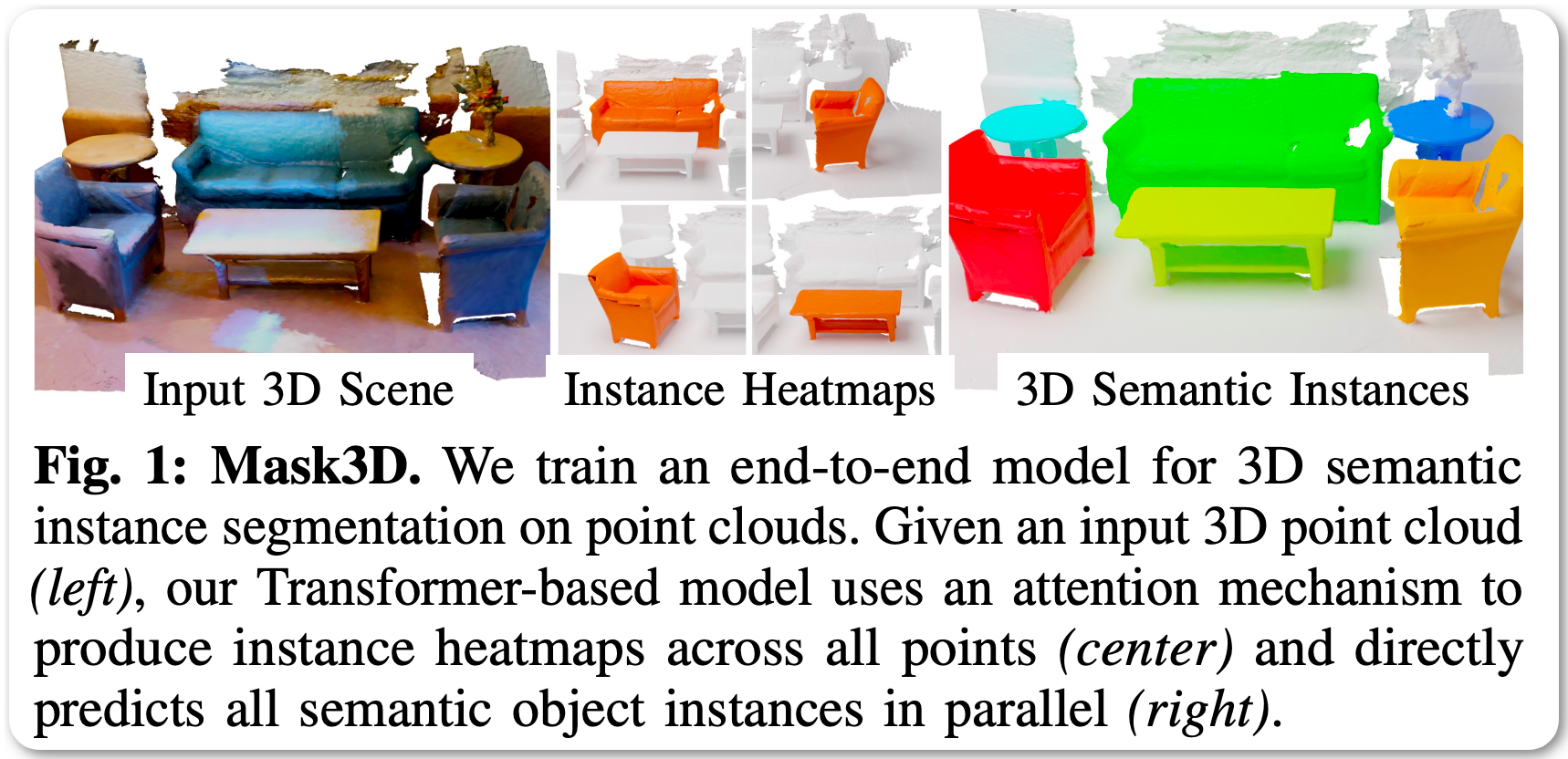
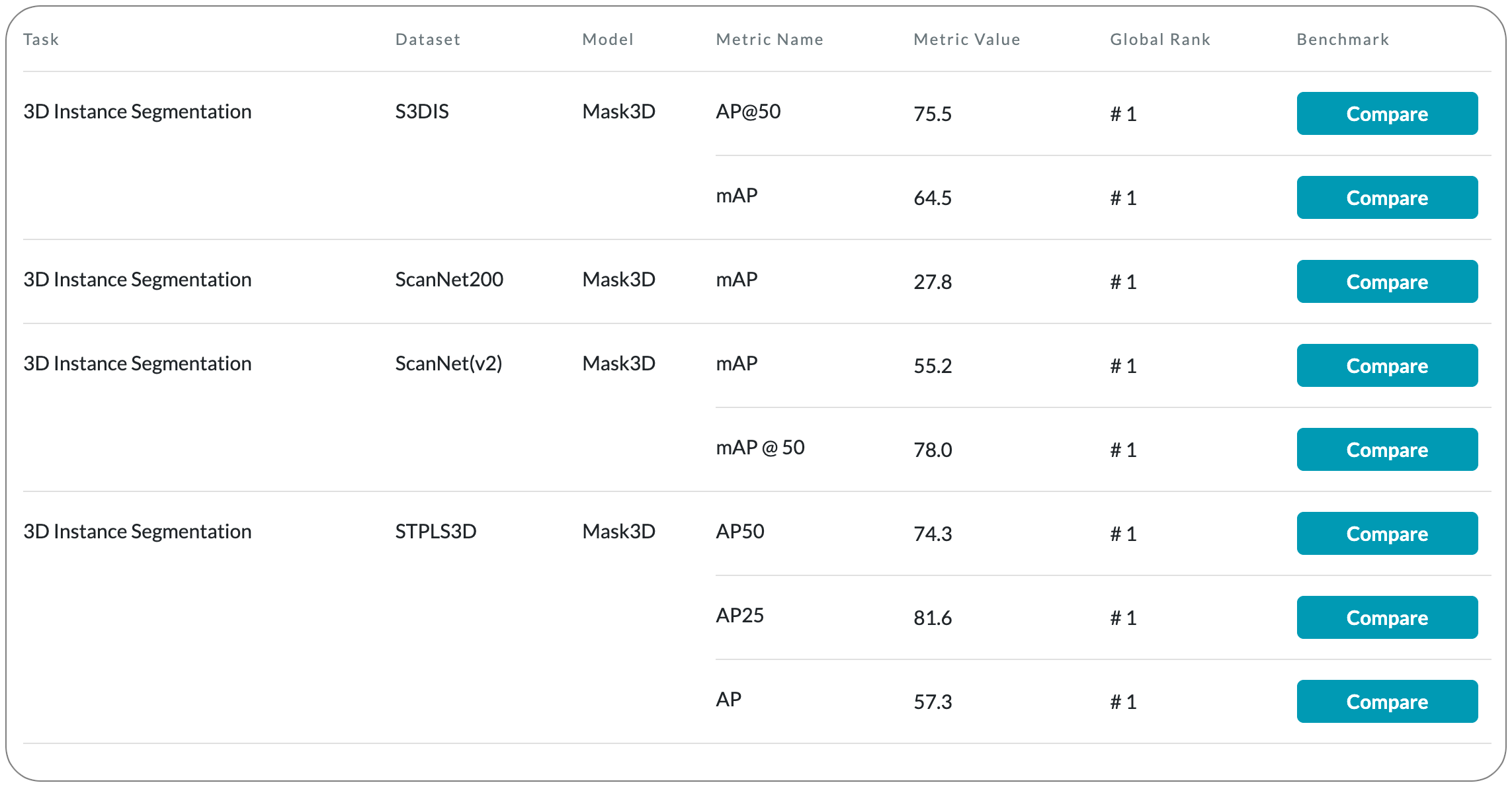

Model Name: Mask3D
Notes: This paper proposes the first Transformer-based approach for 3D semantic instance segmentation. They leverage generic transformer building blocks to directly predict instance masks from 3D point clouds. Each object instance is represented as an instance query. Using transformer decoders, the instance queries are learned by iteratively attending to point cloud features at multiple scales. Combined with point features, the instance queries directly yield all instance masks in parallel. The model, Mask3D is claimed to have several advantages over current state-of-the-art approaches, since it neither relies on (1) voting schemes which require hand-selected geometric properties (such as centers) nor (2) geometric grouping mechanisms requiring manually-tuned hyper-parameters (e.g. radii) and (3) enables a loss that directly optimizes instance masks.
Demo page link The demo page allows users to upload a 3D scan using a hardware (iPad Pro & iPhone 12 Pro LIDAR Scanning) capable iPhone/iPad and see the segmentation.
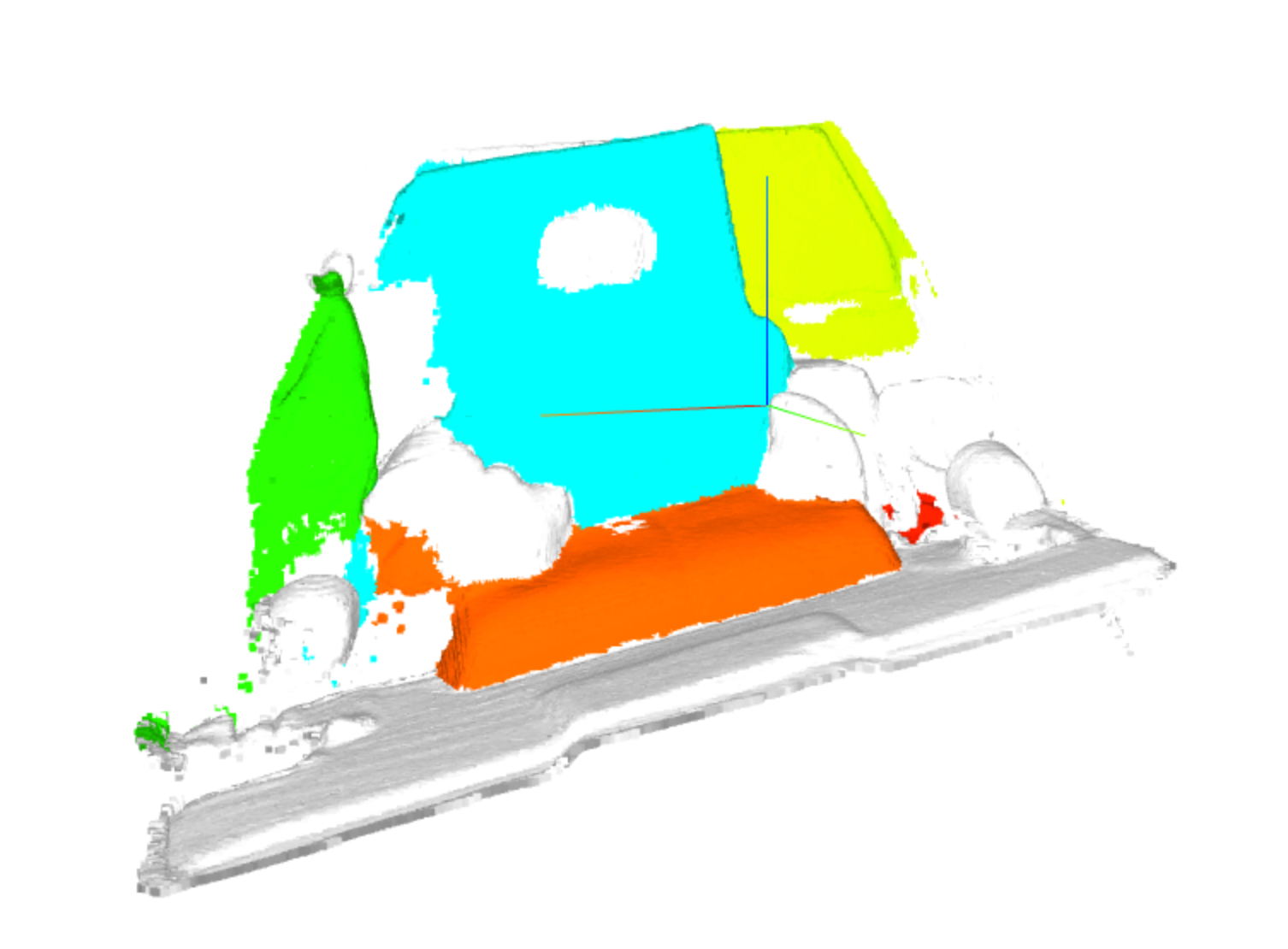
License: None specified to date
#1 in Temporal Action Proposal Generation
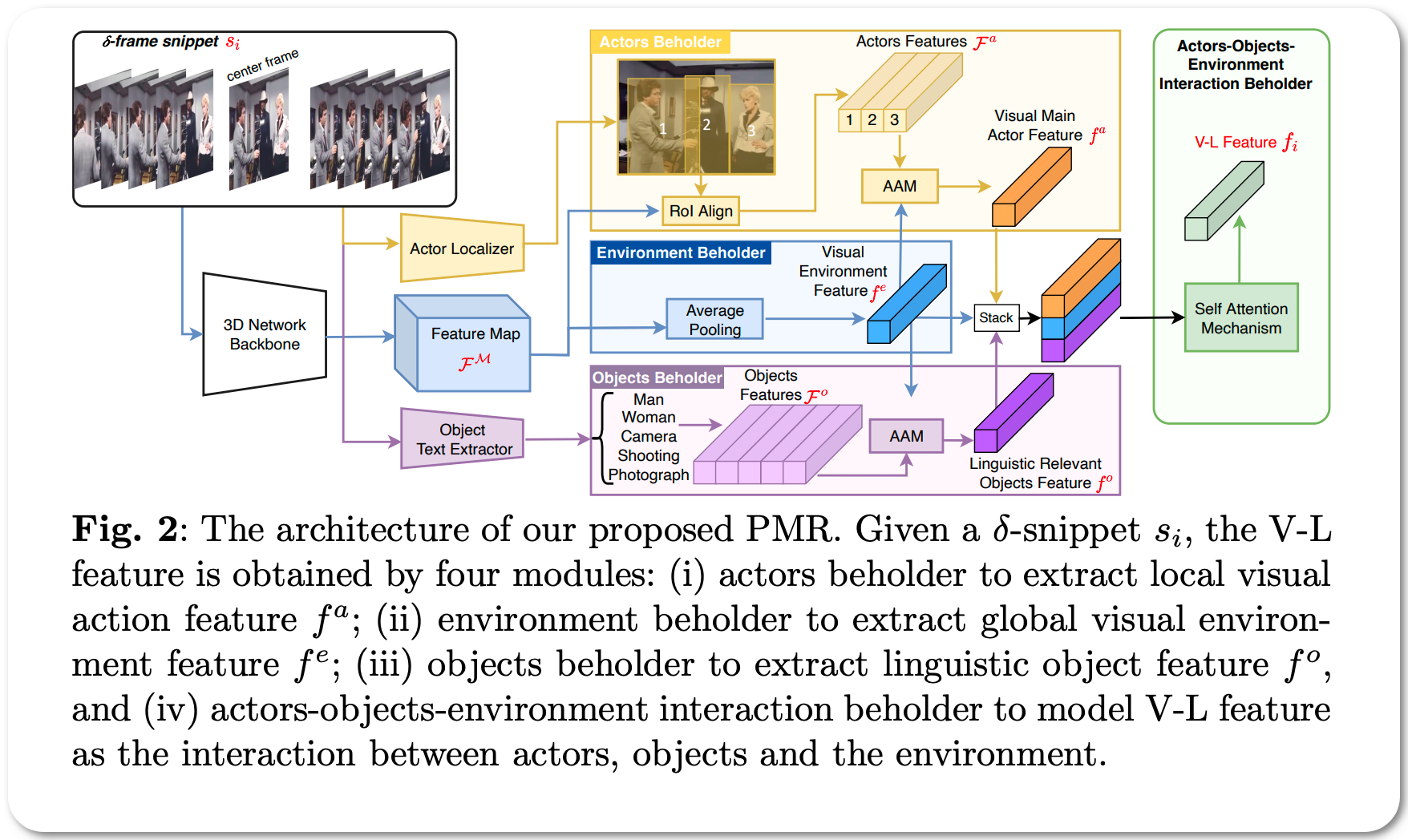
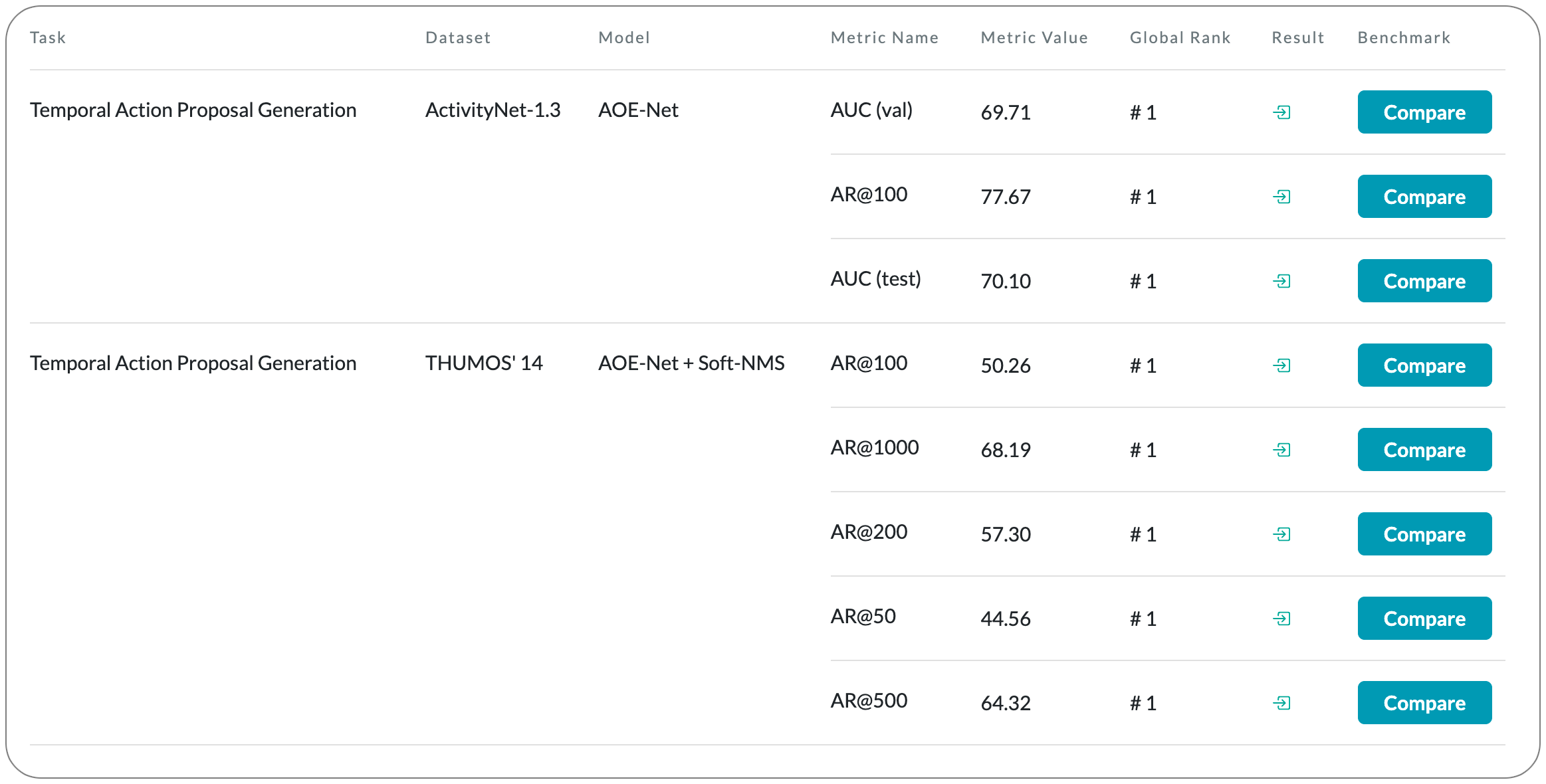

Model Name: AOE-Net
Notes: Temporal action proposal generation (TAPG) requires localizing action intervals in an untrimmed video. Humans, perceive an action through the interactions between actors, relevant objects, and the surrounding environment. Despite the significant progress of TAPG, a vast majority of existing methods ignore the aforementioned principle of the human perceiving process by applying a backbone network into a given video as a black-box. This paper proposes to model these interactions with a multi-modal representation network, namely, Actors-Objects-Environment Interaction Network (AOE-Net). The proposed model consists of two modules, i.e., perception-based multi-modal representation (PMR) and boundary-matching module (BMM). Additionally, they introduce adaptive attention mechanism (AAM) in PMR to focus only on main actors (or relevant objects) and model the relationships among them. PMR module represents each video snippet by a visual-linguistic feature, in which main actors and surrounding environment are represented by visual information, whereas relevant objects are depicted by linguistic features through an image-text model. BMM module processes the sequence of visual-linguistic features as its input and generates action proposals.
Demo page link None to date
License: None to date